











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度学习图像识别项目(中):Keras和卷积神经网络(CNN)
2018年05月10日 由 yuxiangyu 发表
72722
0
这篇文章是关于构建完整的端到端图像分类+深度学习应用的三篇系列文章的第二部分:
第一部分:如何快速构建图像数据集
阅读本文,你将了解如何在自己的自定义数据集上实现,训练和评估卷积神经网络。
在下篇文章中,我还会演示如何将训练好的Keras模型,通过几行代码将其部署到智能手机上。
现在,我正在实现我的童年梦想和建立神奇宝贝图鉴(Pokedex )。它是一款存在于宠物小精灵世界中的设备,可以识别神奇宝贝。你可以把它想象成一款可以识别神奇宝贝的智能手机应用程序。
上篇文章中,我们学习了如何快速构建深度学习图像数据集 ,我们使用该文章中介绍的过程和代码来收集,下载和整理磁盘上的图像。
现在我们已经下载和组织了我们的图像,下一步就是在数据之上训练一个卷积神经网络CNN。
我会在今天文章中向你展示如何使用Keras和深入的学习来训练你的卷积神经网络CNN。 本系列的最后一部分将于下周发布,它将演示如何使用经过训练的Keras模型,并将其部署到智能手机(特别是iPhone)中,只需几行代码。
本系列的最终目标是帮助你构建功能全面的深度学习应用程序 - 将此系列作为灵感和出发点来帮助你构建自己的深度学习应用程序。
让我们继续开始,并开始使用Keras和深入的学习来训练卷积神经网络CNN。

我们的深度学习数据集包含1,191个宠物小精灵的图像,(宠物小精灵世界中存在的类似动物的生物,受欢迎的电视节目,视频游戏和交易卡系列)。
我们的目标是训练一个使用Keras和深度学习的卷积神经网络CNN来识别和分类这些口袋妖怪。
我们将认识到的口袋妖怪包括:
在上面的图中可以看到每个班级的训练图像的训练图像的剪辑。
正如你所看到的,我们的训练图像包括以下组合:
这种多样化的训练图像将使我们的卷积神经网络CNN能够在各种图像上识别我们的五种口袋妖怪, 我们将能够获得97%以上的分类准确度!
今天的项目有几个活动的部分,为了帮助我们围绕项目打好基础,让我们先回顾一下项目的目录结构:
有3个目录:
dataset :包含五个类,每个类都是它自己的子目录,使解析类标签变得容易。
examples :包含我们将用来测试卷积神经网络CNN的图像。
pyimagesearch 模块:包括我们的 SmallerVGGNet 模型类。
在根目录中有5个文件:
plot.png :训练脚本运行后产生的训练/测试准确性和损失情节。
lb.pickle :我们的 LabelBinarizer 序列化的目标文件 - 它包含一个类名索引到类名称查找机制。
pokedex.model :这是我们的系列化Keras卷积神经网络模型文件(即“权重文件”)。
train .py :我们将使用这个脚本来训练我们的Keras CNN,绘制准确性/损失,然后将卷积神经网络CNN和标签binarizer序列化到磁盘。
classify .py :我们的测试脚本。
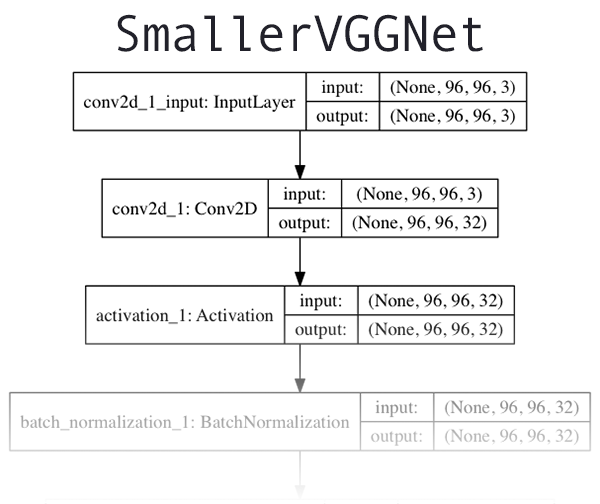
我们使用的卷积神经网络CNN架构是由Simonyan和Zisserman在其2014年的论文“ 用于大规模图像识别的深度卷积网络”中介绍的VGGNet网络的更小,更紧凑的变体。
VGGNet类架构的特点是:
我假设你已经在你的系统上安装并配置了Keras。
让我们继续并实施 SmallerVGGNet ,我们的小版本VGGNet。创建一个名为smallervggnet的新文件 。py 在 pyimagesearch 模块中并插入以下代码:
首先我们导入我们的模块 - 注意他们都来自Keras。
注意: 你还需要创建一个 __init__ 。py 文件在pyimagesearch里面, 所以Python知道这个目录是一个模块。如果你不熟悉 __init__ 。py 文件或它们如何用于创建模块,无需担心,只需使用本博客文章末尾的“下载”部分下载我的目录结构,源代码和数据集+示例图像。
从那里,我们定义了我们的 SmallerVGGNet 类:
我们的构建方法需要四个参数:
width:图像宽度尺寸。
height :图像高度尺寸。
depth :图像的深度 - 也称为通道数量。
classes :数据集中类的数量(这将影响我们模型的最后一层)。我们在这篇文章中利用了5个口袋妖怪类,但是不要忘记,如果你为每个物种下载了足够的示例图像,你就可以使用807口袋怪兽种类!
