











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用StyleGAN生成“权力的游戏”人物(上)
2019年05月21日 由 sunlei 发表
687411
0

本文目录
介绍
生成式对抗网络
- 生成器
- 鉴别器
- 本文小结
介绍
《权利的游戏》迎来了大结局,我斗胆在此问一下各位权游迷,你有没有想过如果你最喜欢的电影或电视剧中的角色性别完全不同会是什么样子?
[caption id="attachment_40456" align="aligncenter" width="979"]
 HBO电视剧《权力的游戏》中的詹姆·兰尼斯特的性别转变[/caption]
HBO电视剧《权力的游戏》中的詹姆·兰尼斯特的性别转变[/caption]不必惊讶!多亏了来自英伟达研究的尖端深度学习算法StyleGAN,你(是的,你!)也可以探索出一个充满魅力的世界,一个生机勃勃、充满敌意的维斯特洛。
StyleGAN还可以生成这样令人毛骨悚然的微笑动画:
[caption id="attachment_40457" align="aligncenter" width="480"]
 从单个图像生成的微笑动画[/caption]
从单个图像生成的微笑动画[/caption]但是别着急。在神经网络想象出Jon和Daenerys的孩子是什么样子之前(我猜,剧透警告),我们需要退后一步,明确定义我们到底需要什么来确保我们不会这样做:

