











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用StyleGAN生成“权力的游戏”人物(下)
2019年05月22日 由 sunlei 发表
913493
0
昨天的文章中我们借由《权利的游戏》讲了生成式对抗网络,会不会引起你的兴趣呢?
传送门:用StyleGAN生成“权力的游戏”人物(上)
本文目录
深度学习领域发展迅速,自2014年以来,在《权力的游戏》中,与粉丝喜爱的角色死亡相比,更多的是GAN的创新。
因此,即使您使用了我在上面讨论过的出色的GAN培训框架,生成的图像最多也只是像灰色油炸牛油果一样的东西。
要真正使GANs在实践中工作,我们需要使用一套巧妙的技术。
如果你想征服GANseteros的七个王国,GitHub repo列出了过去几年大多数关键的GAN创新(GANnovations?)然而,令人印象深刻的是,除非你有像伊蒙·坦格利安一样多的时间,否则你可能连看完一半的时间都做不到。

因此,我将只关注一个特定模型的关键方面—StyleGAN。
Nvidia的研究小组提出了StyleGAN在2018年底,而不是试图创建一个花哨的新技术来稳定GAN训练或引进一个新的架构,该论文称他们的技术是“正交于正在进行的关于GaN损失函数、正则化和超参数的讨论”。
这意味着,在2045年,当人类发明了超级巨大的、疯狂的BigGAN时,我将要展示的东西仍然有效。

现在这已经足够了。我来告诉你为什么Stylegan不会浪费你的时间。
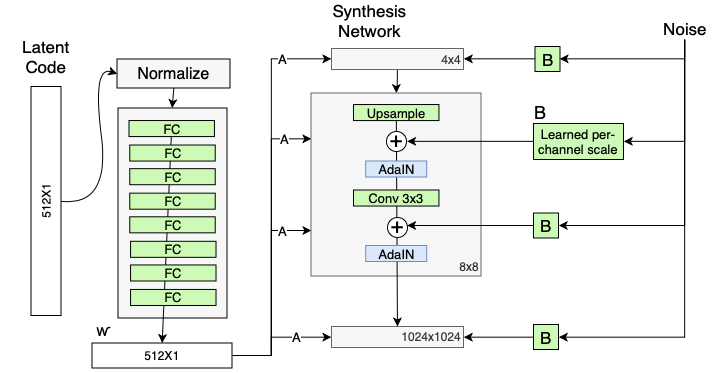
映射网络
一般来说,GAN中的生成器网络会接受一个随机向量作为输入,并使用转置卷积将这个随机向量变形为一个真实的图像,就像我在上面展示的那样。
这个随机向量叫做潜向量。
潜在向量有点像图像的样式说明。它描述了它想要生成器绘制的图片类型。
如果你在向法医描述一个潜在的罪犯,你会告诉他/她一些嫌疑人的“特征”,比如头发的颜色、面部毛发和眼睛之间的距离。

唯一的问题是,神经网络无法理解“头发颜色、面部毛发和眼睛之间的距离”。“他们只理解CUDATensors和FP16s。
潜在向量是神经网络语言对图像的高级描述。
如果你想生成一个新的图像,你必须选择一个新的向量,这是有意义的-改变输入,你改变输出。