注意: 我们将 使用深度为 3的96 x 96 输入图像 (我们将在后面看到)。在我们解释输入音量通过网络时的空间维度时,请记住这一点。
由于我们使用的是TensorFlow后端,因此我们使用“频道最后”数据排序来排列输入形状,但是如果你想要使用“频道第一”(Theano等),则会在第23-25行自动处理它 。
现在,让我们开始向我们的模型添加层:
以上是我们的第一个 CONV = > RELU = > POOL 块。
卷积层有 32 个3 × 3 内核的过滤器 。我们使用 RELU 激活函数,然后进行批量标准化。
我们的 池化层使用 3 x 3的 池化大小将空间维度从96 x 96 快速减少 到 32 x 32 (我们将使用 96 x 96 x 3 输入图像来训练我们的网络,我们将在下一节中看到) 。
从代码块中可以看到,我们也将在我们的网络体系结构中使用丢包。Dropout的工作原理是将节点从当前层随机断开连接 到 下一层。这个在训练批次中随机断开的过程有助于自然地在模型中引入冗余 - 层中没有任何单个节点负责预测某个类,对象,边或角。
在此之前,我们将 在应用另一个池化层之前添加 (CONV = > RELU )* 2 层 :
将多个CONV 和 RELU 层堆叠 在一起(在缩小体积的空间尺寸之前)可以让我们学习更丰富的功能。
请注意:
我们正在将我们的过滤器尺寸从 32 增加到 64 。网络越深入,我们音量的空间尺寸越小,我们学到的滤波器越多。
我们减少了从3 x 3 到 2 x 2的 最大池大小, 以确保我们不会过快地减少空间维度。
在此阶段再次执行辍学(Dropout) 。
我们再添加一组 (CONV = > RELU )* 2 = > POOL :
请注意,我们已将我们的过滤器大小增加到了 128个 。执行25%的节点退出以再次减少过拟合。
最后,我们有一组 FC = > RELU 层和一个softmax分类器:
完全连接层由Dense (1024 )指定 ,具有校正的线性单位激活和批量归一化。
辍学是最后一次执行 - 这次注意到我们在训练期间辍学了50%的节点。通常情况下,在我们的完全连接层中,你会使用40-50%的辍学率,而在以前的层次中,通常是10-25%的辍学率(如果有任何退出应用)。
我们使用softmax分类器对模型进行四舍五入,该分类器将返回每个类标签的预测概率。
本节顶部的架构图中 可以看到SmallerVGGNet前几层网络架构的可视化 。要查看Keras CNN实现SmallerVGGNet的完整的图 ,可以访问图下链接。
现在 已经实现了更小的 VGGNet,我们可以使用Keras来训练我们的卷积神经网络。
打开一个新的文件,将其命名train.py ,然后将下面的代码,我们将导入我们需要的包和库:
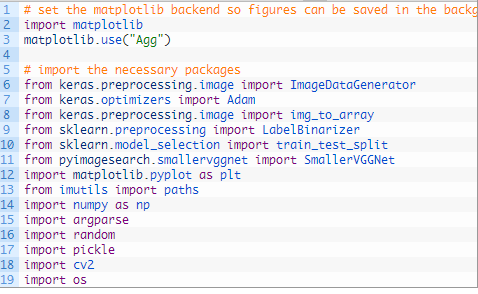
我们将使用 “Agg” matplotlib后端,以便可以将数字保存在背景中(第3行)。
该 ImageDataGenerator 类将被用于数据扩张,用于获取在我们的数据集中现有图像并应用随机变换(旋转,剪切等),以产生额外的训练数据的技术。数据增强有助于防止过拟合。
第7行导入了 Adam 优化器,这是用于训练我们的网络的优化器方法。
该 LabelBinarizer (9行)是需要注意的一个重要的类-这个类将使我们能够:
