











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






训练GANs的陷阱与提示
2019年08月03日 由 sunlei 发表
344826
0

生成性对抗网络(GANs)是目前人工智能领域深度学习中最热门的话题之一。在过去几个月里,在GANs上发表的论文数量大幅增加。GANs已经被应用于各种各样的问题,如果您错过了那一班车,这里有了关于GANs的一些很酷的应用列表。
现在,我已经阅读了很多关于GANs的内容,但我自己从未玩过。因此,在阅读了一些鼓舞人心的论文和github repos之后,我决定亲自动手训练一个简单的GAN,但很快就遇到了问题。本文面向刚开始使用GANs的深度学习爱好者。除非你很幸运,否则你自己第一次训练GAN可能是一个令人沮丧的过程,可能需要花费数小时才能做到正确。当然,随着时间的推移,随着经验的积累,您将会很好地培训甘斯,但是对于初学者来说,可能会出现一些错误,您甚至不知道从哪里开始调试。我想分享我在第一次从头开始训练GAN时的观察和经验教训,希望它可以节省一些人开始几个小时的调试时间。
生成性对抗网络
除非你在过去一年左右封闭生活在一个房间里,否则所有参与深度学习的人——甚至一些没有参与深度学习的人——都听说过并谈论过GANs。GANs或Generative Adversarial Networks是一种深度神经网络,是数据的生成模型。这意味着,给定一组训练数据,GANs可以学习估计数据的基本概率分布。这非常有用,因为除了其他内容之外,我们现在可以根据原始训练集中可能不存在的学习概率分布生成样本。如上面链接中所列,这产生了一些非常有用的应用程序。
该领域的专家已经有几个惊人的资源来解释GANs及其工作原理,因此我不会尝试复制他们的工作。但为了完整起见,这里有一个快速概述。
[caption id="attachment_42542" align="aligncenter" width="665"]
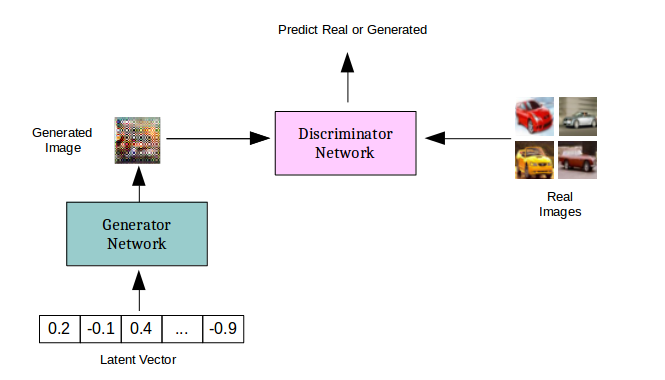 GAN概述[/caption]
GAN概述[/caption]生成性对抗网络实际上是两个相互竞争的深层网络。给定训练集X(比如几千只猫的图像),生成器网络G(X)将随机向量作为输入,并尝试产生类似于训练集中的图像。鉴别器网络D(X)是一种二元分类器,其试图根据训练集X和由生成器生成的假猫图像来区分真实猫图像。因此,Generator网络的工作是学习X中数据的分布,以便它可以产生真实的猫图像,并确保鉴别器无法区分训练集中的猫图像和生成器的猫图像。鉴别器需要学习跟上生成器的步伐,一直尝试新的技巧来生成假猫图像并欺骗鉴别器。
最终,如果一切顺利,发电机(或多或少)会学习训练数据的真实分布,并且真正擅长生成逼真的猫图像。鉴别器无法再区分训练集猫图像和生成的猫图像。
从这个意义上说,这两个网络不断地试图干扰另一个不能很好地完成他们的任务。那么,这到底是怎么回事呢?
另一种看待GAN设置的方法是,Discriminator试图通过告诉它真正的猫图像是什么样子来引导它。最终,生成器将其计算出来并开始生成逼真的猫图像。训练GANs的方法类似于博弈论中的Minimax算法,并且两个网络试图相对于彼此实现所谓的纳什均衡。 如果您想更详细地了解这一点,请参阅底部的参考资料。
GAN训练面临的挑战
回到GANs训练。首先,我使用Keras和Tensorflow后端,在MNIST数据集上训练了一个GAN(准确地说,是DC-GAN),这并不难。经过对生成器和鉴别器网络的一些小的调整,GAN能够生成MNIST数字的清晰图像。
[caption id="attachment_42544" align="aligncenter" width="482"]
 生成的MNIST数字[/caption]
生成的MNIST数字[/caption]黑白数字只是非常有趣。物体和人物的彩色图像是所有酷家伙都喜欢玩的东西。这就是事情开始变得棘手的地方。在MNIST之后,明显的下一步是生成CIFAR-10图像。在日复一日地调整超参数、更改网络架构、添加和删除层之后,我终于能够生成类似CIFAR-10的外观不错的图像。
[caption id="attachment_42546" align="aligncenter" width="438"]
 使用DC-GAN生成的青蛙[/caption]
使用DC-GAN生成的青蛙[/caption][caption id="attachment_42550" align="aligncenter" width="420"]
 使用DC-GAN生成的汽车[/caption]
使用DC-GAN生成的汽车[/caption]我从一个相当深的(但大部分是不良的)网络开始,最终得到了一个实际有效的、简单得多的网络。当我开始调整网络和训练过程时,15个时期后生成的图像看起来像这样,

