











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






微软提出了一种新的人工智能培训方法
2019年12月31日 由 TGS 发表
403899
0
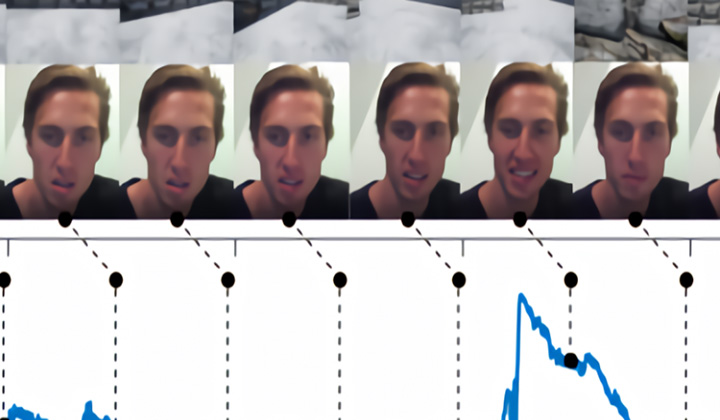 积极情感,来源于人的经历,与学习兴趣、好奇心和满足感的增加有关。受此启发,微软的一个研究团队提出了一种名为“灌输强化学习”的 人工智能培训技术,利用奖励来激励系统朝目标前进,他们断言,这会对人工智能的发展产生积极的影响。
积极情感,来源于人的经历,与学习兴趣、好奇心和满足感的增加有关。受此启发,微软的一个研究团队提出了一种名为“灌输强化学习”的 人工智能培训技术,利用奖励来激励系统朝目标前进,他们断言,这会对人工智能的发展产生积极的影响。传统的强化学习,通常是通过为预定目标设计的特定策略奖励来实现的。但问题是,这些外在的奖励范围很窄,很难定义,而内在的奖励是独立于任务的,可以很快就表明成功或是失败。
为了追求这种内在的策略,研究人员开发了一个由人类情感驱动的机制组成框架——一个通过喜悦、欢愉等驱动力来激励代理人的框架。它主要使用一个模拟奖励的计算机视觉系统和另一个使用数据来解决多个任务的系统,能够测量人类微笑的积极影响。
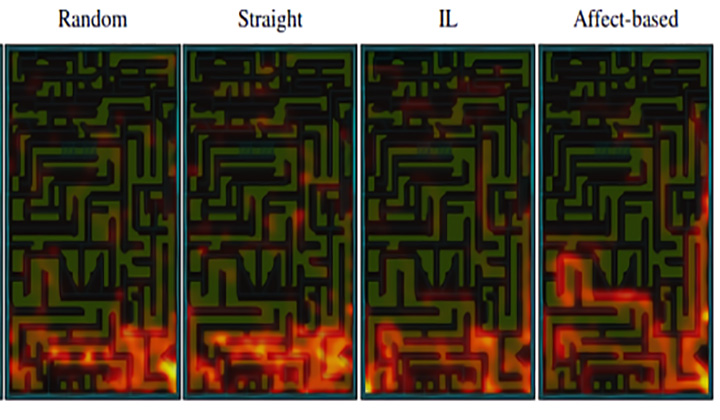 该框架鼓励代理探索虚拟或现实世界的环境,它的优势是不知道任何特定的机器智能应用程序。由两部分构成,一个积极的内在奖励机制预测人类的微笑反应随着探索发展,另一个连续的决策框架学习一个可推广的政策。积极的内在影响模型改变了行为选择,使行为偏向于提供更好的内在奖励,此外,还利用了一个组件,使用agent探索期间收集的数据,来构建视觉识别和理解任务的表示。
该框架鼓励代理探索虚拟或现实世界的环境,它的优势是不知道任何特定的机器智能应用程序。由两部分构成,一个积极的内在奖励机制预测人类的微笑反应随着探索发展,另一个连续的决策框架学习一个可推广的政策。积极的内在影响模型改变了行为选择,使行为偏向于提供更好的内在奖励,此外,还利用了一个组件,使用agent探索期间收集的数据,来构建视觉识别和理解任务的表示。为了测试这个框架,研究人员收集了五名受试者的数据,他们的任务是用一辆车探索一个数字三维迷宫,每人驾驶11分钟,共64000帧,期间,他们的面部表情会被系统捕捉。研究人员使用受试者数据训练基于情感的内在动机模型,进一步的实验结果表明,与基线测试相比,利用了内在奖励策略后,空间探索率提高了46%。
总的来说,这样一个内在的动机,是学习框架受情感机制影响的关键所在,目前可以帮助解决一些深度学习及场景分割任务。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
标签平滑与深度学习








广告


写评论取消
回复取消