我经常会在PyImageSearch博客上询问我们如何将类标签字符串转换为整数,反之亦然。现在你知道解决方案是使用 LabelBinarizer 类。
该 train_test_split 函数(10行)将被用于创建我们的训练和测试分裂。另请注意我们 在11行上的 小型VGGNet导入,这是我们在上一节中实施的Keras CNN。
如果你没安装imutils包。安装/更新它,可以通过以下方式进行安装:
如果你正在使用Python虚拟环境请确保 在安装/升级imutils之前使用 workon命令访问特定的虚拟环境 。
从那里,让我们解析我们的命令行参数:

对于我们的训练脚本,我们需要提供三个必需的命令行参数:
--dataset :输入数据集的路径。我们的数据集被组织在一个 数据集 目录中,其子目录代表每个类。每个子目录里面有约250个宠物小精灵图片。
- - model :输出模型的路径 - 此训练脚本将训练模型并将其输出到磁盘。
- - labelbin :输出标签二值化器的路径 - 就像你很快会看到的那样,我们将从数据集目录名称中提取类标签并构建标签二值化器。
我们也有一个可选的参数, - plot 。如果你没有指定一个路径/文件名,那么一个plot.png文件将被放置在当前的工作目录中。
你 并不需要修改行22-31 来提供新的文件路径。命令行参数在运行时处理。如果这对你没有意义,请务必查看命令行参数。
链接:www.pyimagesearch.com/2018/03/12/python-argparse-command-line-arguments/
现在我们已经关注了我们的命令行参数,让我们初始化一些重要的变量:
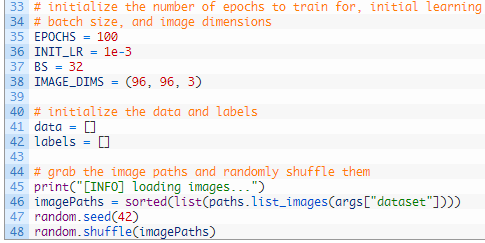
第35-38行初始化训练Keras CNN时使用的重要变量:
EPOCHS : 我们将训练我们的网络的时代总数(即,我们的网络“看到”每个训练示例多少次,并从中学习模式)。
INIT_LR : 初始学习速率 - 1e-3的值是Adam优化器(我们将用来训练网络的优化器)的默认值。
BS : 我们会将成批的图像传入我们的网络进行训练。每个时代有多个批次。所述 BS 值控制批量大小。
IMAGE_DIMS : 这里我们提供了输入图像的空间维度。我们需要我们的输入图像为 96 x 96 像素, 3 通道(即RGB)。我还会注意到,我们专门设计了具有 96 x 96 图像的SmallerVGGNet 。
我们还初始化两个列表 - data和labels ,它们将分别保存预处理的图像和标签。
第46-48行 抓取所有图像路径并随机混洗它们。
并从那里,我们将循环每个这些 imagePaths :
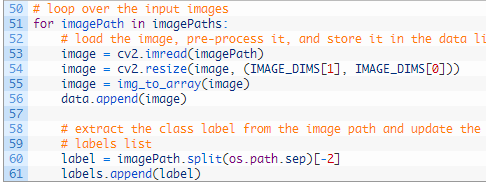
我们遍历所有的 imagePaths 上 51行,然后进行加载图像(53行),并调整其大小,以适应我们的模型(54行)。
现在是更新我们的data和labels列表的时候了。
我们调用Keras的 img_to_array 函数将图像转换为与Keras兼容的数组(第55行),然后将图像附加到我们的data列表 (第56行)。
对于我们的labels列表,我们 从第60行 的文件路径中提取labels并在第61行上追加它(标签) 。
那么,为什么这个类标签解析过程起作用?
