


















使用50行Python教AI玩运杆游戏
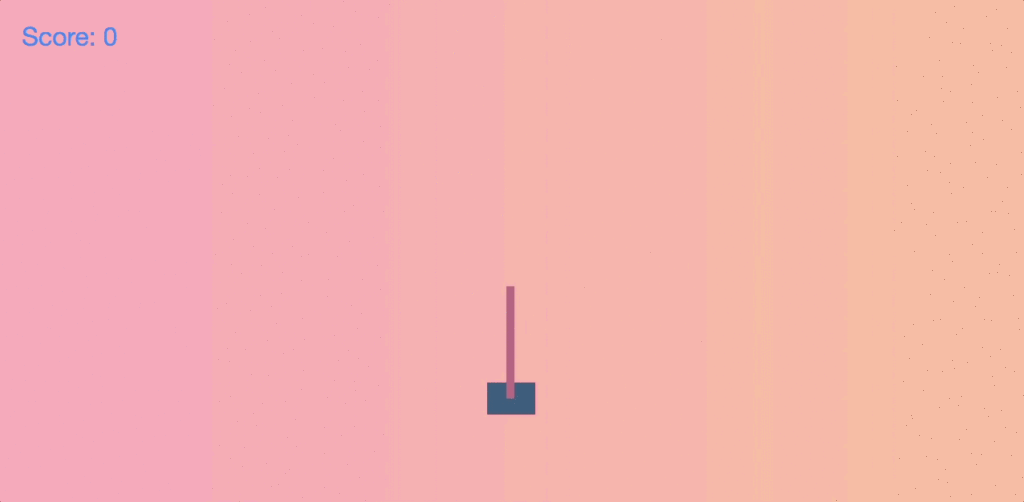
嗨,大家好!今天我想展示如何使用50行Python代码教一台机器来平衡杆!我们将使用标准的OpenAI Gym作为我们的测试环境,并只使用numpy创建我们的智能体。
运杆(cart pole)问题是我们必须左右推动小车以平衡其顶部的杆。类似于在我们的指尖上垂直平衡铅笔,只不过它只有一个维度(还是很难的!)
在我们开始之前,你可以访问repl.it上的最终演示(https://repl.it/@MikeShi42/CartPole)。
如果这是你第一次学习机器学习或强化学习,我将在这里介绍一些基础知识,这样你就可以了解我们将在这里使用的术语。否则,你可以跳过这一节!
强化学习
强化学习(RL)是在教智能体(我们的算法或者说机器人)在没有明确告诉它如何做的情况下执行某些任务或动作的研究领域。你可以想象一个婴儿,以随机的方式移动它的腿,有一次,很幸运孩子站了起来,我们会给它一个糖果或者说奖励。同样,智能体的目标是在其生命周期内最大化总奖励,我们需要决定与我们想要完成的任务相一致的奖励。比如这个站立的例子,站起来时奖励1,否则为0。
RL智能体的典型例子是AlphaGo,智能体已经学会了如何玩围棋获取最大奖励(赢得游戏)。在本教程中,我们将创建一个智能体,通过向左或向右推动小车,可以解决平衡小车上的杆的问题。
状态

状态是当前的样子。我们通常用数字表示处理游戏。比如乒乓球游戏中,它可能是每个球拍的垂直位置和x,y坐标+球的速度。在推车杆的情况下,我们的状态由4个数字组成:小车的位置,小车的速度,杆的位置(用角度表示)和杆的角速度。这4个数字以数组(或者说向量)的形式给出。这个很重要:理解状态是一个数值数组意味着我们可以对它进行一些数学运算来决定我们根据状态采取什么行动。
策略
策略是一个可以获取游戏状态(例小车的位置,小车的速度,杆的位置等)的函数。并输出智能体应该在该位置采取的动作。在智能体采取我们选择的操作后,游戏将使用下一个状态进行更新,我们将再次将该状态提供给策略以做出决策。这种情况一直持续到游戏以某种方式结束。策略非常重要,也是我们需要找到的,因为它代表了智能体的决策能力。
点积
两个数组(向量)之间的点积简单地将第一个数组的每个元素乘以第二个数组的对应元素,然后求和。假设我们想求数组A和B的点积,它等于A [0] * B [0] + A [1] * B [1] ......我们将使用这个操作将状态(一个数组)乘以另一个数组(策略)。
制定我们的策略
想要解决我们的平衡杆游戏,我们需要让我们的机器学习策略来赢得游戏或者说最大化我们的奖励。
对于我们现在要开发的智能体,我们将策略表示为4个数字数组,代表状态的每个组成部分的重要性怎样(购物车位置,杆位等)然后我们计算状态的策略数组的点积输出单个数字。根据数字是正数还是负数,我们决定向左或向右推动小车。
可能这听起来有点抽象,让我们选择一个具体的例子。
假设小车在游戏中居中并且静止,并且杆向右倾斜也就是说向右倒下。它看起来像这样:

相关的状态可能如下所示:
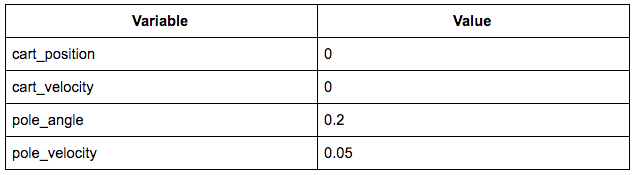
状态数组是[0,0,0.2,0.05]。
现在,我们要把小车推向右边,让杆立起来。我从我的一次训练中得到了一个很好的策略,其策略数据如下:[ - 0.116,0.332,0.207 0.352]。让我们手动完成数学运算,看看这个策略将输出什么作为这个状态的操作。
在这里,我们计算状态数组和策略数组的点积。如果数字是正数,我们将小车向右推,如果数字是负数,我们向左推。

结果是正数,这意味着策略会在这种情况下推动小车向右,这是我们希望它出现的表现。
那么,我们现在需要的是像上面那个帮助解决问题的4个数字。我们如何获得这些数字?如果我们只是随机挑选它们会怎样?它的效果如何?
开始你的编码!
让我们在repl.it上弹出一个Python实例。repl.it可以让你快速启动大量不同编程环境的云实例,并在可以在任何地方访问的强大云IDE中编辑代码。