接下来:

最终:

下面是我意识到自己犯过的错误以及我在此过程中学到的东西。因此,如果您是GANs的新手,并且在训练方面没有取得很大成功,那么查看以下方面可能会有所帮助:
免责声明:这只是我尝试过的事情和我得到的结果。我并没有声称已经解决了所有GAN训练问题。
1.更大内核和更多过滤器
较大的内核覆盖了前一层图像中的更多像素,因此可以查看更多信息。5x5内核与CIFAR-10配合良好,在鉴别器中使用3x3内核导致鉴别器损耗迅速逼近0。对于生成器,您希望顶部卷积层中的较大内核保持某种平滑性。在较低层,我没有看到改变内核大小的任何重大影响。
过滤器的数量可以大量增加参数的数量,但通常需要更多的过滤器。我在几乎所有的卷积层中都使用了128个过滤器。使用较少的过滤器,尤其是在发生器中,使得最终生成的图像太模糊。因此,看起来更多的过滤器有助于捕获额外的信息,最终可以为生成的图像增加清晰度。
2.翻转标签(Generated = True,Real = False)
虽然起初看起来很傻,但对我有用的一个主要技巧是改变标签分配。
如果您使用的是Real Images = 1和Generated Images = 0,那么反过来也会有所帮助。正如我们稍后将看到的,这有助于早期迭代中的梯度流,并有助于令事情发生变化。
3.软标签和噪音标签
在训练鉴别器时这非常重要。有硬标签(1或0)几乎扼杀了所有早期学习,导致鉴别器非常迅速地接近0损失。我最终使用0到0.1之间的随机数来表示0个标签(真实图像)和0.9到1.0之间的随机数来表示1个标签(生成的图像)。训练生成器时不需要这样做。
此外,它还有助于为训练标签添加一些噪音。对于输入识别器的5%的图像,标签被随机翻转。即真实被标记为生成并且生成被标记为真实。
4.批量规范有帮助,但前提是你有其他的东西
批处理规范化无疑有助于最终的结果。添加批处理规范后,生成的图像明显更清晰。但是,如果您错误地设置了内核或过滤器,或者识别器的损失很快达到0,添加批处理规范可能并不能真正帮助恢复。
[caption id="attachment_42553" align="aligncenter" width="451"]
 在网络中生成具有批处理规范层的车辆[/caption]
在网络中生成具有批处理规范层的车辆[/caption]5.一次一堂课
为了更容易地训练甘斯,确保输入数据具有相似的特性是很有用的。例如,与其在CIFAR-10的所有10个类中都训练GAN,不如选择一个类(例如,汽车或青蛙)并训练GAN从该类生成图像。DC-GAN的其他变体在学习生成多个类的图像方面做得更好。例如,以类标签为输入,生成基于类标签的图像。但是,如果你从一个普通的DC-GAN开始,最好保持过程简单。
6.看看梯度
如果可能的话,试着监控梯度以及网络中的损耗。这些可以帮助你更好地了解训练的进展,甚至可以帮助你在工作不顺利的情况下进行调试。
