











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






EfficientNet解析:卷积神经网络模型规模化的反思
2019年06月13日 由 sunlei 发表
686510
0
自从Alexnet赢得2012年的ImageNet竞赛以来,CNNs(卷积神经网络的缩写)已经成为深度学习中各种任务的事实算法,尤其是计算机视觉方面。从2012年至今,研究人员一直在试验并试图提出越来越好的体系结构,以提高模型在不同任务上的准确性。近期,谷歌提出了一项新型模型缩放方法:利用复合系数统一缩放模型的所有维度,该方法极大地提升了模型的准确率和效率。谷歌研究人员基于该模型缩放方法,提出了一种新型 CNN 网络——EfficientNet,该网络具备极高的参数效率和速度。今天,我们将深入研究最新的研究论文efficient entnet,它不仅关注提高模型的准确性,而且还关注模型的效率。
为什么缩放很重要?
在讨论“缩放到底是什么意思?”,与此相关的问题是:为什么规模如此重要?通常,缩放是为了提高模型在特定任务上的准确性,例如ImageNet分类。虽然有时研究人员并不太在意有效模型,因为竞争是为了打败SOTA,但是如果正确地进行缩放,也可以帮助提高模型的效率。
在CNNs环境中,缩放意味着什么?
CNN有三个缩放维度:深度、宽度和分辨率。深度只是指网络的深度,相当于网络中的层数。宽度就是网络的宽度。例如,宽度的一个度量是Conv层中的通道数,而分辨率只是传递给CNN的图像分辨率。下图(来自本文本身)将使您清楚地了解不同维度的缩放意味着什么。我们也将详细讨论这些问题。
[caption id="attachment_41206" align="aligncenter" width="880"]
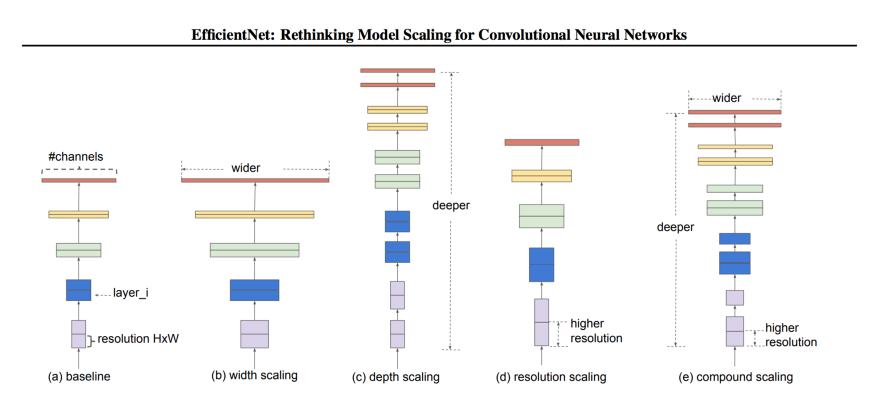 模型扩展。(a)是基线网络的例子;(b)-(d)是只增加网络宽度、深度或分辨率一维的传统尺度。(e)提出了以固定比例均匀缩放三维空间的复合缩放方法。[/caption]
模型扩展。(a)是基线网络的例子;(b)-(d)是只增加网络宽度、深度或分辨率一维的传统尺度。(e)提出了以固定比例均匀缩放三维空间的复合缩放方法。[/caption]Depth Scaling (d):
按深度扩展网络是最常见的缩放方式。深度可以通过添加/删除图层来放大或缩小。例如,可以从ResNet-50扩展到ResNet-200,也可以从ResNet-50缩小到ResNet-18。但为什么是深度缩放呢?直觉告诉我们,更深层次的网络可以捕获更丰富、更复杂的特性,并能很好地概括新任务。
很好。那么,让我们把网络扩展到1000层?如果我们有资源和机会改进这个任务,我们不介意添加额外的层。
说起来容易做起来难!理论上,随着层数的增加,网络性能应该会提高,但实际上并没有随之提高。消失梯度是我们深入研究时最常见的问题之一。即使你避免渐变消失,并使用一些技术使训练平滑,添加更多的图层并不总是有帮助。例如,ResNet-1000具有与ResNet-101类似的精度。
Width Scaling (w):
当我们想要保持模型较小时,通常使用这种方法。更广泛的网络往往能够捕获更细粒度的特性。此外,较小的型号更容易训练。
这不正是我们想要的吗?小模型,提高精度?
问题是,即使您可以使您的网络非常宽,使用浅模型(不太深但更宽),随着更大的宽度,精度很快就会饱和。
好吧,我们既不能使我们的网络非常深,也不能使它非常广。但是你不能把上面两个比例结合起来吗?如果你直到现在才明白,你觉得自己擅长机器学习么?呵呵!
但在我们研究它之前,我们先讨论第三个缩放维度。三个的组合也可以,对吧?