但是,如果您想要对图像的样式有很好的控制,那么这就不是很好。由于无法控制生成器如何选择对可能的潜在向量进行分布建模,因此无法精确控制最终图像的样式。
由于GAN学习将潜在向量映射到图像的方法,所以出现了这个问题。GAN可能不太高兴符合人类规范。
你可以试着改变你生成的脸的头发颜色,只需在潜在向量中轻推一个数字,但是输出可能有眼镜,不同的肤色,甚至可能是不同的性别。
这个问题叫做特征纠缠。StyleGAN的目标是减少它。
理想情况下,我们希望有一个更整洁的潜在空间表示。它允许我们对输入的潜在向量做一些小的修改,而不会使输出的图像/人脸看起来有很大的不同。
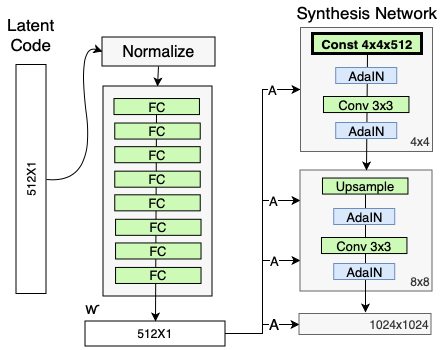
StyleGAN试图做到这一点的方法是包括将输入向量映射到GaN使用的第二中间潜在向量的神经网络。
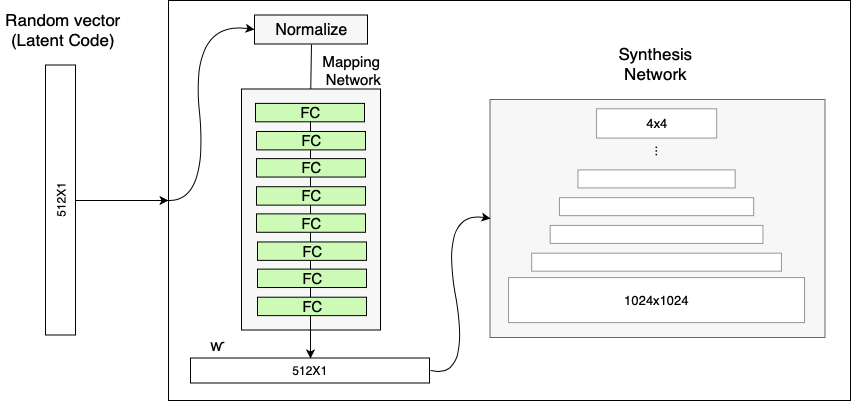
具体来说,Nvidia选择使用8层网络,输入512维矢量,输出512维矢量。但是,请注意,这些选择是任意的,如果需要,您可以使用超参数。
假设,添加这个神经网络来创建一个中间的潜在向量,将允许GAN找出它想要如何使用向量中的数字,我们通过专用的密集层喂给它,而不是试图找出如何直接从转置卷积中使用潜在向量。
映射网络应该减少特性纠缠(关于为什么这不仅仅是浪费宝贵的计算的完整讨论,我建议您阅读官方StyleGAN论文)。
如果这个想法对你来说不是很直观,不要担心。重要的是,通过整个“微型神经网络将输入向量映射到中间潜在向量”的工作很好,所以我们宁愿这样做。
现在我们有了一个映射网络,可以更有效地利用潜在空间。太好了。但是我们还可以做很多工作来更好的控制它。
自适应实例规范化(AdaIN)
回到法医类比,想想描述嫌疑人的过程。
你不会这样说:“嘿,有个长着大红胡子的瘦高个儿。他抢劫了一家银行之类的。不过,不管怎么说,我要赶一个电视节目,所以我晚些时候再去找你,警官们,祝你们玩得愉快。”
[caption id="attachment_40541" align="aligncenter" width="5009"] 不,你会呆一会儿去描述嫌疑犯,等法医画出草图,提供更多细节,然后循环继续,直到你们两个可以合作,达到对嫌疑犯面部的精确再现。[/caption]
不,你会呆一会儿去描述嫌疑犯,等法医画出草图,提供更多细节,然后循环继续,直到你们两个可以合作,达到对嫌疑犯面部的精确再现。[/caption]
