











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






微软因果推理框架DoWhy入门
2019年06月18日 由 sunlei 发表
783196
0

人类的大脑有一种非凡的能力,能将原因与特定的事件联系起来。从选举的结果到掉在地板上的物体,我们不断地把引起特定效果的一系列事件联系起来。神经心理学将这种认知能力称为因果推理。计算机科学和经济学研究一种特殊形式的因果推理,称为因果推理,主要研究两个观察变量之间的关系。多年来,机器学习产生了许多用于因果推理的方法,但它们在主流应用中大多难以使用。最近,微软研究院(Microsoft Research)开发了一个用于因果思维和分析的框架DoWhy。
因果推理的挑战不在于它是一门新的学科,而恰恰相反,而是当前的方法代表了因果推理的一个非常小而简单的版本。大多数试图将原因(如线性回归)联系起来的模型都依赖于对数据做出某种假设的经验分析。纯粹的因果推理依赖于反事实分析,而反事实分析更接近于人类如何做出决策。想象一个场景,你和家人一起去一个未知的目的地度假。假期前后,你都在纠结一些与事实相悖的问题:
- 假期里我们应该做什么?
我们会开心吗?
我们为什么会觉得开心?
之后我们会有什么感觉?
回答这些问题是因果推理的重点。与监督学习不同,因果推理依赖于对未观测量的估计。这通常被称为因果推理的“基本问题”,这意味着一个模型从来没有通过一个剩余的测试集得到一个纯粹客观的评估。这一挑战迫使因果推理对数据生成过程做出关键假设。用于因果推理的传统机器学习框架试图绕过“基本问题”,这给数据科学家和开发人员带来了非常令人沮丧的体验。
介绍Dowhy
微软的DoWhy是一个基于python的因果推理和分析库,它试图简化在机器学习应用程序中采用因果推理的过程。受到朱迪亚·珀尔的因果推理演算的启发,DoWhy在一个简单的编程模型下结合了几种因果推理方法,消除了传统方法的许多复杂性。与前人相比,DoWhy对因果推理模型的实现做出了三个关键贡献。
- 提出了一种将给定问题建模为因果图的原则方法,使所有假设都清晰可见。
- 为许多流行的因果推理方法提供统一的接口,结合了图形模型和潜在结果的两个主要框架。
- 如果可能的话,自动测试假设的有效性,并评估对违规的估计的稳健性能。
从概念上讲,DoWhy的创建遵循两个指导原则:明确询问因果假设,并测试对违反这些假设的估计的稳健性。换句话说,DoWhy将因果效应的识别从相关性的估计中分离出来,相关性的估计能够推断出非常复杂的因果关系。
为了实现其目标,DoWhy将工作流中的任何因果推理问题建模为四个基本步骤:建模、识别、估计和反驳。
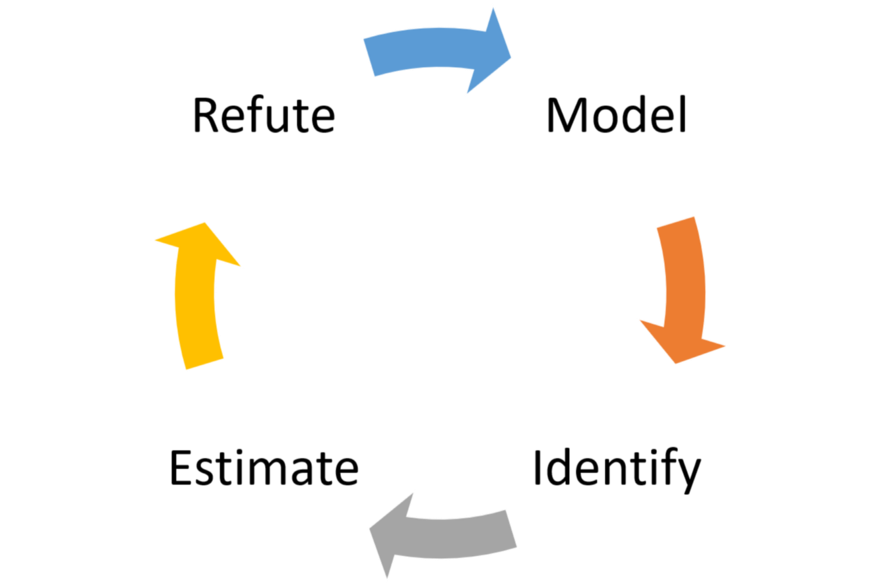
- 模型:DoWhy使用因果关系图对每个问题建模。DoWhy的当前版本支持两种图形输入格式:gml(首选)和dot。图中可能包含了变量之间因果关系的先验知识,但DoWhy不做任何直接的假设。
- 标识:使用输入图,DoWhy根据图形模型找到所有可能的方法来标识期望的因果关系。它使用基于图的标准和do-calculus来寻找潜在的方法,找到能够识别因果关系的表达式
- 估计:DoWhy使用匹配或工具变量等统计方法估计因果效应。DoWhy的当前版本支持基于倾向性分层或倾向性评分匹配的估计方法,这些方法侧重于估计处理任务,以及侧重于估计响应面的回归技术。
- 验证:最后,DoWhy使用不同的robustness methods(鲁棒性方法)验证因果效应的有效性。
使用DoWhy
开发人员可以通过使用下面的命令安装Python模块来开始使用DoWhy:
python setup.py install
