











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






研究者开发深度学习框架,训练机器人通过视频模仿人类动作
2019年03月29日 由 董灵灵 发表
906482
0
 人类可以从视频中学习新技能,那么机器人呢?这是澳大利亚机器人视觉中心等研究人员想要解决的问题,在论文“V2CNet: A Deep Learning Framework to Translate Videos to Commands for Robotic Manipulation”中,研究者描述了一个深度学习框架,将剪辑转换成自然语言命令,可用于训练半自主机器。
人类可以从视频中学习新技能,那么机器人呢?这是澳大利亚机器人视觉中心等研究人员想要解决的问题,在论文“V2CNet: A Deep Learning Framework to Translate Videos to Commands for Robotic Manipulation”中,研究者描述了一个深度学习框架,将剪辑转换成自然语言命令,可用于训练半自主机器。论文作者表示,“虽然人类可以毫不费力地理解行动并通过观察别人来模仿任务,但让机器人根据对人类活动的观察来执行行动仍然是一项重大挑战,在这项工作中,我们认为机器人必须开发两种能够复制人类活动的主要能力:理解人类行为,并模仿它们,通过了解人类行为,机器人可以获得或执行新技能。”
为此,该团队提出了针对两个任务进行优化的管道:视频字幕和动作识别。它包括一个递归神经网络翻译器步骤,该步骤从输入演示中建模视觉特征的长期依赖关系,并生成一串指令,加上一个分类分支,使用卷积网络对时间信息进行编码,以便对细粒度操作进行分类。
分类分支的输入是通过预训练的AI模型从视频帧中提取的一组特征。正如研究人员所解释的那样,翻译和分类组件的训练方式使得编码器部分鼓励翻译者生成正确的细粒度动作,使其能够理解所摄取的视频。
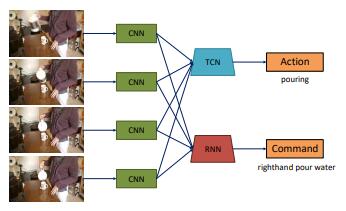
“通过联合训练两个分支,网络可以有效地编码每帧中的空间信息和跨视频时间轴的时间信息,它的输出可以与视觉和规划模块相结合,以使机器人执行不同的任务。”
为了验证该模型,研究人员创建了一个新的数据集,视频到命令(IIT-V2C),其中包括人类演示的视频,这些视频被手工分割成11000个短片(长度为2到3秒),并用一个描述当前动作的命令语句进行注释。他们使用一个工具自动从命令中提取动词,并将这个动词用作每个视频的动作类别,总共生成46个类,如切割和倾倒。
在涉及IT-V2C和不同特征提取方法以及递归神经网络的实验中,科学家称他们的模型成功地编码了每个视频的视觉特征并生成了相关命令。他们声称,它的表现也优于最先进的技术水平。
论文:
arxiv.org/pdf/1903.10869.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消