换句话说,你,功能和信息的来源(即潜在的向量),会不断地将信息注入艺术家,即将描述呈现为可见的、有形的东西的人(即生成器)。
然而,在传统的GANs公式中,潜在的向量并没有“停留足够长的时间”。“一旦你把潜在向量作为输入输入到生成器中,它就再也不会被使用了,这相当于你打包走人。”
StyleGAN模型解决了这个问题,它所做的正是您所期望的——它使潜在的向量“逗留”的时间更长。通过在每一层将潜在向量注入生成器,生成器可以不断地引用“样式指南”,就像法医可以不断地问您问题一样。

现在,让我们进入技术难题。
在类比的世界里,这一切都是简单明了的,但无礼的电视迷和骨瘦如柴的红胡子银行劫匪不会转化为数学方程式。
“那么StyleGAN究竟是如何在每一层将潜在向量注入生成器的呢?”您可能会问。
“自适应实例规范化”,我将非常客气地回答。
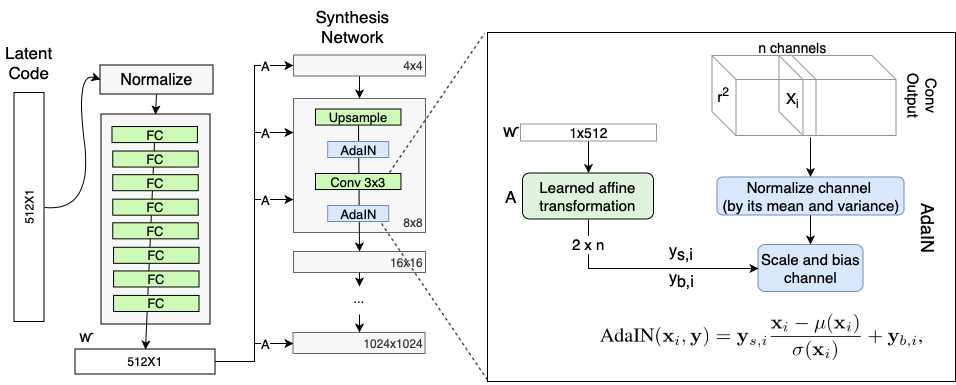
AdaIN(归一化自适应实例;来吧,我真的需要扩展它吗)是一种技术,最初用于样式转换,但后来发展成为StyleGAN。
AdaIn使用了一个线性层(在原文中更准确地称为“学习仿射变换”),它将潜在向量映射到两个标量上,我们将其称为Ys和Yb。
“s”代表比例,“b”代表偏差。
一旦你有了这些标量,下面是你如何执行AdaIN:
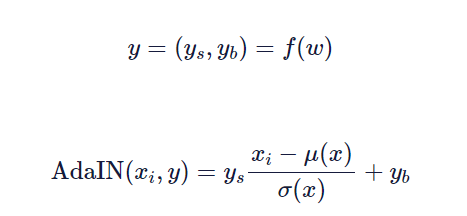
在这里,f(w)表示一个已知仿射变换,Xi是我们应用AdaIN的一个实例,和y是两个标量的集合,(Ys和Yb)控制生成图像的“样式”。
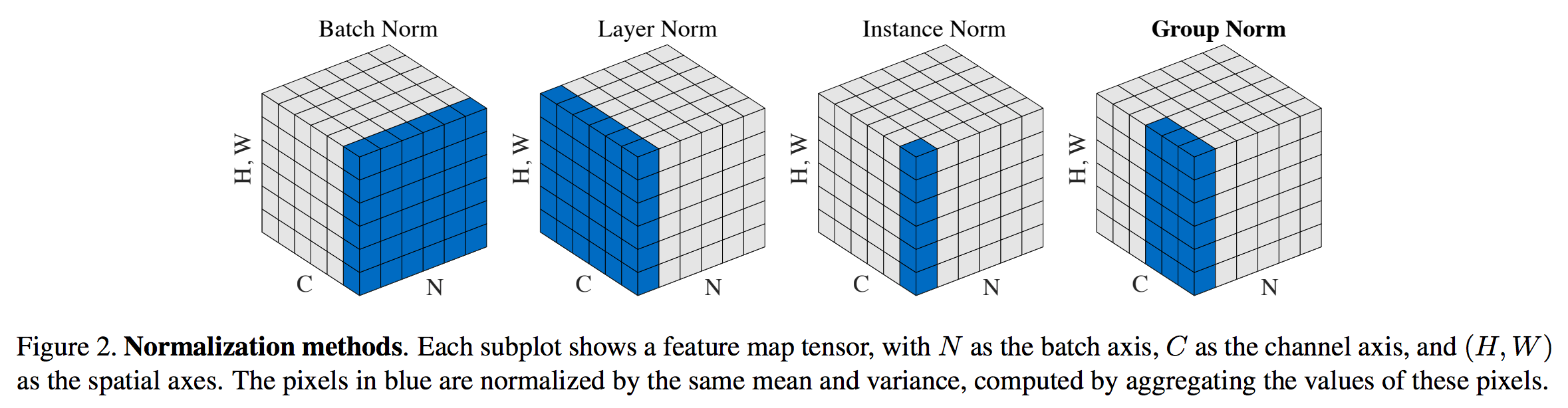
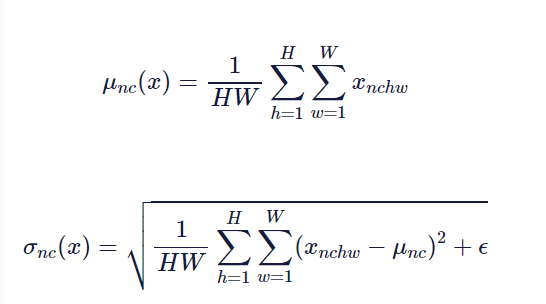
如果您以前使用过BatchNorm,这看起来可能很熟悉,这是有意的。然而,一个关键的区别是,平均值和方差是按每个通道和每个样本计算的,而不是按整个微型批处理计算的,如下所示:
这种将样式注入生成器隐藏层的方法乍一看可能有些奇怪,但最近的研究表明,控制增益和偏置参数(即,i.e., Ys和Yb次序排列)在隐层激活时,样式转换图像的质量会受到很大的影响。所以继续吧。
通过进行所有这些标准化的工作,我们能够以比仅仅使用输入潜在向量更好的方式将样式信息注入生成器。