与任何其他机器学习程序一样,DoWhy应用程序的第一步是加载数据集。在本例中,假设我们试图推断不同的医疗治疗与以下数据集所表示的结果之间的相关性。
Treatment Outcome w0
0 2.964978 5.858518 -3.173399
1 3.696709 7.945649 -1.936995
2 2.125228 4.076005 -3.975566
3 6.635687 13.471594 0.772480
4 9.600072 19.577649 3.922406
DoWhy依赖于panda dataframes来捕获输入数据:
rvar = 1 if np.random.uniform() >0.5 else 0
data_dict = dowhy.datasets.xy_dataset(10000, effect=rvar, sd_error=0.2)
df = data_dict['df']
print(df[["Treatment", "Outcome", "w0"]].head())
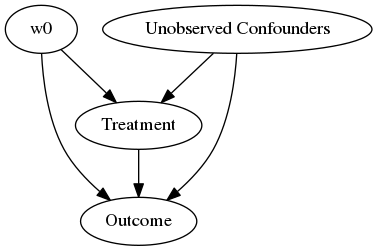
在这一点上,我们只需要四个步骤来推断变量之间的因果关系。这四个步骤对应于DoWhy的四个操作:建模、估计、推断和反驳。我们可以从将问题建模为因果图开始:
model= CausalModel(
data=df,
treatment=data_dict["treatment_name"],
outcome=data_dict["outcome_name"],
common_causes=data_dict["common_causes_names"],
instruments=data_dict["instrument_names"])
model.view_model(layout="dot")
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
下一步是确定图表中的因果关系:
identified_estimand = model.identify_effect()
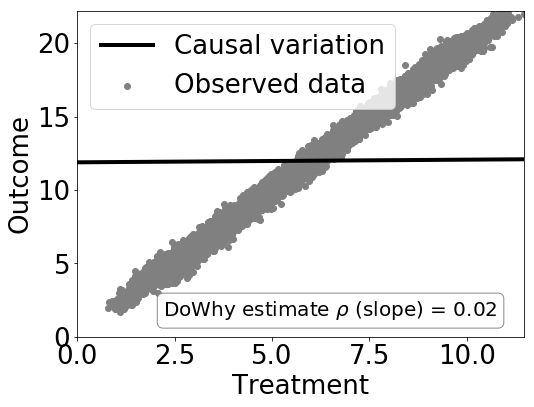
现在我们可以估计因果关系,并确定估计是否正确。此示例使用线性回归来简化:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.linear_regression")
# Plot Slope of line between treamtent and outcome =causal effect
dowhy.plotter.plot_causal_effect(estimate, df[data_dict["treatment_name"]], df[data_dict["outcome_name"]])
最后,我们可以使用不同的技术来反驳因果估计:
res_random=model.refute_estimate(identified_estimand, estimate, method_name="random_common_cause")
DoWhy是一个非常简单和有用的框架来实现因果推理模型。当前版本可以作为一个独立的库使用,也可以集成到流行的深度学习框架中,如TensorFlow或PyTorch。在一个框架下结合多种因果推理方法和四步简单编程模型,使得DoWhy对于处理因果推理问题的数据科学家来说非常简单。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
从技术角度看罪犯如何使用人工智能








广告


写评论取消
回复取消