











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






标签平滑与深度学习
2020年01月01日 由 sunlei 发表
731593
0
来自Google Brain的Hinton、Muller和Cornblith发表了一篇题为“标签平滑何时有用”的新论文?深入研究标签平滑如何影响深层神经网络的最终激活层。他们建立了一种新的可视化方法来阐明标签平滑的内部效果,并提供了对其内部工作方式的新见解。虽然标签平滑经常被使用,但本文解释了标签平滑为什么和如何影响神经网络,以及何时、何时不使用标签平滑的宝贵见解。
[caption id="attachment_48916" align="alignnone" width="1716"]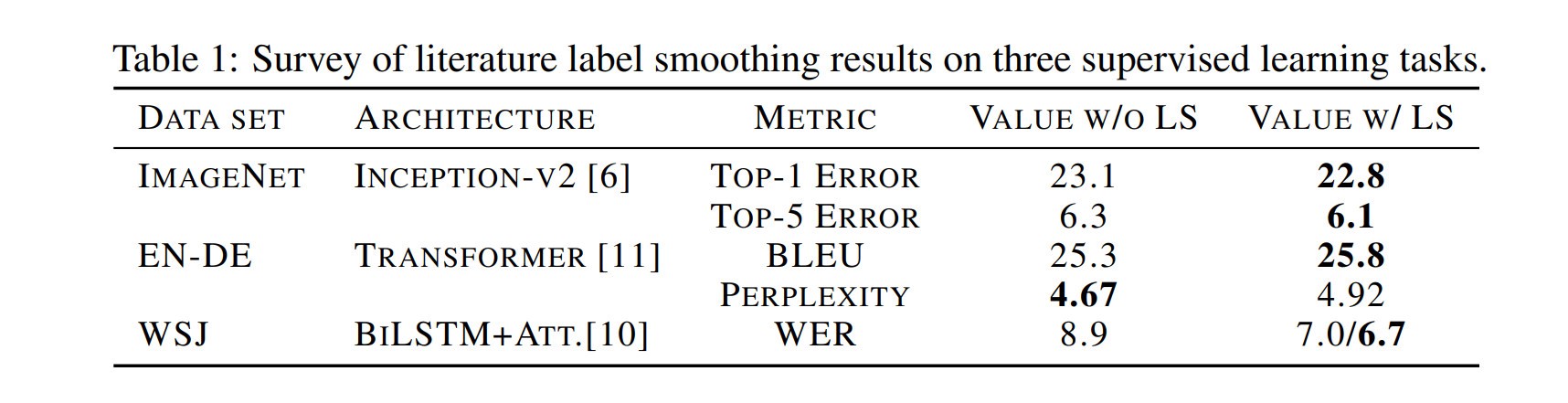 从纸张标签平滑提供了广泛的深度学习模型的改进。[/caption]
从纸张标签平滑提供了广泛的深度学习模型的改进。[/caption]
本文总结了本文的见解,帮助您快速利用这些发现进行自己的深入学习工作。建议对全文进行深入分析。
什么是标签平滑?标签平滑是一种损失函数修正,已被证明对训练深度学习网络非常有效。标签平滑提高了图像分类、翻译甚至语音识别的准确性。例如,我们的团队用它来打破许多FastAI排行榜记录:
[caption id="attachment_48917" align="aligncenter" width="1216"]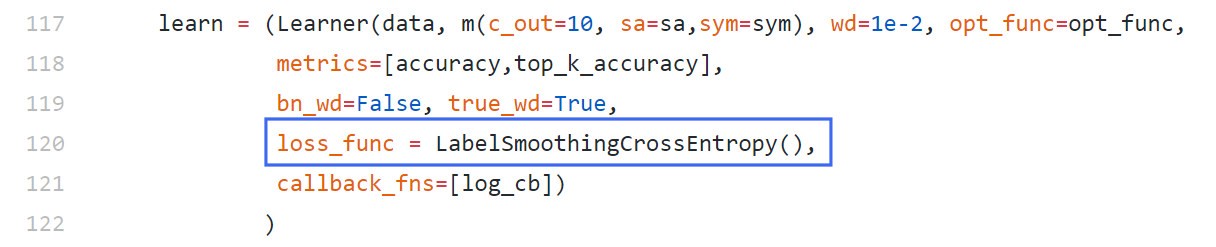 在FastAI训练代码中调用Labelsmoothing。[/caption]
