


















JS使用者福音:在浏览器中运行人脸识别
现在,终于有可能在浏览器中运行人脸识别了!通过本文,我将介绍face-api,它是一个构建在tensorflow.js core的JavaScript模块,它实现了人脸检测、人脸识别和人脸地标检测三种类型的CNN。
我们首先研究一个简单的代码示例,以用几行代码立即开始使用该包。
第一个face-recognition.js,现在又是一个包?
如果你读过关于人脸识别与其他的NodeJS文章:(https://medium.com/@muehler.v/node-js-face-recognition-js-simple-and-robust-face-recognition-using-deep-learning-ea5ba8e852),你可能知道,不久前,我组装了一个类似的包(face-recognition.js)。
起初,我没有想到在javascript社区中对脸部识别软件包的需求如此之高。对于很多人来说,face-recognition.js似乎是一个不错的免费使用且开源的替代付费服务的人脸识别服务,就像微软或亚马逊提供的一样。其中很多人问,是否可以在浏览器中完全运行完整的人脸识别管道。
在这里,我应该感谢tensorflow.js!我设法使用tfjs-core实现了部分类似的工具,这使你可以在浏览器中获得与face-recognition.js几乎相同的结果!最好的部分是,不需要设置任何外部依赖关系,可以直接使用。并且,它是GPU加速的,在WebGL上运行操作。
这使我相信,JavaScript社区需要这样的浏览器包!你可以用这个来构建自己的各种各样的应用程序。;)
如何用深度学习解决人脸识别问题
如果你希望尽快开始,也可以直接去编码。但想要更好地理解face-api.js中用于实现人脸识别的方法,我强烈建议你看一看,这里有很多我经常被问到的问题。
简单地说,我们真正想要实现的是,识别一个人的面部图像(input image)。我们这样做的方式是为每个我们想要识别的人提供一个(或多个)图像,并标注人名(reference data)。现在我们将它们进行比较,并找到最相似的参考图像。如果两张图片足够相似,我们输出该人的姓名,否则我们输出“unknown”。
听起来不错吧!然而,还是存在两个问题。首先,如果我们有一张显示多个人的图片,我们想要识别所有的人,该怎么办?其次,我们需要能够获得这种类型的两张人脸图像的相似性度量,以便比较它们......
人脸检测
第一个问题的答案是人脸检测。简而言之,我们将首先找到输入图像中的所有人脸。对于人脸检测,face-api.js实现了SSD(Single Shot Multibox Detector),它基本上是基于MobileNetV1的CNN,只是在网络顶部叠加了一些额外的盒预测层。
网络返回每个人脸的边界框及其相应的分数,即每个边界框显示一个人脸的可能性。分数用于过滤边界框,因为图像中可能根本不包含任何人脸。请注意,即使只有一个人检索边界框,也应执行人脸检测。

人脸标志检测和人脸对齐
第一个问题解决了!但是,我们希望对齐边界框,这样我们就可以在每个框的人脸中心提取出图像,然后将它们传递给人脸识别网络,这会使人脸识别更加准确!
为此,face-api.js实现了一个简单的CNN,它返回给定人脸图像的68个点的人脸标志:
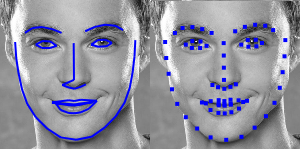
从地标位置,边界框可以准确的包围人脸。在下图,你可以看到人脸检测的结果(左)与对齐的人脸图像(右)的比较:

人脸识别
现在我们可以将提取并对齐的人脸图像提供给人脸识别网络,这个网络基于类似ResNet-34的架构并且基本上与dlib中实现的架构相对应。该网络已经被训练学习将人脸的特征映射到人脸描述符(descriptor ,具有128个值的特征矢量),这通常也被称为人脸嵌入。
现在回到我们最初的比较两个人脸的问题:我们将使用每个提取的人脸图像的人脸描述符并将它们与参考数据的人脸描述符进行比较。也就是说,我们可以计算两个人脸描述符之间的欧氏距离,并根据阈值判断两个人脸是否相似(对于150 x 150大小的人脸图像,0.6是一个很好的阈值)。使用欧几里德距离的方法非常有效,当然,你也可以使用任何你选择的分类器。以下gif通过欧几里德距离将两幅人脸图像进行比较:
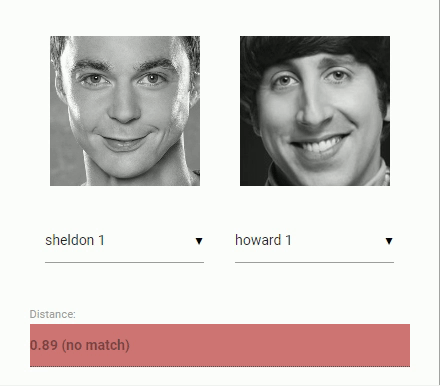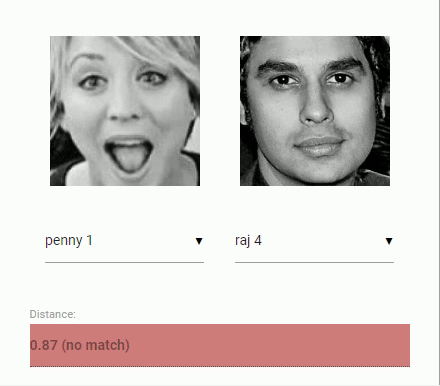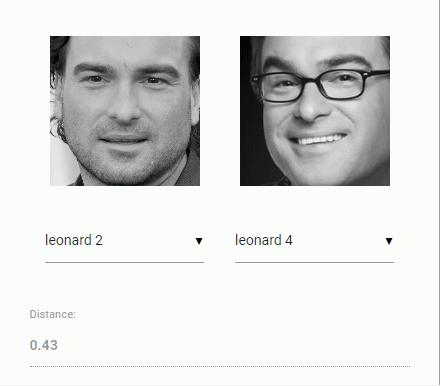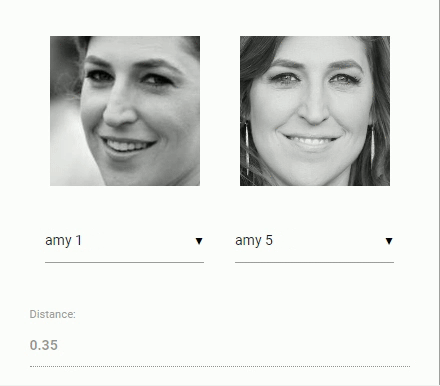
学完了人脸识别的理论,我们可以开始编写一个示例。
编码
在这个简短的例子中,我们将逐步了解如何在以下显示多人的输入图像上进行人脸识别:

包括脚本
首先,从 dist/face-api.js或者dist/face-api.min.js的minifed版本中获取最新的构建且包括脚本:
 欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