考虑到我们故意创建了我们的数据集目录结构以具有以下格式的事实 :
使用第60行的路径分隔符,我们可以将路径分成一个数组,然后抓取列表中的倒数第二个条目 - 类标签。
如果这个过程让你感到困惑,我鼓励你打开一个Python shell,并通过在你的操作系统各自的路径分隔符上分割路径来探索一个示例 imagePath。
让我们继续前进。在下一个代码块中发生了一些事情 - 额外的预处理,二值化标签和分区数据:
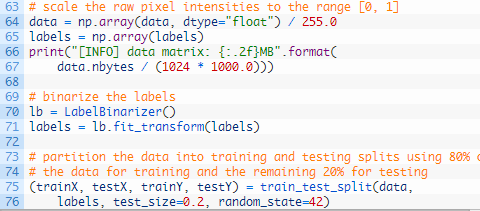
在这里,我们第一次的转换 数据 阵列为NumPy的数组,然后缩放像素强度的范围 [ 0 ,1 ] (64行)。我们还将 列表中的标签转换为 65行的NumPy数组 。将打印一条信息消息,显示数据 矩阵的大小(以MB为单位) 。
然后,我们使用scikit-learn的LabelBinarizer (第70和71行)对标签进行二值化 。
随着深度学习或任何机器学习,通常的做法是进行训练和测试分离。这是在第75行和第76行处理的 ,我们创建了数据的80/20随机分割。
接下来,我们来创建我们的图像数据增强对象:

由于我们正在使用有限数量的数据点(每班少于250个图像),因此我们可以在训练过程中利用数据增强功能为模型提供更多图像(基于现有图像)进行训练。
数据增强是应该在每个深度学习实践者的工具箱中应用的工具。我使用Python涵盖了计算机视觉深度学习实践者套件中的 数据增强 。
我们 在 79-81行初始化我们的ImageDataGenerator的 aug 。
从那里,让我们编译模型并开始训练:
在第85和第86行,我们用96 x 96 x 3的 输入空间维度初始化我们的Keras CNN模型 。当我经常收到这个问题时,我会再次说明--SmallerVGGNet被设计为接受 96 x 96 x 3 输入图像。如果你想要使用不同的空间维度,你可能需要:
不要盲目编辑代码。考虑更大或更小的图像将首先带来的影响!
我们将使用 具有学习速率衰减的 Adam优化器(第87行),然后 使用分类交叉熵编译 我们的 模型,因为我们有> 2个类(88行和89行)。
注意:对于只有两个类别,你应该使用二元交叉熵作为损失。
从那里,我们打电话给 Keras fit_generator 方法来训练网络(93-97行)。请耐心等待 - 这可能需要一些时间,具体取决于你是使用CPU还是使用GPU进行训练。
一旦我们的Keras CNN完成了训练,我们将需要保存(1)模型和(2)标签二进制器,因为当我们在训练/测试集以外的图像上测试网络时,我们需要从磁盘加载它们:
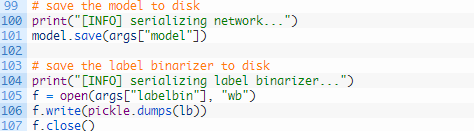
我们序列化模型(第101行)和标签二进制器(第105-107行),以便稍后在我们的classify.py 脚本中使用它们 。