在FastAI训练代码中调用Labelsmoothing。[/caption]
其工作原理的简单解释是,它将神经网络的训练目标从“1”调整为“1-label平滑调整”,这意味着神经网络被训练得对自己的答案不那么自信。默认值通常是.1,这意味着目标答案是.9(1 - 1)而不是1。
假设我们想把图像分为狗和猫。如果我们看到一张狗的照片,我们训练NN(通过交叉熵损失)朝着狗的1和猫的0移动。如果是猫,我们训练的方向相反,1代表猫,0代表狗。
然而,神经网络有一个坏习惯,就是在训练期间对自己的预测变得“过于自信”,这会降低他们概括的能力,从而在新的、看不见的未来数据上也会表现得很好。此外,大型数据集通常会包含错误标记的数据,这意味着神经网络本身应该对“正确答案”有点怀疑,以减少对某些错误答案的极端建模。
因此,标签平滑的作用是通过训练神经网络朝着“1-adjustment”目标移动,然后将调整量除以剩余的类,而不是简单的1,从而迫使神经网络对其答案缺乏信心。
对于我们的二进制dog/cat示例,标签平滑为.1意味着目标答案将是.90(90%置信度)这是一个dog For a dog图像,和.10(10%置信度)这是一个cat,而不是之前的1或0。由于不太确定,它充当了一种正则化的形式,提高了它在新数据上更好地执行的能力。
看到代码中的标签平滑可能有助于了解它如何比通常的数学(来自FastaiGithub)更好地工作。看起来像E(epsilon或ε)的希腊字母是标签平滑调整因素:
[caption id="attachment_48918" align="aligncenter" width="1701"] FastAI实现标签平滑[/caption]
FastAI实现标签平滑[/caption]