安装包
我们首先安装这个项目所需的两个包:帮助进行数值计算的numpy,作为我们智能体模拟器的OpenAI Gym。
只要在编辑器左侧的包搜索工具中键入gym和numpy,然后单击加号按钮就可以安装包。
基础
让我们首先将我们刚刚安装的两个依赖项导入到我们的main.py脚本中并设置一个新的gym环境:
import gym
import numpy as np
env = gym.make('CartPole-v1')
接下来,我们将定义一个名为“play”的函数,该函数被赋予一个环境和一个策略数组,并将在环境中运行策略数组并返回分数以及每个时间步的游戏快照(观察)。我们使用分数来告诉我们策略的效果并通过快照来观察策略在一局游戏中的表现。这样我们就可以测试不同的策略,看看他们在游戏中的表现如何!
让我们首先定义函数,然后将游戏重置为开始状态。
def play(env,policy):
observation = env.reset()
接下来,我们将初始化一些变量,以跟踪游戏是否已经结束,策略的总分以及游戏中每个步骤的快照(观察)。
done = False
score = 0
observations = []
现在我们只是简单的玩一段时间游戏,直到gym告诉我们游戏已经玩完。
for _ in range(5000):
observations += [observation.tolist()] # Record the observations for normalization and replay
if done: # If the simulation was over last iteration, exit loop
break
# Pick an action according to the policy matrix
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# Make the action, record reward
observation, reward, done, info = env.step(action)
score += reward
return score, observations
上面的大部分代码主要是在玩游戏并记录结果。我们的策略的实际代码就是下面这两行:
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
我们在这里所做的就是策略数组和状态数组之间的点积运算。然后我们选择1或0(左或右)的动作,这取决于结果是正还是负。
于是,我们的脚本main.py应该看起来像这样:
import gym
import numpy as np
env = gym.make('CartPole-v1')
def play(env, policy):
observation = env.reset()
done = False
score = 0
observations = []
for _ in range(5000):
observations += [observation.tolist()] # Record the observations for normalization and replay
if done: # If the simulation was over last iteration, exit loop
break
# Pick an action according to the policy matrix
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# Make the action, record reward
observation, reward, done, info = env.step(action)
score += reward
return score, observations
现在我们要开始玩几局游戏并找到最优策略!
