











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






白话机器学习算法 Part 1
2019年04月02日 由 sunlei 发表
727951
0
作为Flatiron School数据科学训练营(Data Science Bootcamp)的一名应届毕业生,我收到了大量关于如何在技术面试中取得好成绩的建议:一个不断出现在前沿的软技能是向非技术人员解释复杂机器学习算法的能力。
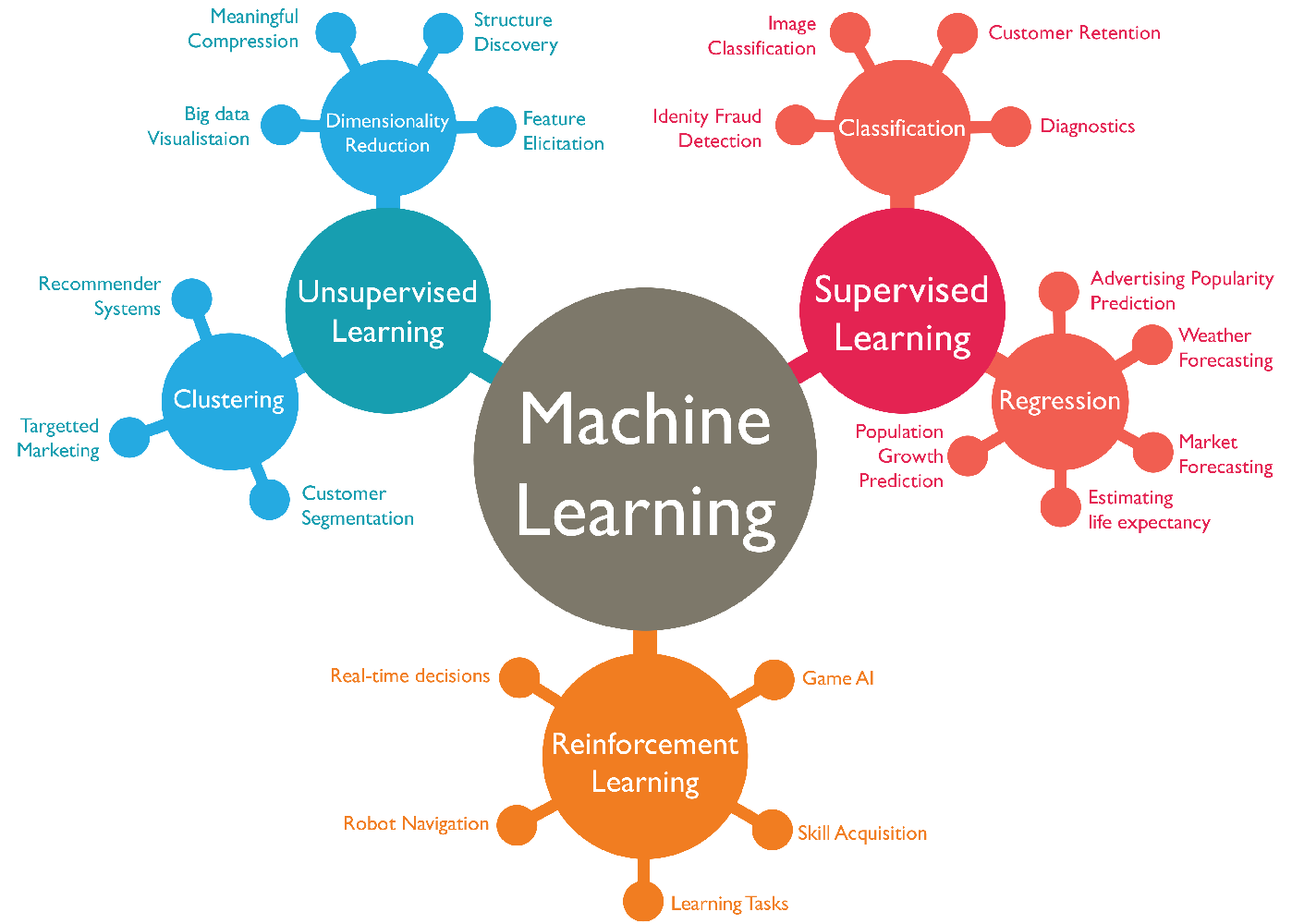
这一系列的帖子是我与世界分享我如何解释我经常遇到的所有机器学习的问题…有些比较深入,有些则不那么深入,但我认为这些都是非常有用的。第一部分的主题是:
- 梯度下降法/最佳拟合线
- 线性回归(包括正则化)
- 领回归&套索回归
在本系列接下来的部分中,我将详细介绍:
- Decision Trees
- Random Forest
- SVM
- Naive Bayes
- RNNs & CNNs
- K-NN
- K-Means
- DBScan
- Hierarchical Clustering
- Agglomerative Clustering
- eXtreme Gradient Boosting
- AdaBoost
在我们开始之前,先从Quora上这篇很棒的文章中,简单地了解一下算法和模型之间的区别:
模型就像一台自动售货机,你给它投适当的钱,它就会给你一罐汽水……算法是用来支配模型的,一个模型应该根据给定的输入做出准确的判断,已给出一个预期的输出。例如,一个算法将根据给定货币价值、您选择的产品、货币是否足够、您应该获得多少余额等等来决定。