理想情况下,生成器应该在训练早期接收大的梯度,因为它需要学习如何生成真实的数据。另一方面,鉴别器并不总是在早期获得大的梯度,因为它可以容易地区分真实和伪造的图像。一旦对生成器进行了足够的训练,鉴别器就会变得更难以区分假图像。它会不断出错并获得强大的梯度。
我在CIFAR-10汽车上的最初几个GAN版本,有许多卷积和批量规范层,没有标签翻转。除了趋势之外,监测梯度的规模也很重要。如果生成器层上的梯度太小,学习可能会很慢,或者根本不会发生。这在GAN的这个版本中是可见的。
[caption id="attachment_42554" align="aligncenter" width="381"]
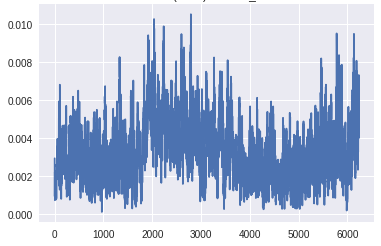 顶部生成器层的梯度(X轴:小批量迭代)[/caption]
顶部生成器层的梯度(X轴:小批量迭代)[/caption][caption id="attachment_42555" align="aligncenter" width="392"]
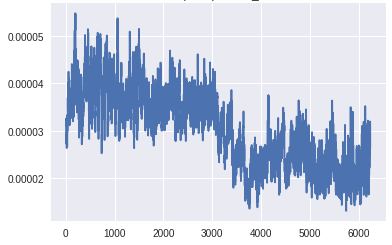 底部生成器层的梯度(X轴:小批量迭代)[/caption]
底部生成器层的梯度(X轴:小批量迭代)[/caption][caption id="attachment_42557" align="aligncenter" width="374"]
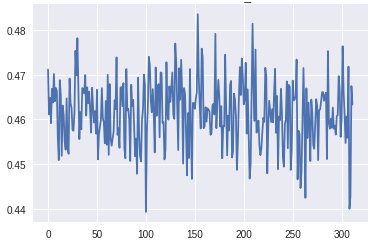 顶部鉴别器层的梯度(X轴:小批量迭代)[/caption]
顶部鉴别器层的梯度(X轴:小批量迭代)[/caption][caption id="attachment_42558" align="aligncenter" width="386"]
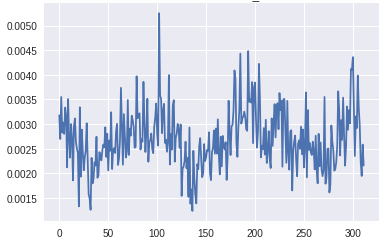 底部鉴别器层的梯度(X轴:小批量迭代)[/caption]
底部鉴别器层的梯度(X轴:小批量迭代)[/caption]在生成器的最下层梯度的规模太小,任何学习都无法进行。鉴别器的梯度始终是一致的,这表明鉴别器并没有真正学到任何东西。现在,让我们将其与GAN的梯度进行比较,GAN具有上面描述的所有变化,并生成良好的真实图像:
[caption id="attachment_42559" align="aligncenter" width="374"]
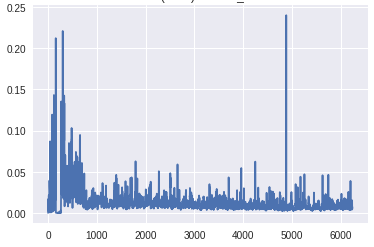 顶部生成器层的梯度(X轴:小批量迭代)[/caption]
顶部生成器层的梯度(X轴:小批量迭代)[/caption][caption id="attachment_42560" align="aligncenter" width="387"]
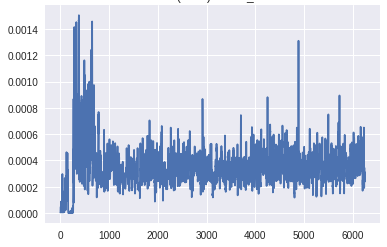 底部生成器层的梯度(X轴:小批量迭代)[/caption]