玩第一场比赛
现在,我们有了一个可以玩游戏的函数,它可以告诉我们的策略有多好,我们将要开始制定一些策略,看看它表现如何。
如果我们在开始只是试着插入一些随机的策略呢?我们能打多少分?让我们使用numpy生成我们的策略,它是一个4个元素的数组或者说1x4的矩阵。它会选择四个0到1之间的数字作为我们的策略。
policy = np.random.rand(1,4)
有了这个策略以及我们上面创建的环境,我们可以将它们插入游戏并获得分数。
score, observations = play(env, policy)
print('Policy Score', score)
只需点击run即可运行我们的脚本。它会输出我们的策略得分。
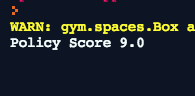
这场游戏的最高得分是500,很可能是你的策略没有那么好。如果你的分很高,那么恭喜你,今天一定是你的幸运日!只是看到一个数字并不没有多大意义,如果我们可以想象我们的智能体如何玩游戏,那就太好了。下一步我们就会设置智能体!
智能体
要观察我们的智能体,我们将使用Flask设置轻量级的服务器,这样我们就可以在浏览器中查看智能体的性能。Flask是一个轻量级的Python HTTP服务器框架,可以为我们的HTML UI和数据提供服务。在这里,我只简要介绍这一部分,因为渲染和HTTP服务器背后的细节对训练我们的智能体并不重要。
我们首先要安装Flask包,就像我们安装的方式就像gym和numpy一样。
接下来,在我们脚本的底部,我们将创建一个Flask服务器。它将在/data端点上显示游戏每帧的记录并在/上托管UI 。
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data():
return json.dumps(observations)
@app.route('/')
def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
另外,我们需要添加两个文件。一个是项目的空白Python文件。这是repl.it如何检测repl是处于eval模式还是project模式的技术性问题。只需使用new file按钮添加空白Python脚本即可。
之后我们还会创建一个index.html显示UI。在这里我不会深入细节,你只需index.html上传到你的repl.it项目即可(https://gist.github.com/MikeShi42/7b5ff55e2320e41228b5c25ad1113321)。
你现在的项目目录应该如下:
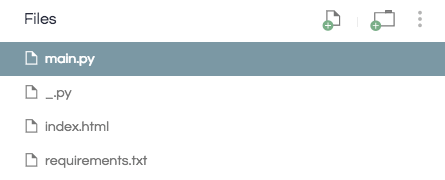
现在有了这两个新文件,当我们运行repl时,它现在应该会回放我们的策略如何执行。有了这个,让我们试着找到最优的策略!

策略检索
第一次,我们只是随机选择了一个策略,但是如果我们选择一些策略,然后只保留了那个做得最好的策略呢?