总之,算法是模型背后的数学生命力。区分模型的是它们所使用的算法,但是如果没有模型,算法只是一个无所事事的数学方程,没有任何作用。
下面,开始!
梯度下降法/最佳拟合线Gradient Descent / Line of Best Fit
(虽然第一个算法传统上并不被认为是机器学习算法,但理解梯度下降对于理解有多少机器学习算法工作和优化是至关重要的。)
基本上,梯度下降有助于我们根据一些数据得到最准确的预测。
让我再多做些解释——假设你有一个很大的清单,上面列着你认识的每个人的身高和体重。我们把数据作成图。大概是这样的:
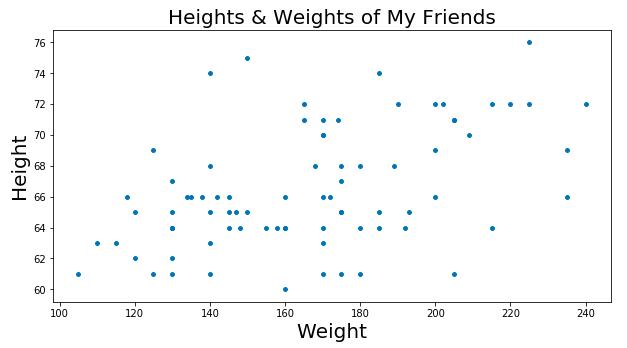
现在让我们假设有一个猜谜比赛,根据某人的身高,猜对某人的体重的人会得到一个现金奖励。除了用你的眼睛来测量这个人的体型,你还得非常依赖于你所掌握的身高和体重的清单,对吧?
所以,根据上面的数据图表,你可以做出一些比较准确预测,只要在图表上标一条线,显示数据的趋势。有了这样一条直线,如果给你一个人的身高,你可以在x轴上找到这个身高延伸,然后看看在y轴上对应的体重是多少,对吧?
但你到底是怎么找到完美的线条呢?也许你可以动手去画,但这将花费很长时间。这就是梯度下降的切入点!
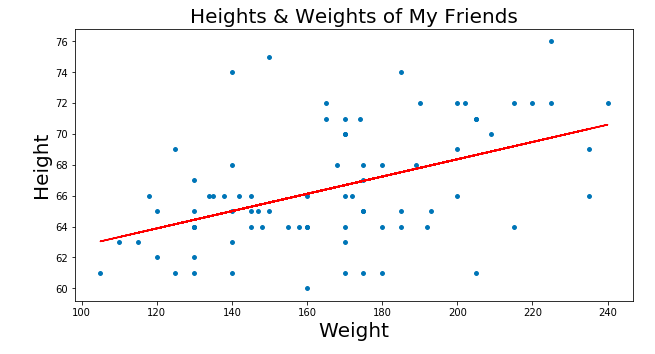
它通过最小化所谓的RSS(残差平方和)来实现这一点,RSS基本上是点与线之间差值的平方和,即实际数据(点)与线(红线)的距离。通过改变直线在图上的位置,我们得到了一个越来越小的RSS,这很直观——我们希望直线在接近大多数点的地方。
实际上,我们可以更进一步,在成本曲线上绘制每一条线的参数。使用梯度下降法,我们可以到达成本曲线的底部。在成本曲线的底部是我们最低的RSS!