如果你读过这篇文章,在生成的图像上得到Jon Snow头发的高斯曲率是目前最紧迫的问题,我将假设你至少知道卷积神经网络是如何工作的。
因为这篇文章是关于StyleGAN的(以及弄清楚Jon和Daenerys的孩子会是什么样子),所以我只提供了GAN框架的一个表面概述。
如果你想深入GAN领域,请查看Ian Goodfellow的NIPS 2016教程。这是学习GAN最好的资源之一,由GAN之父亲自教授。
话说到这,让我们开始吧。
生成式对抗网络
大多数人喜欢用假币制造者和警察的类比来解释GANs。
然而,我不认为这是看待GANs最令人兴奋的方式,尤其是如果你已经被灌输了训练神经网络的狂热中。
生成性对抗网络最重要的部分,是生成图像的东西。不出所料,这部分被称为生成器。
1.生成器
生成器不是一个普通的神经网络。
它使用一种特殊的层称为转置卷积层(有时错误地称为反卷积)。
转置卷积,有时也被正确地称为分数阶卷积(嘿,别问我为什么,我不是想出这些名字的人),这是一波优雅的操作,可以升级图像。
要真正理解转置卷积,以及为什么深度学习社区似乎不能为这个该死的东西定一个名字,我推荐阅读 Naoki Shibuya关于这个主题的文章。
简而言之,下面这个动画总结了如何使用转置卷积将2x2矩阵提升到5x5矩阵:
[caption id="attachment_40459" align="aligncenter" width="395"]
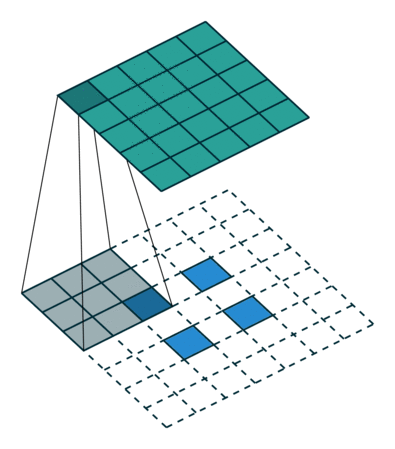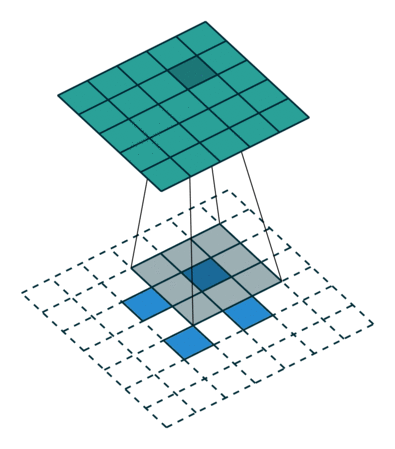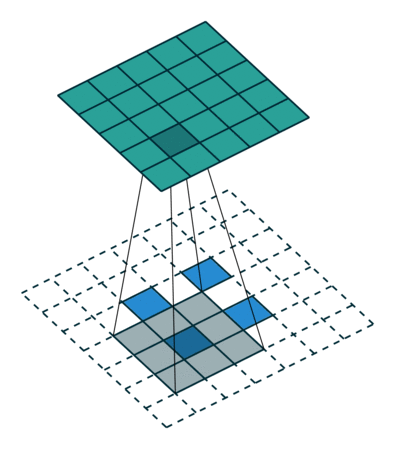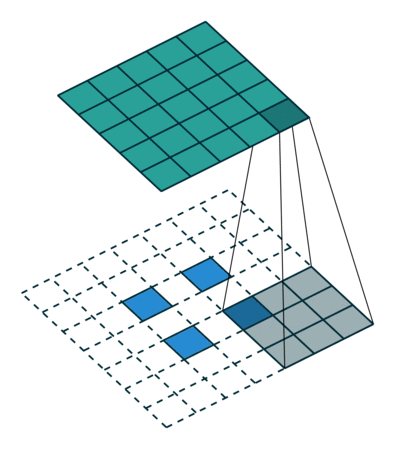 带滤波器尺寸3和跨距2的转置卷积[/caption]
带滤波器尺寸3和跨距2的转置卷积[/caption]同样,我将跳过那些血淋淋的细节,所以如果你想深入了解,你也可以看看卷积算法指南。
因为这是一个深入的学习过程,我们必须充分利用所有的行话,使其最大限度地发挥潜力,以满足潜在的投资者,我们全新的,在矩阵乘法将改变世界之前从未见过的,堆叠一堆这样的层是有意义的,以获得一个神经网络,可以将图像放大到相当大的尺寸。
因此,图像生成器的最终架构如下所示:
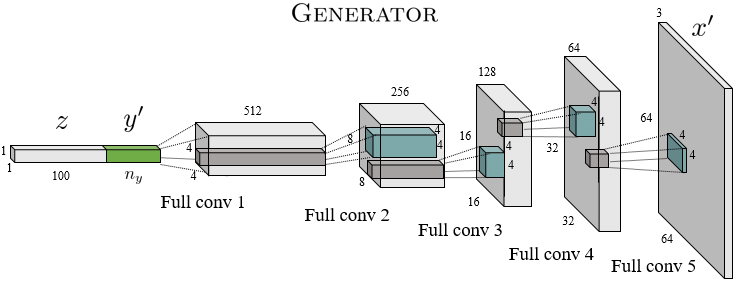
当然,如果不知道这些卷积滤波器的权重是多少,我们的生成器模型现在能做的就是输出随机噪声。真糟糕。
我们现在需要的,除了一个充满图像的硬盘,还有一个丢失功能。
我们需要一些东西来告诉我们的生成器是错是对,也就是一个老师。

对于图像分类,这种损失函数几乎是数学之神赋予我们的。因为我们是成对的图像和标签,所以我们可以这样做:

当然,根据任务的不同,你可能想要使用交叉熵损失或者类似的东西。
但我离题了。重点是,标记数据允许我们构造一个可微分的损失函数,我们可以向下滑动(使用反向传播和梯度下降)。
我们的生成器网络也需要类似的东西。
理想情况下,适当的损失函数应该告诉我们生成的图像有多真实。因为一旦我们有了这样一个函数,我们就可以使用已知的方法(即反向传播和梯度下降)使其最大化。
不幸的是,在对数和余弦看来,Sansa Stark和高斯噪声几乎是一样的。

在图像分类的例子中,我们有一个清晰的损失数学方程,但是我们这里不能有类似的东西,因为数学不能构造一个可微分函数,它告诉我们生成的图像是真实的还是假的。
让我再说一遍:拍一张图片,然后返回一个数字,上面写着它是真的还是假的(“1”是真的,0”是假的)。
输入:图像。输出:二进制值。
你明白了吗?这不仅仅是一个损失函数,而是一个完整的神经网络。
鉴别器
毫无疑问,区分真假图像的模型被称为鉴别器。