让我们回到我们执行策略的部分,我们不再只生成一个策略,而是我们编写一个循环来生成一些策略,并跟踪每个策略的执行情况,仅保存最佳策略。
我们将首先创建一个名为max的元组,它将存储我们迄今为止最佳策略的得分,观察和策略数组。
max =(0,[],[])
接下来,我们将生成并评估10个策略,并在max中保存最佳策略。
for _ in range(10):
policy = np.random.rand(1,4)
score, observations = play(env, policy)
if score > max[0]:
max = (score, observations, policy)
print('Max Score', max[0])
我们还必须让我们的/data端点返回最佳策略的重播。
端点:
@app.route("/data")
def data():
return json.dumps(observations)应改为:
@ app.route(“ / data ”)
def data():
return json.dumps(max [ 1 ])
现在你的main.py应该如下:
import gym
import numpy as np
env = gym.make('CartPole-v1')
def play(env, policy):
observation = env.reset()
done = False
score = 0
observations = []
for _ in range(5000):
observations += [observation.tolist()] # Record the observations for normalization and replay
if done: # If the simulation was over last iteration, exit loop
break
# Pick an action according to the policy matrix
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# Make the action, record reward
observation, reward, done, info = env.step(action)
score += reward
return score, observations
max = (0, [], [])
for _ in range(10):
policy = np.random.rand(1,4)
score, observations = play(env, policy)
if score > max[0]:
max = (score, observations, policy)
print('Max Score', max[0])
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data():
return json.dumps(max[1])
@app.route('/')
def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
如果我们现在运行repl,我们应该获得500的最大分数,如果没有,请重新运行repl!我们还可以完美地观察杆的策略平衡!
补充
事实上没那么简单,我们在第一部分中有几种方法作弊了。首先,我们只是在0到1的范围内随机创建了策略数组。这碰巧可行,但是如果我们翻转运算符号(大于号改成小于号),我们将看到智能体将失败相当灾难性。想要尝试可以将action = 1 if outcome > 0 else 0改为action = 1 if outcome < 0 else 0。
这很不稳定,因为如果我们恰好选择少于而不是大于,我们将永远找不到可以解决游戏的策略。为了缓解这种情况,我们实际上应该生成带有负数的策略。这将使得找到一个好的策略变得更加困难(因为许多负数的策略并不好),但是我们不再通过将我们的特定算法与这个特定的游戏匹配来“作弊”。如果我们尝试在OpenAI gym的其他环境中这样做,我们的算法肯定会失败。
想要解决这点我们将policy = np.random.rand(1,4)改为policy = np.random.rand(1,4) - 0.5。这样我们策略中的每个数字都在-0.5到0.5之间,而不是0到1.但是由于这更难,我们还要搜索更多的策略。在上面的for循环中,我们不再迭代10个策略,而是通过将代码改为for _ In range(100):来尝试100个策略。你可以尝试首先迭代10次,看看现在用负数来获得好的策略是多么困难。
现在我们的main.py如下:
import gym
import numpy as np
env = gym.make('CartPole-v1')
def play(env, policy):
observation = env.reset()
done = False
score = 0
observations = []
for _ in range(5000):
observations += [observation.tolist()] # Record the observations for normalization and replay
if done: # If the simulation was over last iteration, exit loop
break
# Pick an action according to the policy matrix
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# Make the action, record reward
observation, reward, done, info = env.step(action)
score += reward
return score, observations
max = (0, [], [])
# We changed the next two lines!
for _ in range(100):
policy = np.random.rand(1,4) - 0.5
score, observations = play(env, policy)
if score > max[0]:
max = (score, observations, policy)
print('Max Score', max[0])
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data():
return json.dumps(max[1])
@app.route('/')
def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
如果现在运行repl,无论我们使用的是大于还是小于,我们都可以为游戏找到一个好的策略。
补充2
还没完!即使我们的策略可以在一次运行中达到最高分500,但每次都能做到吗?当我们生成100个策略,并选择在单次运行中表现出最佳的策略时,得到这个策略只是运气好,它可能是一个非常糟糕的策略恰好有一次运行的好。这是因为游戏本身具有随机性因素(起始位置每次都不同),因此策略可能只适用于一个起始位置,不适用于其他起始位置。
因此,为了解决这个问题,我们想要评估策略在多次试验中的表现。现在,让我们获取我们之前发现的最佳策略,看看它在100次试验中的表现如何。
scores = []
for _ in range(100):
score, _ = play(env, max[2])
scores += [score]
print('Average Score (100 trials)', np.mean(scores))
在这里,我们运行100次最好的策略(max的索引为2),并记录每次的得分。然后我们用它numpy来计算平均分数并将其打印到我们的终端。