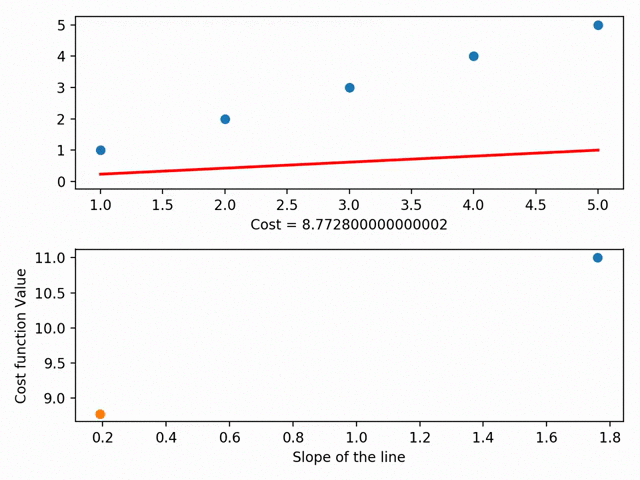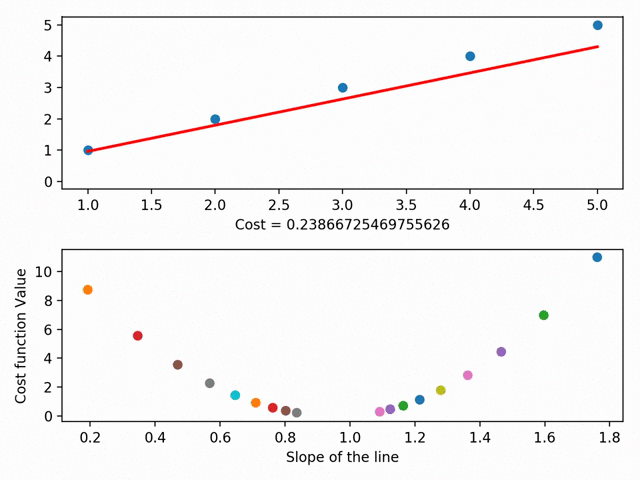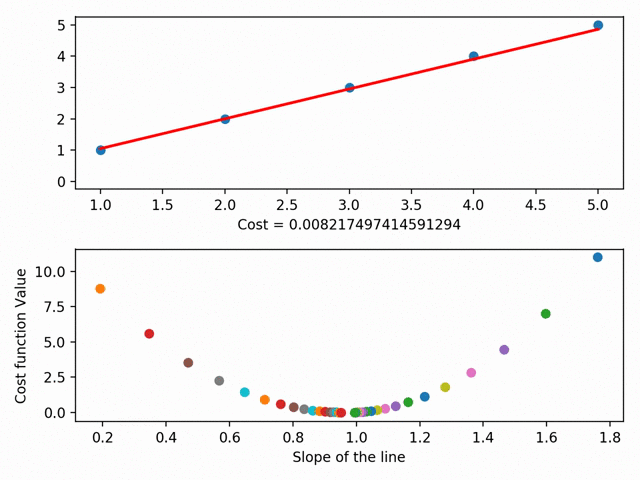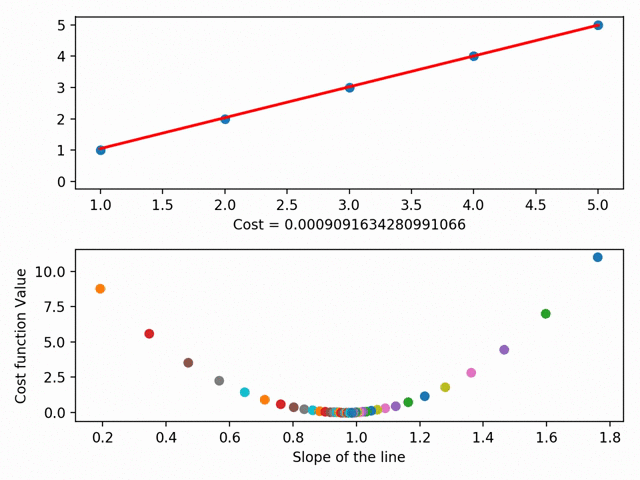
梯度下降有更多的细节方面,如“步长”(即我们想要多快地接近滑板斜坡底部)和“学习速率”(即我们想要走什么方向到达底部),但本质上:梯度下降法通过最小化之间的空间点与最适合线之间的空间来获得最佳拟合线。它就是我们的最佳匹配系列,反过来,允许我们做出准备预测!