标签平滑对神经网络的影响:现在我们进入文章的核心部分,直观地展示了标签平滑对神经网络分类处理的影响。
首先,AlexNet在训练中对“飞机、汽车和鸟类”进行分类。
[caption id="attachment_48923" align="aligncenter" width="1002"]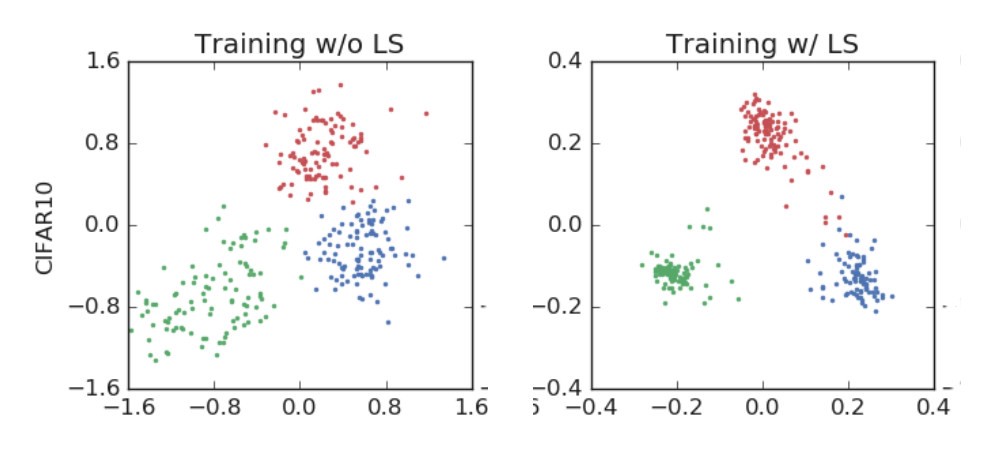 左-训练结果没有标签平滑。右-标签平滑训练。[/caption]
左-训练结果没有标签平滑。右-标签平滑训练。[/caption]
然后验证:
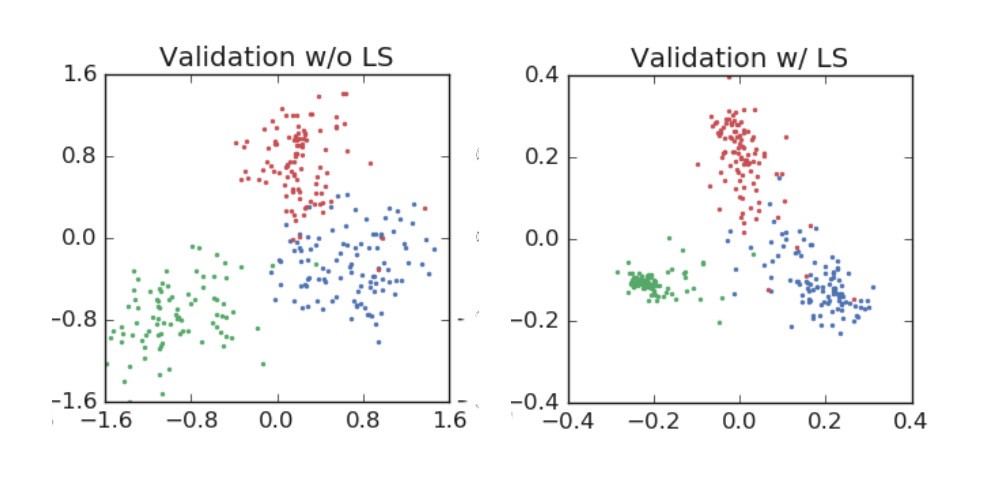 正如您所看到的,标签平滑强制对分类进行更紧密的分组,同时强制在集群之间进行更等距的间隔。
正如您所看到的,标签平滑强制对分类进行更紧密的分组,同时强制在集群之间进行更等距的间隔。
“海狸、海豚和水獭”的ResNet示例更加清晰:
[caption id="attachment_48932" align="aligncenter" width="994"]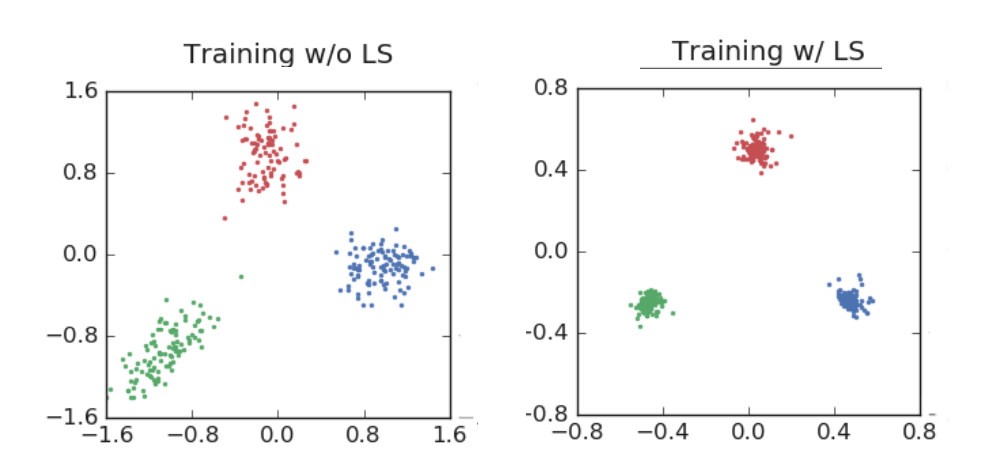 ResNet训练用于分类3个图像类别…请注意在集群紧密性方面的巨大差异。[/caption]
ResNet训练用于分类3个图像类别…请注意在集群紧密性方面的巨大差异。[/caption]
[caption id="attachment_48934" align="aligncenter" width="946"]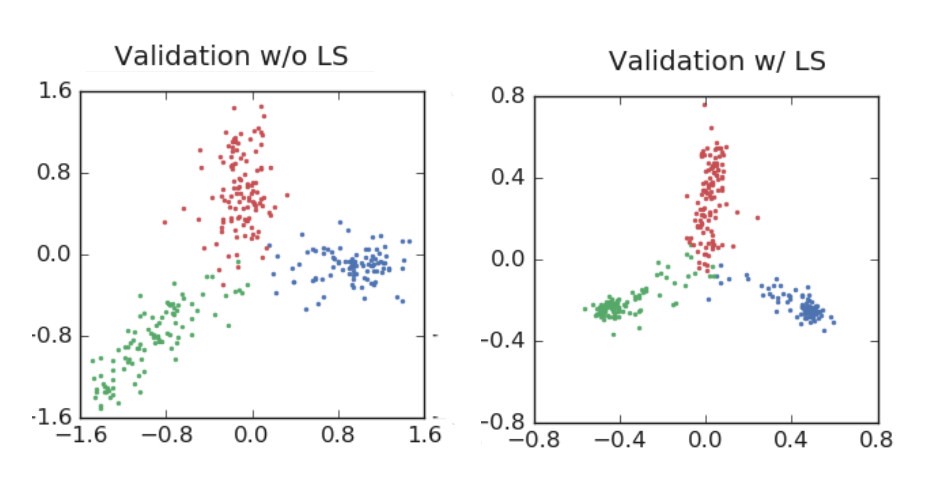 ResNet验证结果。标签平滑提高了最终精度。请注意,虽然标签平滑在培训中推动了对紧密集群的激活,但在验证中,它在中心周围传播,并利用了对其预测的全方位信心。[/caption]