标签binarizer文件包含人类可读类标签字典的类索引。该对象确保我们不必在希望使用Keras CNN的脚本中对我们的类标签进行硬编码。
最后,我们可以绘制我们的训练和损失的准确性:
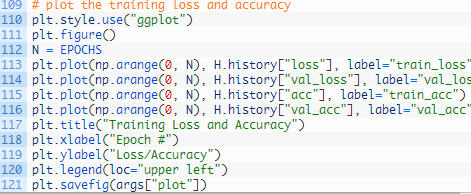
我选择将我的情节保存到磁盘(第 121行),而不是显示它,原因有两个:(1)我在云端的headless服务器上;(2)我想确保我不会忘记保存plot。
现在我们准备训练我们的Pokedex CNN。
然后执行以下命令来训练模式; 同时确保正确提供命令行参数:
看看我们的训练脚本的输出结果,我们看到我们的Keras CNN获得了:
训练损失/准确性图如下:
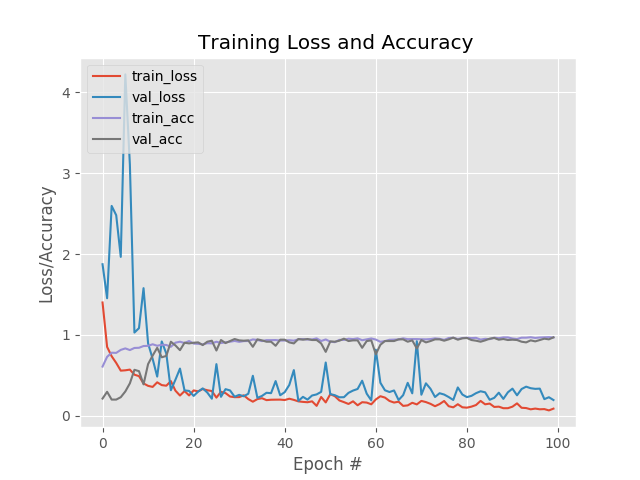
用Keras训练的Pokedex深度学习分类器的训练和验证损失/准确性图。
正如你在图3中看到的那样,我训练了100个时期的模型,并在有限的过拟合下实现了低损耗。利用额外的训练数据,我们也可以获得更高的准确性。
现在,我们的CNN已经过训练,我们需要实施一个脚本来对不属于我们训练或验证/测试集的图像进行分类。打开一个新的文件,将其命名classify.py ,并插入下面的代码:
首先我们进口必要的包裹(2-9行)。
从那里,让我们解析命令行参数:
我们 需要解析三个必需的 命令行参数:
--model :我们刚刚训练的模型的路径。
- labelbin :标签二进制文件的路径。
--image:我们的输入图像文件路径。
这些参数中的每一个都是在第12-19行上建立和解析的 。请记住,你不需要修改这些行 - 我将向你展示如何使用运行时提供的命令行参数在下一节中运行该程序。
接下来,我们将加载并预处理图像:
在这里,我们加载输入image (第22行)并 为显示目的制作一个称为output 副本 (第23行)。
然后我们 以与训练所用的方式完全相同的方式对image进行预处理 (26-29行)。
从那里,我们加载模型+标签二值化器,然后对图像进行分类:
为了对图像进行分类,我们需要 内存中的 模型和标签二值化器。我们加载第34和35行。
随后,我们对图像进行分类 并创建 标签 (39-41行)。
剩余的代码块用于显示目的:
在第46行和第47行,我们从文件名中提取口袋妖怪的名字 ,并将其与标签进行比较 。基于此, 正确的 变量将是 “correct” 或 “incorrect” (正确或不正确)。显然,这两行假设你的输入图像具有包含真实标签的文件名。
从那里我们采取以下步骤:
将类标签 (第50行)添加概率百分比和 “正确” / “不正确”文本 。
调整输出 图像的大小, 使其适合我们的屏幕(第51行)。
在输出 图像上绘制 标签文本 (第52和53行)。
显示 输出 图像并等待按键退出(第57和58行)。
我们现在准备运行classify.py 脚本!