线性回归Linear Regression
简单地说,线性回归是一种分析一个变量(我们的“结果变量”)和一个或多个其他变量(我们的“自变量”)之间关系强度的方法。
线性回归的一个特点,顾名思义,就是自变量和结果变量之间的关系是线性的。就我们的目的而言,这意味着当我们将自变量与结果变量进行比较,我们可以看到这些点开始呈现类似于直线的形状,如下图所示:
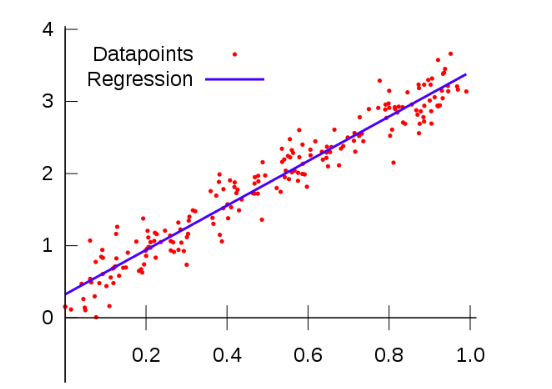
(如果你画不出你的数据,考虑线性的一个好方法就是回答这个问题:自变量的一定程度的变化会导致结果变量的相同程度的变化吗?)如果是,您的数据是线性的!)
关于线性回归,另一件需要知道的重要事情是:结果变量,或者说根据我们如何改变其他变量而改变的变量,总是连续的。但这意味着什么呢?
假设我们想测量海拔高度对纽约州降雨量的影响:我们的结果变量(或我们关注的变化)是降雨量,我们的自变量是海拔。通过线性回归,该结果变量必须具体表示降雨量为多少英寸,而不仅仅是一个表示海拔是否下雨正确/错误的类别,表明它是否在x高度下过雨。这是因为我们的结果变量必须是连续的——这意味着它可以是数字范围内的任何数字(包括分数)。
线性回归最酷的一点是,它可以使用我们之前提到的最佳拟合线来预测事物!如果我们对上面的降雨与海拔情况进行线性回归分析,我们可以像在梯度下降部分中(蓝色所示)那样找到最适合的线,然后我们可以使用该线对在某个海拔处人们可以合理预计的降雨量进行有根据的猜测。
领回归&套索回归Ridge & LASSO Regression
所以线性回归并不可怕,对吧?这只是一种方式,看看什么东西对其他东西有什么影响。酷~
既然我们已经知道了简单线性回归,我们还可以讨论更酷的线性回归,比如岭回归。
就像梯度下降与线性回归的关系一样,为了理解岭回归,我们需要讲述一个故事,那就是正则化。
简单地说,数据科学家使用正则化方法来确保他们的模型只关注对结果变量有显著影响的自变量。
您可能想知道为什么我们要关心我们的模型是否使用了没有影响的自变量。如果它们没有影响,我们的回归难道不会忽略它们吗?答案是否定的!稍后我们可以更深入地了解机器学习的细节,但是基本上我们通过给它们提供一堆“测试”数据来创建这些模型。然后,通过对一堆“测试”数据进行测试,我们可以看到我们的模型表现的有多好。因此,如果我们用一系列独立变量训练我们的模型,其中一些重要,而另一些不重要,我们的模型将在我们的训练数据上表现得非常好(因为我们欺骗它去考虑我们给它提供的所有重要信息),但是在我们的测试数据上表现得非常差。这是因为我们的模型不够灵活,无法很好地处理不完整的新数据。当这种情况发生时,我们说模型是“过拟合的”。
为了理解过度拟合,我们来看一个(冗长的)例子:
假设你是个新妈妈,你的宝宝喜欢意大利面。随着时间的推移,你习惯于在厨房窗户打开的情况下喂宝宝意大利面,因为你喜欢微风。然后你的孩子的表弟给他买了一件连体衣,你开始了一个传统,只有当他穿着特别的连体衣时,你才给他吃意大利面。然后你收养了一只狗,它常常坐在婴儿的高脚椅下,一边吃着他的意大利面一边抓着掉落的面条。在这一点上,你只能在你的宝宝穿着特别的连体衣时喂他意大利面……厨房的窗户开着……而狗就在高脚椅下面。作为一个新妈妈,你很自然地将你儿子对意大利面的热爱与所有这些特征联系在一起:打开的厨房窗户、一件连体衣和狗。现在,你对婴儿喂养习惯的思维模式相当复杂!