生成器现在有了一种“描述”,它需要构造什么样的图像(多亏了映射网络),而且它还可以随时引用这种描述(多亏了AdaIN)。
但我们还可以做得更多。
学习常数输入
如果你曾经尝试过“用5个简单的步骤画出迪斯尼人物”,但毫无疑问都失败了,你就会知道这些步骤都是从那个令人毛骨悚然的苗条男人轮廓开始的。
注意,您可以使用相同的基线骨架创建一组不同的角色面孔,然后慢慢地添加更精细的细节。
同样的想法也适用于法医。他/她可能对人脸的大致样子有一个相当不错的概念,即使你根本没有说明任何细节。
回想一下,在传统的GAN生成网络中,我们输入一个潜在向量作为输入,然后使用转置卷积将这个潜在向量映射到图像。
我们需要这个潜在向量的原因是我们可以在生成的图像中提供变化。通过采样不同的向量,我们得到了不同的图像。
如果我们用一个恒定向量把它映射到一个图像,我们每次都会得到相同的图像。那会很无聊的。

然而,在StyleGAN中,我们已经有了另一种将风格信息放入生成器的方法——AdaIN。
那么,当我们能够学习它的时候,为什么我们甚至需要一个随机向量作为输入呢?结果我们没有。
你看,在常规GAN中,变化和风格数据的唯一来源是输入潜在向量,我们再也不会接触到它了。但是,正如我们在前一节中看到的,这是相当奇怪和低效的,因为生成器不能再次“看到”潜在向量。
StyleGAN通过自适应实例范数将潜在向量“注入”到每一层中,解决了许多问题,从而纠正了这一错误。这还有另一个副作用——我们不需要从一个随机向量开始,我们可以学习一个向量,因为任何可以提供的信息都将由AdaIN提供。
更具体地说,StyleGAN选择了一个已知的常量输入4×4×512张量可以认为是4×4图像,512 个通道。再次注意,这些维度完全是任意的,您可以在实践中使用任何您想使用的维度。
这背后的原理和迪士尼公主画圈的原理是一样的——生成器可以学习一些关于所有图像的标准“骨架”的概念,这样它就可以从蓝图开始,而不是从零开始。
所以在很大程度上,你们已经知道了。这是StyleGAN。在实践中,还有一些其他的技巧可以让生成的图像看起来更真实。
如果你不是很关心这些细节,祝贺你!现在你明白了,在整个宇宙中,一个最有创新精神的人对GANs的看法是什么?(GANiverse吗?天哪,我真的不应该说这些双关语了)。
但如果你想要绝佳的照片,看看琼恩和丹妮莉丝的孩子长什么样,继续读下去。
混合风格
还记得我是怎么告诉你们的吗?
如果我们不只是注入一个潜在向量,而是两个呢?