ResNet验证结果。标签平滑提高了最终精度。请注意,虽然标签平滑在培训中推动了对紧密集群的激活,但在验证中,它在中心周围传播,并利用了对其预测的全方位信心。[/caption]
正如图像所显示的,标签平滑为最终的激活产生了更紧密的聚类和更大的类别间的分离。
这是为什么标签平滑产生更多的正则化和鲁棒的神经网络的主要原因,重要的是趋向于更好地泛化未来的数据。然而,有一个额外的有益效果,不仅仅是更好的激活中心…
从标签平滑的隐含网络校准: 本文从可视化的角度出发,展示了标签平滑如何在不需要人工温度调节的情况下,自动帮助校准网络,减少网络校准误差。
先前的研究(Guo et al)表明,相对于神经网络的真实精度,神经网络通常过于自信,且校准不当。为了证明这一点,Guo等人开发了一种称为ECE(预期校准误差)的校准措施。通过使用这种方法,他们能够用一种称为温度标度的训练后修正来调整给定神经网络的校准,并使网络更好地与它的实际技能(减少ECE)相一致,从而提高最终的精度。(在将最终登录与温度标量相乘后,再将其传递给softmax函数,即可执行温度缩放)。
本文给出了一些例子,但最好的例子是在ImageNet上训练有标签平滑和无标签平滑的ResNet,并将这两种网络与温度调节网络进行了比较。
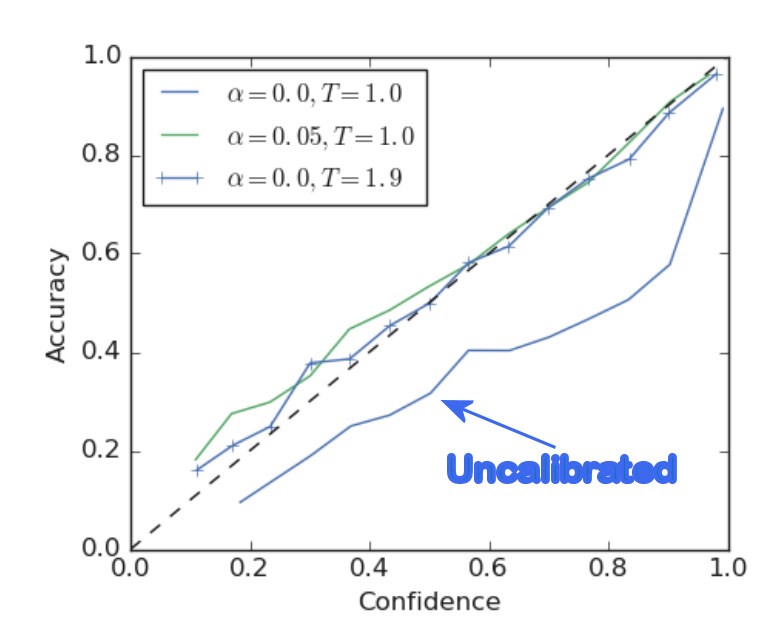
正如你所看到的,使用标签平滑训练产生的网络具有更好的ECE(预期校准误差),更简单地说,相对于它自己的精度有一个更理想的置信度。
实际上,经过平滑处理的标签网络并不是“过于自信”的,因此应该能够在未来的实时数据上进行泛化并表现得更好。
