











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






不用多进程的Python十倍速并行技巧(下)
2019年06月12日 由 sunlei 发表
286036
0
上一篇我们学习了三种不易用Python多处理表示的工作负载基准测试的其中两种,并比较了Ray、Python多处理和串行Python代码。今天这一篇我们来聊聊第三种基准测试。
传送门:不用多进程的Python十倍速并行技巧(上)
与前面的示例不同,许多并行计算不一定要求在任务之间共享中间计算,但无论如何都会从中受益。即使是无状态计算,在状态初始化代价高昂时也可以从共享状态中获益。
下面是一个例子,我们希望从磁盘加载一个保存的神经网络,并使用它来并行分类一组图像。
[caption id="attachment_41175" align="aligncenter" width="600"]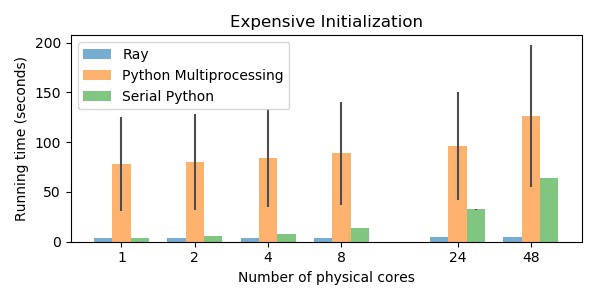 在48个物理内核的机器上,Ray比Python多处理快25倍,比单线程Python快13倍。在本例中,Rython多处理并没有优于单线程Rython。错误栏被描绘出来,但在某些情况下太小而看不见。工作负载被缩放到核心的数量,因此在更多的核心上完成更多的工作。在这个基准测试中,“串行”Python代码实际上通过TensorFlow使用多个线程。Python多处理代码的可变性来自于重复从磁盘加载模型的可变性,而其他方法不需要这样做。[/caption]
在48个物理内核的机器上,Ray比Python多处理快25倍,比单线程Python快13倍。在本例中,Rython多处理并没有优于单线程Rython。错误栏被描绘出来,但在某些情况下太小而看不见。工作负载被缩放到核心的数量,因此在更多的核心上完成更多的工作。在这个基准测试中,“串行”Python代码实际上通过TensorFlow使用多个线程。Python多处理代码的可变性来自于重复从磁盘加载模型的可变性,而其他方法不需要这样做。[/caption]
本例使用Ray的5s、Python多处理的126s和串行Python的64s(在48个物理内核上)。在本例中,串行Python版本使用多个内核(通过TensorFlow)并行化计算,因此它实际上不是单线程的。
假设我们最初通过运行以下代码创建了模型:
用于将神经网络模型保存到磁盘的代码。
现在,我们希望加载模型并使用它对一组图像进行分类。我们批量进行这项工作是因为在应用程序中,图像可能不会全部同时可用,而图像分类可能需要与数据加载并行进行。
Ray版本如下所示:
使用Ray的玩具分类示例的代码。
加载模型的速度很慢,我们只想加载一次。Ray版本通过在参与者的构造函数中加载模型一次来分摊此成本。如果模型需要放在GPU上,那么初始化将更加昂贵。
多处理版本速度较慢,因为它需要在每次映射调用中重新加载模型,因为假定映射函数是无状态的。
多处理版本如下。注意,在某些情况下,可以使用multiprocessing.Pool的初始化参数来实现这一点。但是,这仅限于初始化对每个进程都是相同的设置,并且不允许不同的进程执行不同的设置函数(例如,加载不同的神经网络模型),也不允许针对不同的工作者执行不同的任务。
使用多处理的玩具分类示例的代码。
我们在所有这些例子中看到的是,Ray的性能不仅来自于它的性能优化,还来自于对手头任务进行适当的抽象。有状态计算对许多应用程序都很重要,将有状态计算强制为无状态抽象是有代价的。
在运行这些基准测试之前,您需要安装以下软件。
然后,通过运行这些脚本,可以复制上面的所有数字。
如果在安装psutil时遇到问题,请尝试使用Python。
最初的基准测试是使用M5实例类型(M5.large用于1个物理内核,M5.24XLarge用于48个物理内核)在EC2上运行的。
为了使用正确的配置启动AWS或GCP上的实例,您可以使用Ray Autoscaler并运行以下命令。
这里提供了一个config.yaml示例(用于启动M5.4XL实例)。
尽管本文关注的是Ray和Python多处理之间的基准测试,但苹果对苹果的比较是具有挑战性的,因为这些库并不十分相似。差异包括以下内容。
Ray是为可扩展性而设计的,可以在笔记本电脑和集群上运行相同的代码(多处理仅在一台机器上运行)。
Ray工作负载自动从机器和流程故障中恢复。
Ray是以一种与语言无关的方式设计的,并且对Java有初步的支持。
所以说,这篇文章帮到你了吗?谢谢捧场~
传送门:不用多进程的Python十倍速并行技巧(上)
基准3:昂贵的初始化
与前面的示例不同,许多并行计算不一定要求在任务之间共享中间计算,但无论如何都会从中受益。即使是无状态计算,在状态初始化代价高昂时也可以从共享状态中获益。
下面是一个例子,我们希望从磁盘加载一个保存的神经网络,并使用它来并行分类一组图像。
[caption id="attachment_41175" align="aligncenter" width="600"]
在48个物理内核的机器上,Ray比Python多处理快25倍,比单线程Python快13倍。在本例中,Rython多处理并没有优于单线程Rython。错误栏被描绘出来,但在某些情况下太小而看不见。工作负载被缩放到核心的数量,因此在更多的核心上完成更多的工作。在这个基准测试中,“串行”Python代码实际上通过TensorFlow使用多个线程。Python多处理代码的可变性来自于重复从磁盘加载模型的可变性,而其他方法不需要这样做。[/caption]本例使用Ray的5s、Python多处理的126s和串行Python的64s(在48个物理内核上)。在本例中,串行Python版本使用多个内核(通过TensorFlow)并行化计算,因此它实际上不是单线程的。
假设我们最初通过运行以下代码创建了模型:
import tensorflow as tf
mnist = tf.keras.datasets.mnist.load_data()
x_train, y_train = mnist[0]
x_train = x_train / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model.
model.fit(x_train, y_train, epochs=1)