想一想。我们的生成器中有很多置换卷积和AdaIN层(在Nvidia的实现中有18层,但这完全是任意的)。在每个AdaIN层,我们独立地注入一个潜在的向量。
因此,如果注入到每一层是独立的,我们可以把不同的注入到不同的层。
如果你认为那是个好主意,那么,Nvidia 也这么认为。利用他们的奇思妙的图形处理器,该团队尝试使用不同层次的不同“人”对应的不同潜在用户。
这个实验是这样设置的:取3个不同的潜在向量,当单独使用时,将产生3个真实的人脸。
然后,他们将这些向量注入三个不同的点:
你可能会想,“哦,天哪,这些精细的层确实占据了大部分的层。从64到1024?这太多了。间距不是应该更均匀些吗?”
好吧,其实不是。如果您阅读过ProGAN的论文,您就会知道生成器可以快速获取信息,较大的层主要对前一层的输出进行细化和锐化。
然后,他们试着把这三个潜在的矢量从最初的点移动一点,看看得到的图像在质量上是如何变化的。
结果如下:
[playlist type="video" ids="40551"]
结果非常准确,令人毛骨悚然。但是,嘿,它是有效的。
随机噪声
在Nvidia 用StyleGAN做了那么多很酷的事情之后,很抱歉我让你们失望了,没有把最好的留到最后。
在制作了假脸,甚至以新颖的方式混合后,如果你发现了一张你喜欢的脸呢?
您可以生成100个相同图像的副本,但是这将非常枯燥。
所以,我们希望有一些相同图像的变化。也许是发型略有不同的变体,或者是更多的雀斑。像这样的小变化。

当然,你也可以用普通的GAN方法,在潜在向量中加入一些噪声,就像这样:
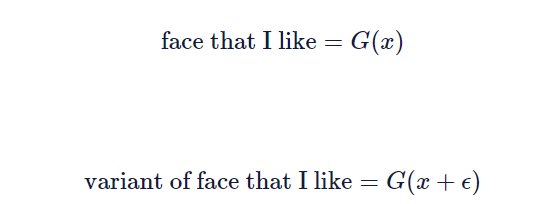
G是发生器,和ϵ是一个随机采样的向量的分量很小的数字。
但我们有StyleGAN,顾名思义,我们可以控制图像样式。
就像我们对潜在向量进行分层注入一样,我们也可以对噪声进行分层注入。我们可以选择在粗糙层、中间层、精细层或三者的任意组合上添加噪声。
在本文中,StyleGAN噪声是逐像素添加的,这是有意义的,因为这是历史上最常见和自然的添加噪声的方式,而不是干扰潜在的向量。
在噪音的影响下产生了一些有趣的风格效果(上帝,这篇文章的魅力会结束吗?)
在创作《权力的游戏》角色时,我不喜欢噪音,因为我只想创作一些高质量的图像。但很高兴看到研究团队已经考虑过这个问题。
塑造你最喜欢的《权力的游戏》角色
既然你已经了解了StyleGAN是如何运作的,那么是时候做你们一直期待的事情了——预测琼恩和丹妮莉丝的儿子/女儿会是什么样子。
废话不多说,我向大家介绍一下Djonerys,(根据二者的名字结合而来,机智吧?):
[caption id="attachment_40555" align="aligncenter" width="512"] 如果你不知道,Djonerys就是右下角的那个人[/caption]
如果你不知道,Djonerys就是右下角的那个人[/caption]
您正在查看的未来领域的保护者是使用前面讨论过的混合风格技术生成的。
最后,在与维斯特洛英雄一起庆祝8周年之际,让我们向琼恩·雪诺这些年来的成长致敬。

一旦你对角色有了潜在的特征有了了解,你还可以做很多其他的事情,比如创造一个孩子卓戈·卡奥或者把詹姆变成一个女人。
权游中你最喜欢谁?最想尝试谁的反性别角色?现在,放手尝试吧,七大帝国尽在你手。
传送门:用StyleGAN生成“权力的游戏”人物(上)
本文目录
- StyleGAN
- 映射网络
- 自适应实例规范化(AdaIN)
- 学习常数输入
- 混合风格
- 随机噪声
- 塑造你最喜欢的《权力的游戏》角色
StyleGAN
深度学习领域发展迅速,自2014年以来,在《权力的游戏》中,与粉丝喜爱的角色死亡相比,更多的是GAN的创新。
因此,即使您使用了我在上面讨论过的出色的GAN培训框架,生成的图像最多也只是像灰色油炸牛油果一样的东西。
要真正使GANs在实践中工作,我们需要使用一套巧妙的技术。