一旦你下载了解压缩文件并将其解压缩到这个项目的根目录下,然后从Charmander的图像开始。请注意,我们提供了三个命令行参数来运行脚本:

现在让我们来看一下我们的模型,妙蛙种子:

让我们来尝试一下超梦 :

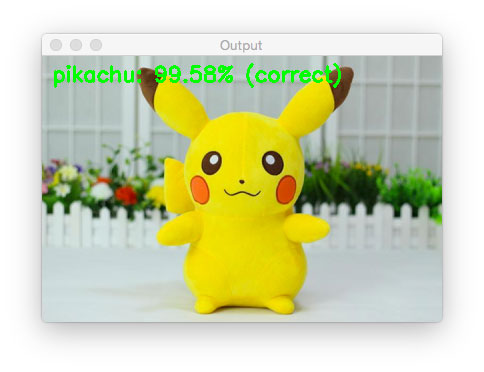
如果Pokedex无法识别皮卡丘:
让我们试试可爱的杰尼龟:

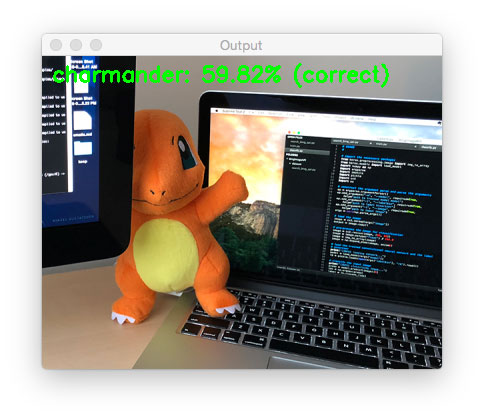
最后,我们再次分类小火龙。这次不完整,被我的显示器遮住了一部分。
这些宠物小精灵中的每一个都不匹配我的新Pokedex。
目前,大约有807种不同的口袋妖怪。我们的分类器只训练了五种不同的口袋妖怪(为了简单起见)。
如果你想要训练一个分类器来识别更多的口袋妖怪来获得更大的Pokedex,你需要为每个类增加额外的训练图像。 理想情况下,你的目标应该是每个班级有500-1,000张图片可供你识别。
这种模式的主要局限之一是少量的训练数据。我测试了各种图像,有时分类不正确。发生这种情况时,我更仔细地检查了输入图像+网络,发现图像中最主要的颜色显著影响分类。
例如,图像中的许多红色和橙色可能会返回 “小火龙”作为标签。同样,图像中的黄色通常会产生 “皮卡丘”标签。
理想情况下,训练卷积神经网络时,每类至少应有500-1,000幅图像。在处理你自己的数据时请记住这一点。
在下篇文章中,我将展示如何将我们训练的Keras +卷积神经网络模型部署到智能手机!
第一部分:如何快速构建图像数据集
阅读本文,你将了解如何在自己的自定义数据集上实现,训练和评估卷积神经网络。
在下篇文章中,我还会演示如何将训练好的Keras模型,通过几行代码将其部署到智能手机上。
现在,我正在实现我的童年梦想和建立神奇宝贝图鉴(Pokedex )。它是一款存在于宠物小精灵世界中的设备,可以识别神奇宝贝。你可以把它想象成一款可以识别神奇宝贝的智能手机应用程序。
Keras和卷积神经网络CNN
上篇文章中,我们学习了如何快速构建深度学习图像数据集 ,我们使用该文章中介绍的过程和代码来收集,下载和整理磁盘上的图像。
现在我们已经下载和组织了我们的图像,下一步就是在数据之上训练一个卷积神经网络CNN。
我会在今天文章中向你展示如何使用Keras和深入的学习来训练你的卷积神经网络CNN。 本系列的最后一部分将于下周发布,它将演示如何使用经过训练的Keras模型,并将其部署到智能手机(特别是iPhone)中,只需几行代码。
本系列的最终目标是帮助你构建功能全面的深度学习应用程序 - 将此系列作为灵感和出发点来帮助你构建自己的深度学习应用程序。
让我们继续开始,并开始使用Keras和深入的学习来训练卷积神经网络CNN。
我们的深度学习数据集
我们的深度学习数据集包含1,191个宠物小精灵的图像,(宠物小精灵世界中存在的类似动物的生物,受欢迎的电视节目,视频游戏和交易卡系列)。
我们的目标是训练一个使用Keras和深度学习的卷积神经网络CNN来识别和分类这些口袋妖怪。
我们将认识到的口袋妖怪包括:
- 妙蛙种子(234图像)
- 小火龙(238图像)
- 杰尼龟(223图像)
- 皮卡丘(234图像)
- 超梦(239图像)
在上面的图中可以看到每个班级的训练图像的训练图像的剪辑。
正如你所看到的,我们的训练图像包括以下组合:
- 来自电视节目和电影的静帧
- 游戏卡
- 公仔
- 毛绒玩具
- 粉丝画的的艺术效果图
这种多样化的训练图像将使我们的卷积神经网络CNN能够在各种图像上识别我们的五种口袋妖怪, 我们将能够获得97%以上的分类准确度!