知识蒸馏(或者不使用标签平滑):论文的最后一部分讨论了这样一个发现,即尽管标签平滑可以产生用于各种任务的改进的神经网络,但如果最终的模型将作为其他“学生”网络的老师,那么就不应该使用它。
作者注意到,尽管使用标签平滑化训练提高了教师的最终准确性,但与使用“硬”目标训练的教师相比,它未能向学生网络传递足够多的知识(无标签平滑)。
[caption id="attachment_48937" align="aligncenter" width="893"]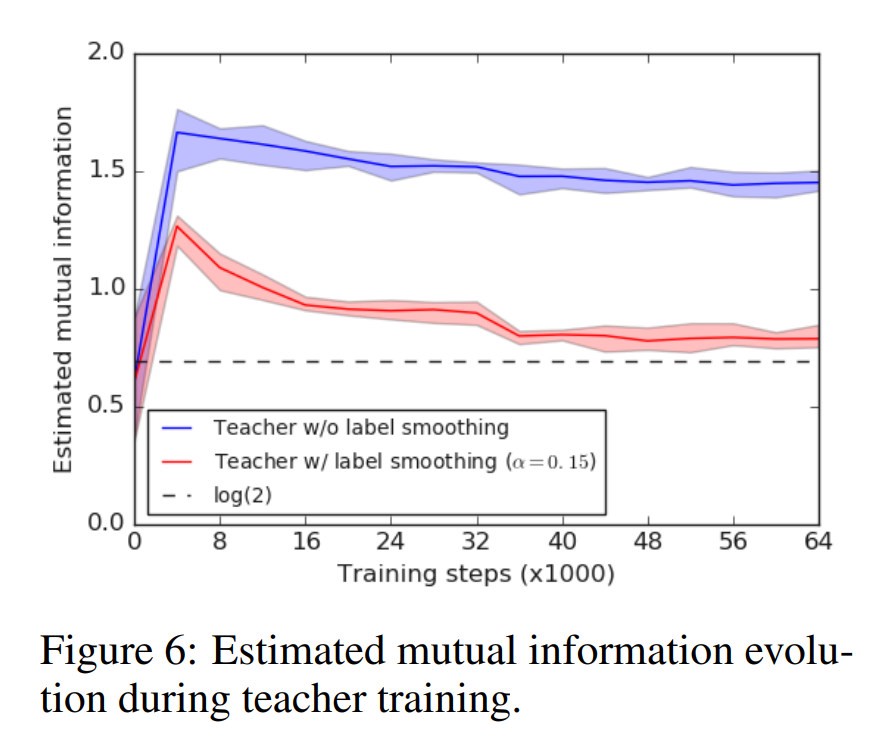 标记平滑“擦除”在硬目标训练中保留的一些细节。这种泛化有利于教师网络的性能,但是它传递给学生网络的信息更少。[/caption]
标记平滑“擦除”在硬目标训练中保留的一些细节。这种泛化有利于教师网络的性能,但是它传递给学生网络的信息更少。[/caption]
标签平滑的原因产生的模型,是多少显示在最初的可视化。在某种程度上显示在最初的可视化。通过将最终的分类强制到更紧密的集群中,网络删除了更多的细节,将重点放在类之间的核心区别上。
这种“舍入”有助于网络更好地处理不可见数据。然而,丢失的信息最终会对它教授新学生模型的能力产生负面影响。
因此,准确性更高的老师并不能更好地向学生提炼信息。
总结和SOTA提示:在几乎所有情况下,使用标签平滑训练可以产生更好的校准网络,从而更好地泛化,最终对不可见的生产数据更准确。
然而,有一种情况是,它没有用处,那就是建立网络,以后作为教师…然后硬目标训练将产生一个更好的教师神经网络。
注:与上述优秀论文及利用标签平滑的指南类似,过去三个月已经发表了许多有用的论文。因此,我计划为那些参与训练和建立神经网络的人提供SOTA最新最优秀论文的摘要和“训练技巧”(并将在我们团队下一次努力打破更多FastAI排行榜记录时使用同样的方法)。请继续关注!