如果你想征服GANseteros的七个王国,GitHub repo列出了过去几年大多数关键的GAN创新(GANnovations?)然而,令人印象深刻的是,除非你有像伊蒙·坦格利安一样多的时间,否则你可能连看完一半的时间都做不到。
因此,我将只关注一个特定模型的关键方面—StyleGAN。
Nvidia的研究小组提出了StyleGAN在2018年底,而不是试图创建一个花哨的新技术来稳定GAN训练或引进一个新的架构,该论文称他们的技术是“正交于正在进行的关于GaN损失函数、正则化和超参数的讨论”。
这意味着,在2045年,当人类发明了超级巨大的、疯狂的BigGAN时,我将要展示的东西仍然有效。
现在这已经足够了。我来告诉你为什么Stylegan不会浪费你的时间。
映射网络
一般来说,GAN中的生成器网络会接受一个随机向量作为输入,并使用转置卷积将这个随机向量变形为一个真实的图像,就像我在上面展示的那样。
这个随机向量叫做潜向量。
潜在向量有点像图像的样式说明。它描述了它想要生成器绘制的图片类型。
如果你在向法医描述一个潜在的罪犯,你会告诉他/她一些嫌疑人的“特征”,比如头发的颜色、面部毛发和眼睛之间的距离。
唯一的问题是,神经网络无法理解“头发颜色、面部毛发和眼睛之间的距离”。“他们只理解CUDATensors和FP16s。
潜在向量是神经网络语言对图像的高级描述。
如果你想生成一个新的图像,你必须选择一个新的向量,这是有意义的-改变输入,你改变输出。
但是,如果您想要对图像的样式有很好的控制,那么这就不是很好。由于无法控制生成器如何选择对可能的潜在向量进行分布建模,因此无法精确控制最终图像的样式。
由于GAN学习将潜在向量映射到图像的方法,所以出现了这个问题。GAN可能不太高兴符合人类规范。
你可以试着改变你生成的脸的头发颜色,只需在潜在向量中轻推一个数字,但是输出可能有眼镜,不同的肤色,甚至可能是不同的性别。
这个问题叫做特征纠缠。StyleGAN的目标是减少它。
理想情况下,我们希望有一个更整洁的潜在空间表示。它允许我们对输入的潜在向量做一些小的修改,而不会使输出的图像/人脸看起来有很大的不同。
StyleGAN试图做到这一点的方法是包括将输入向量映射到GaN使用的第二中间潜在向量的神经网络。
具体来说,Nvidia选择使用8层网络,输入512维矢量,输出512维矢量。但是,请注意,这些选择是任意的,如果需要,您可以使用超参数。
假设,添加这个神经网络来创建一个中间的潜在向量,将允许GAN找出它想要如何使用向量中的数字,我们通过专用的密集层喂给它,而不是试图找出如何直接从转置卷积中使用潜在向量。
映射网络应该减少特性纠缠(关于为什么这不仅仅是浪费宝贵的计算的完整讨论,我建议您阅读官方StyleGAN论文)。
如果这个想法对你来说不是很直观,不要担心。重要的是,通过整个“微型神经网络将输入向量映射到中间潜在向量”的工作很好,所以我们宁愿这样做。
现在我们有了一个映射网络,可以更有效地利用潜在空间。太好了。但是我们还可以做很多工作来更好的控制它。
自适应实例规范化(AdaIN)
回到法医类比,想想描述嫌疑人的过程。
你不会这样说:“嘿,有个长着大红胡子的瘦高个儿。他抢劫了一家银行之类的。不过,不管怎么说,我要赶一个电视节目,所以我晚些时候再去找你,警官们,祝你们玩得愉快。”
[caption id="attachment_40541" align="aligncenter" width="5009"]
不,你会呆一会儿去描述嫌疑犯,等法医画出草图,提供更多细节,然后循环继续,直到你们两个可以合作,达到对嫌疑犯面部的精确再现。[/caption]换句话说,你,功能和信息的来源(即潜在的向量),会不断地将信息注入艺术家,即将描述呈现为可见的、有形的东西的人(即生成器)。
然而,在传统的GANs公式中,潜在的向量并没有“停留足够长的时间”。“一旦你把潜在向量作为输入输入到生成器中,它就再也不会被使用了,这相当于你打包走人。”