卷积神经网络CNN和Keras项目结构
今天的项目有几个活动的部分,为了帮助我们围绕项目打好基础,让我们先回顾一下项目的目录结构:
├── dataset
│ ├── bulbasaur [234 entries]
│ ├── charmander [238 entries]
│ ├── mewtwo [239 entries]
│ ├── pikachu [234 entries]
│ └── squirtle [223 entries]
├── examples [6 entries]
├── pyimagesearch
│ ├── __init__.py
│ └── smallervggnet.py
├── plot.png
├── lb.pickle
├── pokedex.model
├── classify.py
└── train.py
有3个目录:
dataset :包含五个类,每个类都是它自己的子目录,使解析类标签变得容易。
examples :包含我们将用来测试卷积神经网络CNN的图像。
pyimagesearch 模块:包括我们的 SmallerVGGNet 模型类。
在根目录中有5个文件:
plot.png :训练脚本运行后产生的训练/测试准确性和损失情节。
lb.pickle :我们的 LabelBinarizer 序列化的目标文件 - 它包含一个类名索引到类名称查找机制。
pokedex.model :这是我们的系列化Keras卷积神经网络模型文件(即“权重文件”)。
train .py :我们将使用这个脚本来训练我们的Keras CNN,绘制准确性/损失,然后将卷积神经网络CNN和标签binarizer序列化到磁盘。
classify .py :我们的测试脚本。
我们的Keras和卷积神经网络CNN架构
架构图,因图像过长完整版请访问:www.pyimagesearch.com/wp-content/uploads/2018/04/smallervggnet_model.png
我们使用的卷积神经网络CNN架构是由Simonyan和Zisserman在其2014年的论文“ 用于大规模图像识别的深度卷积网络”中介绍的VGGNet网络的更小,更紧凑的变体。
VGGNet类架构的特点是:
- 只使用3×3卷积层堆叠在一起,增加深度
- 通过最大池化来减小卷大小
- softmax分类器之前网络末端的完全连接层
我假设你已经在你的系统上安装并配置了Keras。
让我们继续并实施 SmallerVGGNet ,我们的小版本VGGNet。创建一个名为smallervggnet的新文件 。py 在 pyimagesearch 模块中并插入以下代码:
# import the necessary packages
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras import backend as K
首先我们导入我们的模块 - 注意他们都来自Keras。
注意: 你还需要创建一个 __init__ 。py 文件在pyimagesearch里面, 所以Python知道这个目录是一个模块。如果你不熟悉 __init__ 。py 文件或它们如何用于创建模块,无需担心,只需使用本博客文章末尾的“下载”部分下载我的目录结构,源代码和数据集+示例图像。
从那里,我们定义了我们的 SmallerVGGNet 类:
class SmallerVGGNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们的构建方法需要四个参数:
width:图像宽度尺寸。
height :图像高度尺寸。
depth :图像的深度 - 也称为通道数量。
classes :数据集中类的数量(这将影响我们模型的最后一层)。我们在这篇文章中利用了5个口袋妖怪类,但是不要忘记,如果你为每个物种下载了足够的示例图像,你就可以使用807口袋怪兽种类!
注意: 我们将 使用深度为 3的96 x 96 输入图像 (我们将在后面看到)。在我们解释输入音量通过网络时的空间维度时,请记住这一点。
由于我们使用的是TensorFlow后端,因此我们使用“频道最后”数据排序来排列输入形状,但是如果你想要使用“频道第一”(Theano等),则会在第23-25行自动处理它 。
现在,让我们开始向我们的模型添加层:
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
以上是我们的第一个 CONV = > RELU = > POOL 块。
卷积层有 32 个3 × 3 内核的过滤器 。我们使用 RELU 激活函数,然后进行批量标准化。
我们的 池化层使用 3 x 3的 池化大小将空间维度从96 x 96 快速减少 到 32 x 32 (我们将使用 96 x 96 x 3 输入图像来训练我们的网络,我们将在下一节中看到) 。
从代码块中可以看到,我们也将在我们的网络体系结构中使用丢包。Dropout的工作原理是将节点从当前层随机断开连接 到 下一层。这个在训练批次中随机断开的过程有助于自然地在模型中引入冗余 - 层中没有任何单个节点负责预测某个类,对象,边或角。
在此之前,我们将 在应用另一个池化层之前添加 (CONV = > RELU )* 2 层 :