# Save the model to disk.
filename = '/tmp/model'
model.save(filename)
用于将神经网络模型保存到磁盘的代码。
现在,我们希望加载模型并使用它对一组图像进行分类。我们批量进行这项工作是因为在应用程序中,图像可能不会全部同时可用,而图像分类可能需要与数据加载并行进行。
Ray版本如下所示:
import psutil
import ray
import sys
import tensorflow as tf
num_cpus = psutil.cpu_count(logical=False)
ray.init(num_cpus=num_cpus)
filename = '/tmp/model'
@ray.remote
class Model(object):
def __init__(self, i):
# Pin the actor to a specific core if we are on Linux to prevent
# contention between the different actors since TensorFlow uses
# multiple threads.
if sys.platform == 'linux':
psutil.Process().cpu_affinity([i])
# Load the model and some data.
self.model = tf.keras.models.load_model(filename)
mnist = tf.keras.datasets.mnist.load_data()
self.x_test = mnist[1][0] / 255.0
def evaluate_next_batch(self):
# Note that we reuse the same data over and over, but in a
# real application, the data would be different each time.
return self.model.predict(self.x_test)
actors = [Model.remote(i) for i in range(num_cpus)]
# Time the code below.
# Parallelize the evaluation of some test data.
for j in range(10):
results = ray.get([actor.evaluate_next_batch.remote() for actor in actors])
使用Ray的玩具分类示例的代码。
加载模型的速度很慢,我们只想加载一次。Ray版本通过在参与者的构造函数中加载模型一次来分摊此成本。如果模型需要放在GPU上,那么初始化将更加昂贵。
多处理版本速度较慢,因为它需要在每次映射调用中重新加载模型,因为假定映射函数是无状态的。
多处理版本如下。注意,在某些情况下,可以使用multiprocessing.Pool的初始化参数来实现这一点。但是,这仅限于初始化对每个进程都是相同的设置,并且不允许不同的进程执行不同的设置函数(例如,加载不同的神经网络模型),也不允许针对不同的工作者执行不同的任务。
from multiprocessing import Pool
import psutil
import sys
import tensorflow as tf
num_cpus = psutil.cpu_count(logical=False)
filename = '/tmp/model'
def evaluate_next_batch(i):
# Pin the process to a specific core if we are on Linux to prevent
# contention between the different processes since TensorFlow uses
# multiple threads.
if sys.platform == 'linux':
psutil.Process().cpu_affinity([i])
model = tf.keras.models.load_model(filename)
mnist = tf.keras.datasets.mnist.load_data()
x_test = mnist[1][0] / 255.0
return model.predict(x_test)
pool = Pool(num_cpus)
for _ in range(10):
pool.map(evaluate_next_batch, range(num_cpus))
使用多处理的玩具分类示例的代码。
我们在所有这些例子中看到的是,Ray的性能不仅来自于它的性能优化,还来自于对手头任务进行适当的抽象。有状态计算对许多应用程序都很重要,将有状态计算强制为无状态抽象是有代价的。
运行基准测试
在运行这些基准测试之前,您需要安装以下软件。
pip install numpy psutil ray scipy tensorflow
然后,通过运行这些脚本,可以复制上面的所有数字。
如果在安装psutil时遇到问题,请尝试使用Python。
最初的基准测试是使用M5实例类型(M5.large用于1个物理内核,M5.24XLarge用于48个物理内核)在EC2上运行的。
为了使用正确的配置启动AWS或GCP上的实例,您可以使用Ray Autoscaler并运行以下命令。
ray up config.yaml
这里提供了一个config.yaml示例(用于启动M5.4XL实例)。
关于Ray的更多信息
尽管本文关注的是Ray和Python多处理之间的基准测试,但苹果对苹果的比较是具有挑战性的,因为这些库并不十分相似。差异包括以下内容。
Ray是为可扩展性而设计的,可以在笔记本电脑和集群上运行相同的代码(多处理仅在一台机器上运行)。
Ray工作负载自动从机器和流程故障中恢复。
Ray是以一种与语言无关的方式设计的,并且对Java有初步的支持。
所以说,这篇文章帮到你了吗?谢谢捧场~

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消