Resolution (r):
直观地说,在高分辨率图像中,特征更细粒度,因此高分辨率图像应该更好地工作。这也是为什么在复杂的任务中,如对象检测,我们使用图像分辨率像300x300,或512x512,或600x600。但这不是线性的。精度增益下降得很快。例如,将分辨率从500x500增加到560x560不会产生显著的改进。
以上三点引出了我们的第一个观察:扩展网络的任何维度(宽度、深度或分辨率)都可以提高精度,但对于较大的模型,精度增益会减小。
[caption id="attachment_41207" align="aligncenter" width="880"]
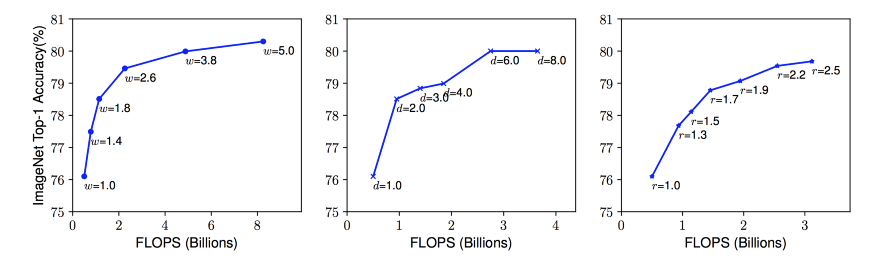 使用不同的网络宽度(W)、深度(D)和分辨率(R)系数放大基线模型。更大的网络具有更大的宽度、深度或分辨率,可以获得更高的精度,但精度达到80%后会迅速饱和,这说明了单维尺度的局限性。[/caption]
使用不同的网络宽度(W)、深度(D)和分辨率(R)系数放大基线模型。更大的网络具有更大的宽度、深度或分辨率,可以获得更高的精度,但精度达到80%后会迅速饱和,这说明了单维尺度的局限性。[/caption]那么组合缩放呢?
是的,我们可以结合不同维度的缩放,但作者提出了一些观点:
- 虽然可以任意缩放二维或三维,但任意缩放是一项繁琐的任务。
- 大多数情况下,手动缩放会导致精度和效率低于最佳。
直觉告诉我们,随着图像分辨率的提高,网络的深度和宽度也应该增加。随着深度的增加,更大的接受域可以捕获包含更多像素的类似特征。此外,随着宽度的增加,将捕获更多的细粒度特性。为了验证这种直觉,作者对每个维度进行了许多不同缩放值的实验。例如,从本文的下图中可以看出,在相同的FLOPS成本下,宽度缩放的精度要高得多,而且分辨率更高、更深。
[caption id="attachment_41208" align="aligncenter" width="880"]
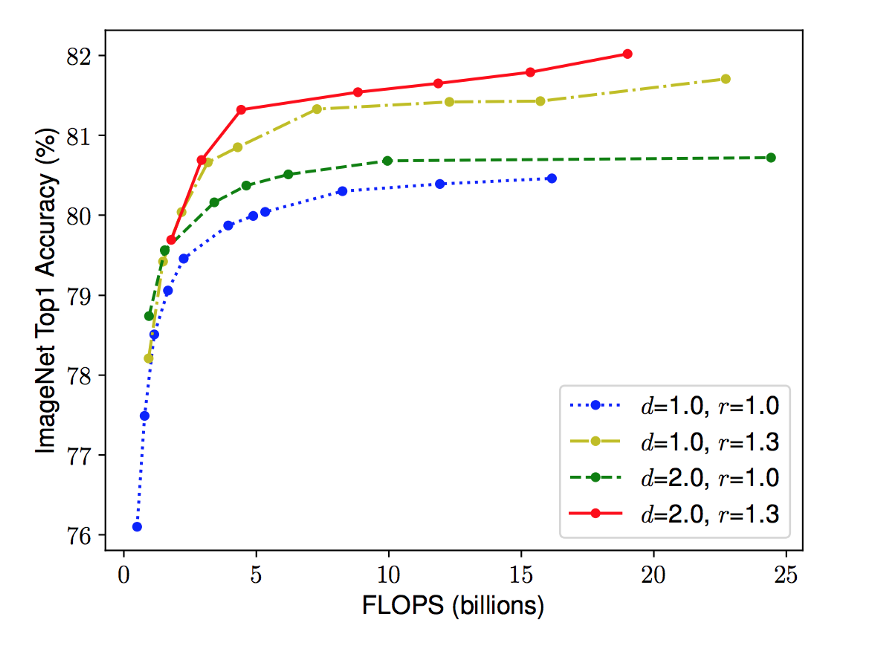 缩放不同基线网络的网络宽度。一行中的每个点表示一个具有不同宽度系数(w)的模型。所有基线网络均来自表1。第一基线网络(d=1.0,r=1.0)有18个分辨率为224x224的卷积层,而最后一基线(d=2.0,r=1.3)有36个分辨率为299x299的卷积层。[/caption]
缩放不同基线网络的网络宽度。一行中的每个点表示一个具有不同宽度系数(w)的模型。所有基线网络均来自表1。第一基线网络(d=1.0,r=1.0)有18个分辨率为224x224的卷积层,而最后一基线(d=2.0,r=1.3)有36个分辨率为299x299的卷积层。[/caption]这些结果导致了我们的第二次观察:在CNNs缩放期间平衡网络的所有维度(宽度、深度和分辨率)对于提高精度和效率至关重要。
提出了复合比例
作者提出了一个简单但非常有效的缩放技术使用一个复合系数ɸ以统一原则来规模化网络的宽度、深度和分辨率:
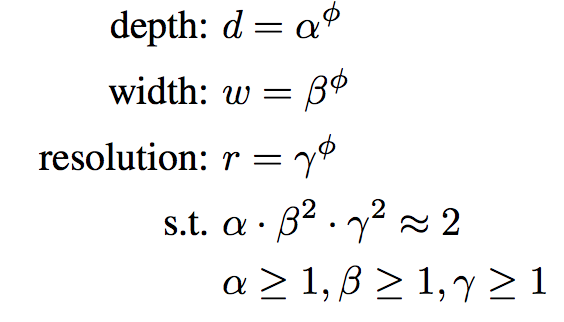
ɸ是一个指定的系数,控制多少资源可用,而α,β,γ指定如何将这些资源分配给网络深度、宽度和分辨率。
但是这里你可能会有两个疑问:首先,为什么α平方不一样呢?第二,为什么要把这三个数的乘积限制为2?