StyleGAN模型解决了这个问题,它所做的正是您所期望的——它使潜在的向量“逗留”的时间更长。通过在每一层将潜在向量注入生成器,生成器可以不断地引用“样式指南”,就像法医可以不断地问您问题一样。
现在,让我们进入技术难题。
在类比的世界里,这一切都是简单明了的,但无礼的电视迷和骨瘦如柴的红胡子银行劫匪不会转化为数学方程式。
“那么StyleGAN究竟是如何在每一层将潜在向量注入生成器的呢?”您可能会问。
“自适应实例规范化”,我将非常客气地回答。
AdaIN(归一化自适应实例;来吧,我真的需要扩展它吗)是一种技术,最初用于样式转换,但后来发展成为StyleGAN。
AdaIn使用了一个线性层(在原文中更准确地称为“学习仿射变换”),它将潜在向量映射到两个标量上,我们将其称为Ys和Yb。
“s”代表比例,“b”代表偏差。
一旦你有了这些标量,下面是你如何执行AdaIN:
在这里,f(w)表示一个已知仿射变换,Xi是我们应用AdaIN的一个实例,和y是两个标量的集合,(Ys和Yb)控制生成图像的“样式”。
如果您以前使用过BatchNorm,这看起来可能很熟悉,这是有意的。然而,一个关键的区别是,平均值和方差是按每个通道和每个样本计算的,而不是按整个微型批处理计算的,如下所示:
这种将样式注入生成器隐藏层的方法乍一看可能有些奇怪,但最近的研究表明,控制增益和偏置参数(即,i.e., Ys和Yb次序排列)在隐层激活时,样式转换图像的质量会受到很大的影响。所以继续吧。
通过进行所有这些标准化的工作,我们能够以比仅仅使用输入潜在向量更好的方式将样式信息注入生成器。
生成器现在有了一种“描述”,它需要构造什么样的图像(多亏了映射网络),而且它还可以随时引用这种描述(多亏了AdaIN)。
但我们还可以做得更多。
Learned Constant Input
学习常数输入
如果你曾经尝试过“用5个简单的步骤画出迪斯尼人物”,但毫无疑问都失败了,你就会知道这些步骤都是从那个令人毛骨悚然的苗条男人轮廓开始的。
注意,您可以使用相同的基线骨架创建一组不同的角色面孔,然后慢慢地添加更精细的细节。
同样的想法也适用于法医。他/她可能对人脸的大致样子有一个相当不错的概念,即使你根本没有说明任何细节。
回想一下,在传统的GAN生成网络中,我们输入一个潜在向量作为输入,然后使用转置卷积将这个潜在向量映射到图像。
我们需要这个潜在向量的原因是我们可以在生成的图像中提供变化。通过采样不同的向量,我们得到了不同的图像。
如果我们用一个恒定向量把它映射到一个图像,我们每次都会得到相同的图像。那会很无聊的。
然而,在StyleGAN中,我们已经有了另一种将风格信息放入生成器的方法——AdaIN。
那么,当我们能够学习它的时候,为什么我们甚至需要一个随机向量作为输入呢?结果我们没有。
你看,在常规GAN中,变化和风格数据的唯一来源是输入潜在向量,我们再也不会接触到它了。但是,正如我们在前一节中看到的,这是相当奇怪和低效的,因为生成器不能再次“看到”潜在向量。
StyleGAN通过自适应实例范数将潜在向量“注入”到每一层中,解决了许多问题,从而纠正了这一错误。这还有另一个副作用——我们不需要从一个随机向量开始,我们可以学习一个向量,因为任何可以提供的信息都将由AdaIN提供。
更具体地说,StyleGAN选择了一个已知的常量输入4×4×512张量可以认为是4×4图像,512 个通道。再次注意,这些维度完全是任意的,您可以在实践中使用任何您想使用的维度。
这背后的原理和迪士尼公主画圈的原理是一样的——生成器可以学习一些关于所有图像的标准“骨架”的概念,这样它就可以从蓝图开始,而不是从零开始。
所以在很大程度上,你们已经知道了。这是StyleGAN。在实践中,还有一些其他的技巧可以让生成的图像看起来更真实。
如果你不是很关心这些细节,祝贺你!现在你明白了,在整个宇宙中,一个最有创新精神的人对GANs的看法是什么?(GANiverse吗?天哪,我真的不应该说这些双关语了)。
但如果你想要绝佳的照片,看看琼恩和丹妮莉丝的孩子长什么样,继续读下去。
混合风格
还记得我是怎么告诉你们的吗?