有一天,你要去外婆家旅行。你必须给你的宝宝吃晚饭(当然是意大利面),因为你要在这过周末。你惊慌失措,因为厨房里没有窗户,你把他的连体衣忘在家里了,狗和邻居在一起!你吓坏了,以至于忘了给你的孩子喂晚饭,就把他放在床上。
真的。当你面对一个从未面对过的情况时,你的表现相当糟糕。不过,在家里你做得很完美!这没道理!
当你重新审视你孩子的饮食习惯的思维模式,无视所有的“噪音”,或者你认为可能对你的孩子真正喜欢意大利面没有帮助的事情之后,你就会意识到唯一真正重要的是它是由你做的。
第二天晚上在外婆家,你在她没有窗户的厨房里给他喂他心爱的意大利面,而他只穿了一块尿布,没有狗可看。一切顺利!你对他为什么喜欢意大利面的想法现在简单多了。
这正是正规化可以为机器学习模型所起到的作用
因此,正则化可以帮助您的模型只关注数据中的重要内容并消除噪声。
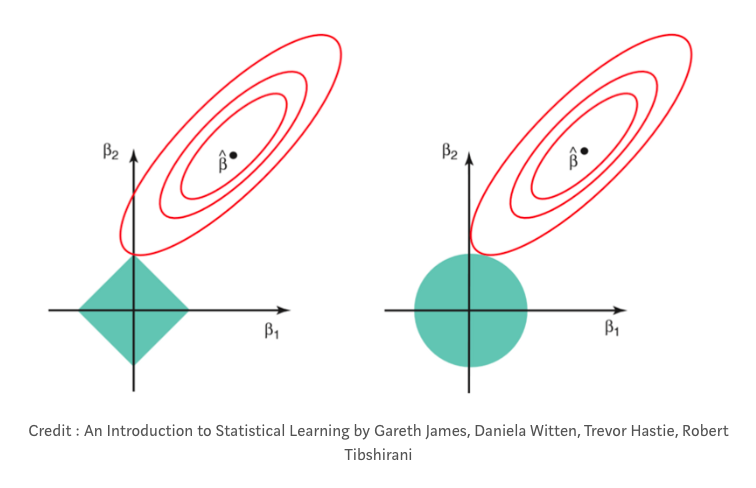
在所有类型的正则化中,都有一个称为惩罚项的词(希腊字母:λ)。这个惩罚术语在数学上缩小了我们数据中的噪声。
在岭回归中,有时被称为“L2回归”,惩罚项是变量系数的平方和。(线性回归中的系数基本上只是每个自变量的数字,这些数字告诉你每个自变量对结果变量的影响有多大。有时我们把它们称为“权重”。)在岭回归中,惩罚项缩小了自变量的系数,但实际上从来没有完全消除它们。这意味着使用岭回归,您的模型将始终考虑数据中的噪声。
另一种类型的正则化是lasso,或“L1”正则化。在lasso正则化中,只惩罚高系数特征,而不是惩罚数据中的每个特征。此外,lasso还能够将系数一直缩小到零。这基本上从数据集中删除了那些特性,因为它们现在的“权重”为零(即它们实际上乘以零)。“使用lasso回归,您的模型有可能消除数据集中的大部分噪声。这在某些情况下非常有用!
今天先更新到这里,敬请期待part2。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消