底部生成器层的梯度(X轴:小批量迭代)[/caption][caption id="attachment_42561" align="aligncenter" width="370"]
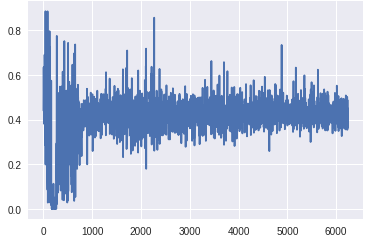 顶部鉴别器层的梯度(X轴:小批量迭代)[/caption]
顶部鉴别器层的梯度(X轴:小批量迭代)[/caption][caption id="attachment_42562" align="aligncenter" width="369"]
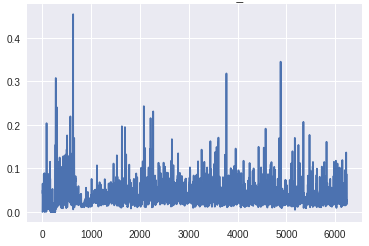 底部鉴别器层的梯度(X轴:小批量迭代)[/caption]
底部鉴别器层的梯度(X轴:小批量迭代)[/caption]梯度到达生成器底层的比例明显高于前一个版本。此外,随着训练的进展,梯度流与预期一样,随着发生器在早期获得较大的梯度,一旦训练足够,鉴别器在顶层获得一致的高梯度。
7.没有提前停止
我犯了一个愚蠢的错误——可能是由于我的不耐烦——当我看到损失没有任何明显的进展,或者生成的样本仍然有噪声时,在进行了几百次小批量培训之后,我就终止了培训。重新开始工作并节省时间比等待训练完成并最终意识到网络从未学过任何东西更有诱惑力。GANs需要花费很长时间来训练和初始几个损失值,并且生成的样本几乎从未显示任何趋势或进展迹象。在结束训练过程并调整设置之前,等待一段时间是很重要的。
此规则的一个例外是,如果您发现Discriminator损失迅速接近0。如果发生这种情况,则几乎没有恢复的可能性,最好重新开始训练,可能是在网络或培训过程中进行了更改之后。
最后的GAN是这样工作的:
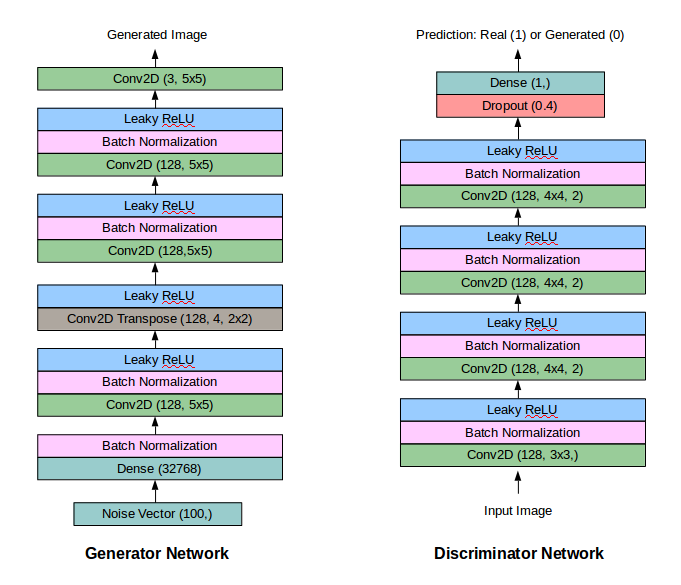
就是这样了。我希望这篇文章可以帮助任何人从头开始训练他们的第一个DC-GAN。以下是我关注的一些资源以及包含有关GAN的大量信息的其他资源:
GAN论文:
生成性对抗网络
基于深度卷积生成对抗性网络的无监督表示学习
改进的GANs训练技术
其他链接:
https://philparadis.wordpress.com/2017/04/24/training-gans-better-understanding-and-other-improved-techniques/
NIPS 2016 GAN教程
有条件的GAN
Keras中用于最终工作版本的GAN代码可以在我的Github上找到。
原文链接:https://medium.com/@utk.is.here/keep-calm-and-train-a-gan-pitfalls-and-tips-on-training-generative-adversarial-networks-edd529764aa9

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
关于跨语种语言模型的讨论
下一篇
国王-男人+女人=国王?








广告


写评论取消
回复取消