如果我们不只是注入一个潜在向量,而是两个呢?
想一想。我们的生成器中有很多置换卷积和AdaIN层(在Nvidia的实现中有18层,但这完全是任意的)。在每个AdaIN层,我们独立地注入一个潜在的向量。
因此,如果注入到每一层是独立的,我们可以把不同的注入到不同的层。
如果你认为那是个好主意,那么,Nvidia 也这么认为。利用他们的奇思妙的图形处理器,该团队尝试使用不同层次的不同“人”对应的不同潜在用户。
这个实验是这样设置的:取3个不同的潜在向量,当单独使用时,将产生3个真实的人脸。
然后,他们将这些向量注入三个不同的点:
- 在“粗糙”层中,隐藏表示在空间上很小的层从4×4到8×8;
- 在“中等”层,其中隐藏的表示是中等大小的层-从16×16到32×32;
- 在“精细”层中,隐藏的表示在空间上很小从64×64到1024×1024。
你可能会想,“哦,天哪,这些精细的层确实占据了大部分的层。从64到1024?这太多了。间距不是应该更均匀些吗?”
好吧,其实不是。如果您阅读过ProGAN的论文,您就会知道生成器可以快速获取信息,较大的层主要对前一层的输出进行细化和锐化。
然后,他们试着把这三个潜在的矢量从最初的点移动一点,看看得到的图像在质量上是如何变化的。
结果如下:
[playlist type="video" ids="40551"]
结果非常准确,令人毛骨悚然。但是,嘿,它是有效的。
随机噪声
在Nvidia 用StyleGAN做了那么多很酷的事情之后,很抱歉我让你们失望了,没有把最好的留到最后。
在制作了假脸,甚至以新颖的方式混合后,如果你发现了一张你喜欢的脸呢?
您可以生成100个相同图像的副本,但是这将非常枯燥。
所以,我们希望有一些相同图像的变化。也许是发型略有不同的变体,或者是更多的雀斑。像这样的小变化。
当然,你也可以用普通的GAN方法,在潜在向量中加入一些噪声,就像这样:
G是发生器,和ϵ是一个随机采样的向量的分量很小的数字。
但我们有StyleGAN,顾名思义,我们可以控制图像样式。
就像我们对潜在向量进行分层注入一样,我们也可以对噪声进行分层注入。我们可以选择在粗糙层、中间层、精细层或三者的任意组合上添加噪声。
在本文中,StyleGAN噪声是逐像素添加的,这是有意义的,因为这是历史上最常见和自然的添加噪声的方式,而不是干扰潜在的向量。
在噪音的影响下产生了一些有趣的风格效果(上帝,这篇文章的魅力会结束吗?)
在创作《权力的游戏》角色时,我不喜欢噪音,因为我只想创作一些高质量的图像。但很高兴看到研究团队已经考虑过这个问题。
塑造你最喜欢的《权力的游戏》角色
既然你已经了解了StyleGAN是如何运作的,那么是时候做你们一直期待的事情了——预测琼恩和丹妮莉丝的儿子/女儿会是什么样子。
废话不多说,我向大家介绍一下Djonerys,(根据二者的名字结合而来,机智吧?):
[caption id="attachment_40555" align="aligncenter" width="512"]
如果你不知道,Djonerys就是右下角的那个人[/caption]您正在查看的未来领域的保护者是使用前面讨论过的混合风格技术生成的。
最后,在与维斯特洛英雄一起庆祝8周年之际,让我们向琼恩·雪诺这些年来的成长致敬。
一旦你对角色有了潜在的特征有了了解,你还可以做很多其他的事情,比如创造一个孩子卓戈·卡奥或者把詹姆变成一个女人。
权游中你最喜欢谁?最想尝试谁的反性别角色?现在,放手尝试吧,七大帝国尽在你手。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
深度理解和可视化ResNets








广告


写评论取消
回复取消