鉴别器是一种卷积神经网络,经过训练它可以预测输入图像是真是假。如果认为图像是真实的,则输出“1”;如果认为图像是假的,则输出“0”。
因此,从生成器网络的角度来看,鉴别器起着损耗函数的作用。
如果生成器更新参数的方式使其生成的图像在通过鉴别器输入时产生接近零的值,则生成的图像看起来像三岁小孩在电视屏幕上击打棒球的结果。

最后,你的GAN应该是这样的:
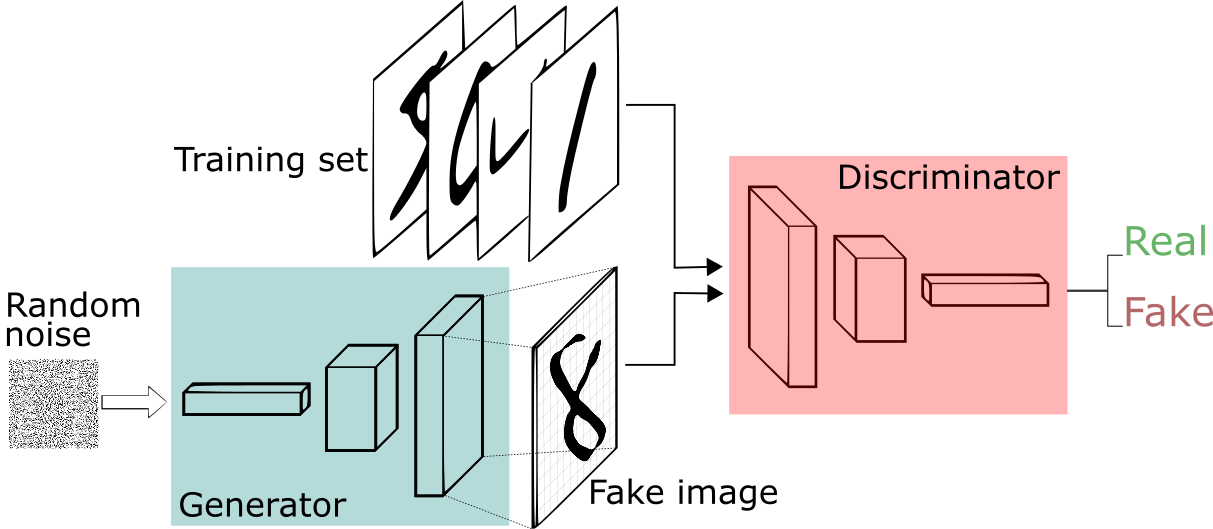
本文小结:
总而言之,下面是创建基于GaN的图像生成器的分步过程:
- 生成器(一个具有转置卷积层的神经网络)生成图像,其中大部分看起来像垃圾。
- 鉴别器采取了一堆(或更准确,小批量)的图像,其中一些是真实的(从大数据集),一些是假的(从生成器)。
- 鉴别器试图执行二进制分类来预测哪些图像是真实的(通过输出“1”),哪些图像是假的(通过输出“0”)。在这一点上,鉴别器和提利昂·兰尼斯特的弓箭一样精确。
- 鉴别器更新它的参数,以便更好地对图像进行分类。
- 生成器使用鉴别器作为一个丢失函数,并相应地更新其参数,以便更好地生成看起来足够逼真的图像来欺骗鉴别器(即使鉴别器输出数字接近“0”)。
- 游戏继续进行,直到生成器和鉴别器都达到平衡点,鉴别器再也无法区分生成器创建的图像和来自数据集的图像。
- 优雅地扔掉鉴别器,瞧,你现在有了一个生成图像的生成器,其中大部分可能看起来不像垃圾。
好了,今天我先写到这里,在下一篇里我们继续聊聊StyleGAN以及如何塑造你最喜欢的权游角色。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
决策树完全指南(下)
下一篇
深度理解和可视化ResNets








广告


写评论取消
回复取消