原文链接:https://medium.com/@lessw/label-smoothing-deep-learning-google-brain-explains-why-it-works-and-when-to-use-sota-tips-977733ef020
[caption id="attachment_48916" align="alignnone" width="1716"]
从纸张标签平滑提供了广泛的深度学习模型的改进。[/caption]本文总结了本文的见解,帮助您快速利用这些发现进行自己的深入学习工作。建议对全文进行深入分析。
什么是标签平滑?标签平滑是一种损失函数修正,已被证明对训练深度学习网络非常有效。标签平滑提高了图像分类、翻译甚至语音识别的准确性。例如,我们的团队用它来打破许多FastAI排行榜记录:
[caption id="attachment_48917" align="aligncenter" width="1216"]
在FastAI训练代码中调用Labelsmoothing。[/caption]其工作原理的简单解释是,它将神经网络的训练目标从“1”调整为“1-label平滑调整”,这意味着神经网络被训练得对自己的答案不那么自信。默认值通常是.1,这意味着目标答案是.9(1 - 1)而不是1。
假设我们想把图像分为狗和猫。如果我们看到一张狗的照片,我们训练NN(通过交叉熵损失)朝着狗的1和猫的0移动。如果是猫,我们训练的方向相反,1代表猫,0代表狗。
然而,神经网络有一个坏习惯,就是在训练期间对自己的预测变得“过于自信”,这会降低他们概括的能力,从而在新的、看不见的未来数据上也会表现得很好。此外,大型数据集通常会包含错误标记的数据,这意味着神经网络本身应该对“正确答案”有点怀疑,以减少对某些错误答案的极端建模。
因此,标签平滑的作用是通过训练神经网络朝着“1-adjustment”目标移动,然后将调整量除以剩余的类,而不是简单的1,从而迫使神经网络对其答案缺乏信心。
对于我们的二进制dog/cat示例,标签平滑为.1意味着目标答案将是.90(90%置信度)这是一个dog For a dog图像,和.10(10%置信度)这是一个cat,而不是之前的1或0。由于不太确定,它充当了一种正则化的形式,提高了它在新数据上更好地执行的能力。
看到代码中的标签平滑可能有助于了解它如何比通常的数学(来自FastaiGithub)更好地工作。看起来像E(epsilon或ε)的希腊字母是标签平滑调整因素:
[caption id="attachment_48918" align="aligncenter" width="1701"]
FastAI实现标签平滑[/caption]标签平滑对神经网络的影响:现在我们进入文章的核心部分,直观地展示了标签平滑对神经网络分类处理的影响。
首先,AlexNet在训练中对“飞机、汽车和鸟类”进行分类。
[caption id="attachment_48923" align="aligncenter" width="1002"]
左-训练结果没有标签平滑。右-标签平滑训练。[/caption]然后验证:
正如您所看到的,标签平滑强制对分类进行更紧密的分组,同时强制在集群之间进行更等距的间隔。“海狸、海豚和水獭”的ResNet示例更加清晰:
[caption id="attachment_48932" align="aligncenter" width="994"]
ResNet训练用于分类3个图像类别…请注意在集群紧密性方面的巨大差异。[/caption][caption id="attachment_48934" align="aligncenter" width="946"]
