











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






MIT和谷歌利用机器学习自动翻译失传的语言
2019年07月08日 由 bie管我叫啥 发表
451618
0
 1886年,英国考古学家Arthur Evans偶然发现了一块古老的石头,上面用一种未知的语言刻着一组奇怪的文字。这块石头来自地中海的克里特岛,Evans立即前往那里寻找更多的证据。他很快发现了许多刻有类似文字的石头和石板,年代确定在公元前1400年左右。
1886年,英国考古学家Arthur Evans偶然发现了一块古老的石头,上面用一种未知的语言刻着一组奇怪的文字。这块石头来自地中海的克里特岛,Evans立即前往那里寻找更多的证据。他很快发现了许多刻有类似文字的石头和石板,年代确定在公元前1400年左右。这使得铭文成为迄今为止发现的最早的文字形式之一。Evans认为,它的线性形式显然来自于艺术初期粗糙的线条画,从而确立了它在语言学史上的重要性。他和其他人后来确定这些石头和石板是用两种不同的文字写的。
最古老的被称为Linear A,可以追溯到公元前1800年到1400年之间,当时该岛被青铜时代的米诺斯文明所统治。另一个Linear B,出现在公元前1400年,当时该岛被希腊大陆的迈锡尼人统治。
破译的障碍
Evans等人多年来一直试图破译古代文字,但丢失的语言阻碍了所有的成功。这个问题一直没有解决,直到1953年,一位名叫Michael Ventris的业余语言学家破解了Linear B。
他的解决方案建立在两个决定性的突破上。首先,Ventris推测Linear B词汇中的许多重复词都是克里特岛上的名字,结果证明是正确的。
他的第二个突破是假设写作记录了古希腊的早期形式。这种见解立刻让他破译了其余的语言。在这个过程中,Ventris表明古希腊人首先以书面形式出现,比先前想象的要早几个世纪。
Ventris的工作是一项巨大的成就。但是,更古老的Linear A至今仍是语言学中最突出的问题之一。
借助机器学习
机器翻译的最新进展可能会有所帮助。在短短几年内,语言学研究因巨大的注释数据库的可用性以及让机器从中学习的技术而发生了革命性的变化。因此,从一种语言到另一种语言的机器翻译已成为常规。虽然它并不完美,但这些方法提供了一种全新的语言思考方式。
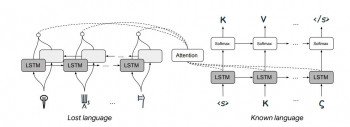 麻省理工学院的Jiaming Luo和Regina Barzilay以及谷歌AI实验室的Yuan Cao合作开发了一种机器学习系统,能够解读丢失的语言,他们通过解密Linear B来证明这一点,这是第一次自动完成。他们使用的方法与标准的机器翻译技术非常不同。
麻省理工学院的Jiaming Luo和Regina Barzilay以及谷歌AI实验室的Yuan Cao合作开发了一种机器学习系统,能够解读丢失的语言,他们通过解密Linear B来证明这一点,这是第一次自动完成。他们使用的方法与标准的机器翻译技术非常不同。首先是一些背景。机器翻译背后的一个重要思想是,无论涉及哪种语言,单词都以相似的方式相互关联。
因此,该过程首先将特定语言的这些关系映射出来。这需要庞大的文本数据库。然后,机器搜索此文本以查看每个单词在每个其他单词旁边出现的频率。这种出现模式是一个唯一的签名,用于在多维参数空间中定义单词。实际上,这个词可以被认为是这个空间中的一个向量。这个向量作为一个强有力的约束条件,可以在机器给出的任何翻译中出现这个词。
这些向量遵循一些简单的数学规则。例如:国王-男人+女人=女王。并且句子可以被认为是一组向量,它们一个接一个地形成一种通过这个空间的轨迹。
实现机器翻译的关键见解是,不同语言的单词在各自的参数空间中占据相同的点。这使得可以通过一对一的对应将整个语言映射到另一种语言。
通过这种方式,翻译句子的过程成为通过这些空间找到相似轨迹的过程。机器甚至不需要真正理解句子的含义。
该过程主要依赖于大型数据集。但几年前,一个德国研究小组展示了如何用更小的数据库进行类似的方法,可以帮助翻译缺乏大型文本数据库的罕见语言。诀窍是找到一种不同的方法来约束不依赖于数据库的机器方法。
现在团队进一步展示了机器翻译如何破译完全失传的语言。他们使用的约束与已知语言随时间演变的方式有关。
这个想法是任何语言都只能以某种方式改变,例如,相关语言中的符号以相似的分布出现,相关的单词具有相同的字符顺序,依此类推。如果这些规则限制了机器,只要知道祖先语言,就可以更容易地破译语言。
测试
团队用两种失去的语言,即Linear B和Ugaritic对这项技术进行了测试。语言学家知道Linear B编码古希腊语的早期版本,并且在1929年发现的Ugaritic是希伯来语的早期形式。
鉴于信息和语言演变所施加的限制,机器能够以非常准确的方式翻译这两种语言。团队表示,“我们能够在解密方案中正确地将67.3%的Linear B同源词转换成他们的希腊语。据我们所知,这是首次自动解读Linear B的尝试。”
这是令人印象深刻的研究,将机器翻译提升到一个新的水平。但它也提出了其他失传语言的有趣问题,特别是那些从未被破译过的语言,如Linear A。
在论文中,Linear A因其失传而引人注目。但它对所有语言学家来说都非常重要。然而,在此脚本变得适合机器翻译之前,仍然需要取得重大突破。
例如,没人知道Linear A编码的语言。尝试将其破译成古希腊语都失败了。没有祖先语言,新技术不起作用。
但基于机器的方法的最大优点是它们可以快速测试一种语言,而不会变得疲惫。因此,团队很可能用蛮力的方法解决Linear A问题。只是试图将其解读为机器翻译已经运行的每种语言。如果这样有效,那将是一项备受瞩目的成就。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消