这是很好的问题。在CNN中,Conv层是网络中计算开销最大的部分。同时,失败的卷积运算几乎正比于d, w², r²,即增加深度将加倍失败而增加宽度或决议增加失败几乎是四倍。因此,为了确保总失败不超过2 ^ϕ,约束应用是(α * β² * γ²) ≈ 2。
EfficientNet架构
缩放不会改变层操作,因此,最好先有一个良好的基线网络,然后使用建议的复合缩放沿着不同的维度进行缩放。作者通过神经结构搜索(NAS)获得了他们的基本网络,该搜索对准确性和失败都进行了优化。该架构类似于M-NASNet,因为它是使用类似的搜索空间发现的。网络层/块如下图所示:
[caption id="attachment_41210" align="aligncenter" width="880"]
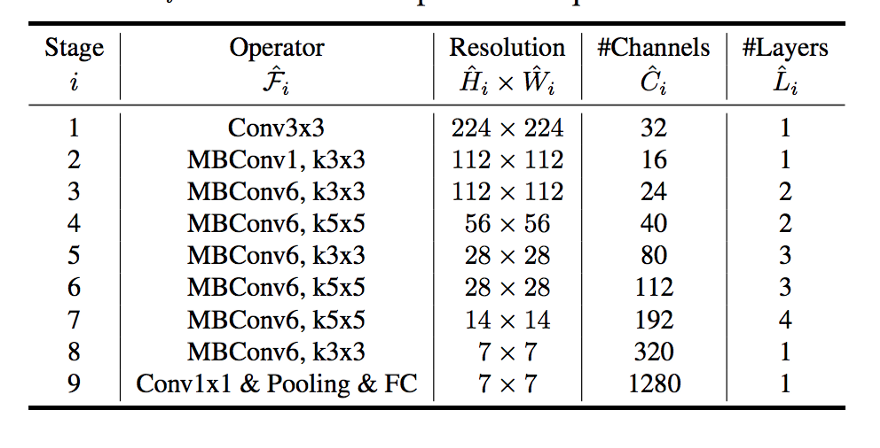 EfficientNet-B0基线网络[/caption]
EfficientNet-B0基线网络[/caption]MBConv块只是一个反向剩余块(在MobileNetV2中使用),有时注入一个挤压和激发块。
现在我们有了基本网络,我们可以为缩放参数寻找最优值。如果你回顾一下方程,你很快就会意识到,我们一共有四个参数搜索:α,β,γ,ϕ。为了缩小搜索空间,降低搜索操作的成本,可以分两步完成对这些参数的搜索。
修复ϕ= 1,假设有两个或更多的资源,做一个小网格搜索α,β,γ。基线网络B0,结果最优值α= 1.2,β= 1.1,γ= 1.15,βα*²*γ²≈2
现在修复α,β和γ常量(在以上步骤中找到的值)和尝试不同的ϕ的值实验。不同值的ϕ产生EfficientNets B1-B7。
结论
这可能是我到目前为止读过的2019年最好的论文之一。这篇论文不仅为寻找更精确的网络打开了新的大门,而且还强调了寻找更高效的架构。
虽然早期研究已经朝着这个方向发展,研究人员试图提出架构,试图减少参数和失败的数量,这样他们就可以运行在手机和边缘设备上,例如,MobileNets, ShuffleNets, M-NasNet等。在这里,我们看到了在参数减少和故障成本方面的巨大收益,以及在精确度方面的巨大收益。
本文参考
efficientnet论文:https://arxiv.org/abs/1905.11946
官方发布代码:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消