ResNet验证结果。标签平滑提高了最终精度。请注意,虽然标签平滑在培训中推动了对紧密集群的激活,但在验证中,它在中心周围传播,并利用了对其预测的全方位信心。[/caption]正如图像所显示的,标签平滑为最终的激活产生了更紧密的聚类和更大的类别间的分离。
这是为什么标签平滑产生更多的正则化和鲁棒的神经网络的主要原因,重要的是趋向于更好地泛化未来的数据。然而,有一个额外的有益效果,不仅仅是更好的激活中心…
从标签平滑的隐含网络校准: 本文从可视化的角度出发,展示了标签平滑如何在不需要人工温度调节的情况下,自动帮助校准网络,减少网络校准误差。
先前的研究(Guo et al)表明,相对于神经网络的真实精度,神经网络通常过于自信,且校准不当。为了证明这一点,Guo等人开发了一种称为ECE(预期校准误差)的校准措施。通过使用这种方法,他们能够用一种称为温度标度的训练后修正来调整给定神经网络的校准,并使网络更好地与它的实际技能(减少ECE)相一致,从而提高最终的精度。(在将最终登录与温度标量相乘后,再将其传递给softmax函数,即可执行温度缩放)。
本文给出了一些例子,但最好的例子是在ImageNet上训练有标签平滑和无标签平滑的ResNet,并将这两种网络与温度调节网络进行了比较。
正如你所看到的,使用标签平滑训练产生的网络具有更好的ECE(预期校准误差),更简单地说,相对于它自己的精度有一个更理想的置信度。
实际上,经过平滑处理的标签网络并不是“过于自信”的,因此应该能够在未来的实时数据上进行泛化并表现得更好。
知识蒸馏(或者不使用标签平滑):论文的最后一部分讨论了这样一个发现,即尽管标签平滑可以产生用于各种任务的改进的神经网络,但如果最终的模型将作为其他“学生”网络的老师,那么就不应该使用它。
作者注意到,尽管使用标签平滑化训练提高了教师的最终准确性,但与使用“硬”目标训练的教师相比,它未能向学生网络传递足够多的知识(无标签平滑)。
[caption id="attachment_48937" align="aligncenter" width="893"]
标记平滑“擦除”在硬目标训练中保留的一些细节。这种泛化有利于教师网络的性能,但是它传递给学生网络的信息更少。[/caption]标签平滑的原因产生的模型,是多少显示在最初的可视化。在某种程度上显示在最初的可视化。通过将最终的分类强制到更紧密的集群中,网络删除了更多的细节,将重点放在类之间的核心区别上。
这种“舍入”有助于网络更好地处理不可见数据。然而,丢失的信息最终会对它教授新学生模型的能力产生负面影响。
因此,准确性更高的老师并不能更好地向学生提炼信息。
总结和SOTA提示:在几乎所有情况下,使用标签平滑训练可以产生更好的校准网络,从而更好地泛化,最终对不可见的生产数据更准确。
因此,默认情况下,标签平滑应该是大多数深度学习培训的一部分。
然而,有一种情况是,它没有用处,那就是建立网络,以后作为教师…然后硬目标训练将产生一个更好的教师神经网络。
注:与上述优秀论文及利用标签平滑的指南类似,过去三个月已经发表了许多有用的论文。因此,我计划为那些参与训练和建立神经网络的人提供SOTA最新最优秀论文的摘要和“训练技巧”(并将在我们团队下一次努力打破更多FastAI排行榜记录时使用同样的方法)。请继续关注!
原文链接:https://medium.com/@lessw/label-smoothing-deep-learning-google-brain-explains-why-it-works-and-when-to-use-sota-tips-977733ef020

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
神经机器翻译与代码(上)








广告


写评论取消
回复取消