DescartesLabs:定制Kubernetes通过Envoy指标扩展

DescartesLabs运行在Kubernetes上,可扩展到数百到数万个核心,以响应客户流量。
其中大部分负载来自于我们的任务服务,它允许用户扩展分析模型,并通过高吞吐量访问千兆字节的地理空间数据。在检索、转换和交付这些数据之后,大部分繁重的工作都由我们的光栅服务处理。
扩大挑战
可以直接从我们的Python客户端或通过RESTful API调用Raster,响应时间可能因请求的性质而有很大差异。
我们最初的缩放Raster方法使用标准的水平pod自动缩放器(HPA)来跟踪每个pod的CPU利用率。不幸的是,计算特性的变化(请求可能是I / O或CPU限制)使CPU利用率成为一个糟糕的指标,我们需要一个低阈值来保持领先于负载。
请求的性质和持续时间的变化意味着基于请求率的缩放也不理想。
我们长期使用Istio并注意到基于Istio指标的自动缩放,但这些更高级别的指标(即标记的请求数,持续时间,速率)并不适合我们的服务。
利用特使指标
对我们来说幸运的是,Istio使用的边车代理Envoy允许我们直接测量我们的Raster服务的当前饱和度。
通过汇总所有Raster pod中的upstream_rq_active,我们可以有效地衡量我们的服务当前处理的请求数量。
为了让Kubernetes能够扩展这个指标,我们安装了由Stefan Prodan打包的Zalando kube-metric-adapter。我们可以在技术上配置度量标准适配器,以使用JSON统计端点直接从Envoy中获取此度量标准,但让我们现有的Prometheus基础架构处理抓取和聚合更有意义。
Prometheus配置
在Prometheus这个度量为:
envoy_cluster_upstream_rq_active
envoy_cluster_upstream_cx_active
不幸的是,Istio捆绑了Prometheus配置,但是这个数字下降了。要保留它,您必须修改或删除Prometheus配置中的以下行。
- source_labels:[cluster_name]
regex:'(outbound | inbound | prometheus_stats)。*'
action:drop
实施我们的定制自动定标器
随着Prometheus跟踪每个pod的活动请求数量,我们可以实现我们的自定义HPA:
apiVersion:autoscaling / v2beta1
种类:HorizontalPodAutoscaler
元数据:
name:raster-release
命名空间:raster
注释:
metric-config.object.raster-release-rq-active.prometheus / per-replica:“true”
metric-config.object.raster -释放- RQ-active.prometheus /查询:| sum(max_over_time(envoy_cluster_upstream_rq_active {app =“raster”,cluster_name =“inbound | 8000 || raster-release.raster.svc.cluster.local”,namespace =“raster”,stage =“release”} [1m]))
spec:
maxReplicas:1500
minReplicas:12
scaleTargetRef:
apiVersion:apps / v1
kind:部署
名称:raster-release
metrics:
- type:
metricName:raster-release-rq-active
target:
apiVersion:v1
kind:Pod
name:raster-release#架构一致性需要
targetValue:2
此HPA配置的关键部分是注释块,我们在其中:
- 为指标提供一致的标签:
raster-release-rq-active - 告诉度量标准适配器根据pod数量标准化度量标准:
per-replica: “true" - 提供PromQL查询,该查询返回最后一分钟每个Raster pod 的最大活动请求数之和。
Raster可以处理每个pod的四个并发请求,因此我们将targetValue设置为每个pod两个活动请求。
在我们的小规模测试中,我们发现只需envoy_cluster_upstream_rq_active获得准确数字的总和,但是当我们测试生产流量(yay for Istio流量镜像!)和大量的pod时,我们需要使用至少一分钟的窗口获得一致的数字。
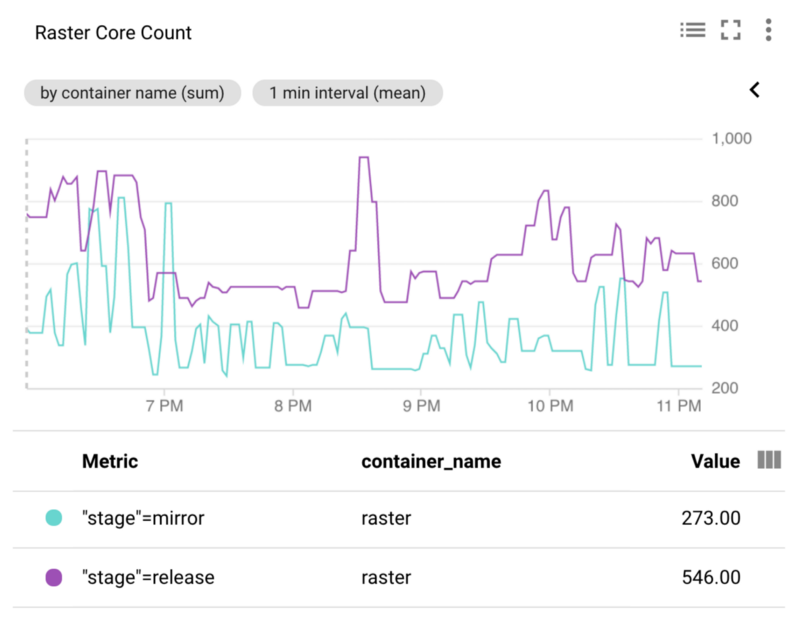
作用
如下图所示,我们的RQ-Active HPA大约将所需资源减半。即使考虑到Prometheus刮削特使和查询Prometheus的度量适配器之间引入的延迟,我们仍然可以得到更多的响应缩放比使用CPU的利用率,从而在整体上较低的503速度。一旦我们将定制的HPA应用于生产中,我们就看到了这种趋势。