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
将多个CONV 和 RELU 层堆叠 在一起(在缩小体积的空间尺寸之前)可以让我们学习更丰富的功能。
请注意:
我们正在将我们的过滤器尺寸从 32 增加到 64 。网络越深入,我们音量的空间尺寸越小,我们学到的滤波器越多。
我们减少了从3 x 3 到 2 x 2的 最大池大小, 以确保我们不会过快地减少空间维度。
在此阶段再次执行辍学(Dropout) 。
我们再添加一组 (CONV = > RELU )* 2 = > POOL :
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(128, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
请注意,我们已将我们的过滤器大小增加到了 128个 。执行25%的节点退出以再次减少过拟合。
最后,我们有一组 FC = > RELU 层和一个softmax分类器:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
完全连接层由Dense (1024 )指定 ,具有校正的线性单位激活和批量归一化。
辍学是最后一次执行 - 这次注意到我们在训练期间辍学了50%的节点。通常情况下,在我们的完全连接层中,你会使用40-50%的辍学率,而在以前的层次中,通常是10-25%的辍学率(如果有任何退出应用)。
我们使用softmax分类器对模型进行四舍五入,该分类器将返回每个类标签的预测概率。
本节顶部的架构图中 可以看到SmallerVGGNet前几层网络架构的可视化 。要查看Keras CNN实现SmallerVGGNet的完整的图 ,可以访问图下链接。
实施我们的卷积神经网络CNN + Keras训练脚本
现在 已经实现了更小的 VGGNet,我们可以使用Keras来训练我们的卷积神经网络。
打开一个新的文件,将其命名train.py ,然后将下面的代码,我们将导入我们需要的包和库:
我们将使用 “Agg” matplotlib后端,以便可以将数字保存在背景中(第3行)。
该 ImageDataGenerator 类将被用于数据扩张,用于获取在我们的数据集中现有图像并应用随机变换(旋转,剪切等),以产生额外的训练数据的技术。数据增强有助于防止过拟合。
第7行导入了 Adam 优化器,这是用于训练我们的网络的优化器方法。
该 LabelBinarizer (9行)是需要注意的一个重要的类-这个类将使我们能够:
- 输入一组类标签(即表示我们数据集中人类可读类标签的字符串)。
- 将我们的类标签转换为独热编码矢量。
- 允许我们从Keras CNN中进行整型标签预测,并将其转换回人类可读的标签。
我经常会在PyImageSearch博客上询问我们如何将类标签字符串转换为整数,反之亦然。现在你知道解决方案是使用 LabelBinarizer 类。
该 train_test_split 函数(10行)将被用于创建我们的训练和测试分裂。另请注意我们 在11行上的 小型VGGNet导入,这是我们在上一节中实施的Keras CNN。
如果你没安装imutils包。安装/更新它,可以通过以下方式进行安装:
$ pip install --upgrade imutils
如果你正在使用Python虚拟环境请确保 在安装/升级imutils之前使用 workon命令访问特定的虚拟环境 。
从那里,让我们解析我们的命令行参数:
对于我们的训练脚本,我们需要提供三个必需的命令行参数:
--dataset :输入数据集的路径。我们的数据集被组织在一个 数据集 目录中,其子目录代表每个类。每个子目录里面有约250个宠物小精灵图片。
- - model :输出模型的路径 - 此训练脚本将训练模型并将其输出到磁盘。
- - labelbin :输出标签二值化器的路径 - 就像你很快会看到的那样,我们将从数据集目录名称中提取类标签并构建标签二值化器。
我们也有一个可选的参数, - plot 。如果你没有指定一个路径/文件名,那么一个plot.png文件将被放置在当前的工作目录中。
你 并不需要修改行22-31 来提供新的文件路径。命令行参数在运行时处理。如果这对你没有意义,请务必查看命令行参数。
链接:www.pyimagesearch.com/2018/03/12/python-argparse-command-line-arguments/
现在我们已经关注了我们的命令行参数,让我们初始化一些重要的变量:
第35-38行初始化训练Keras CNN时使用的重要变量:
EPOCHS : 我们将训练我们的网络的时代总数(即,我们的网络“看到”每个训练示例多少次,并从中学习模式)。
INIT_LR : 初始学习速率 - 1e-3的值是Adam优化器(我们将用来训练网络的优化器)的默认值。
BS : 我们会将成批的图像传入我们的网络进行训练。每个时代有多个批次。所述 BS 值控制批量大小。
IMAGE_DIMS : 这里我们提供了输入图像的空间维度。我们需要我们的输入图像为 96 x 96 像素, 3 通道(即RGB)。我还会注意到,我们专门设计了具有 96 x 96 图像的SmallerVGGNet 。
我们还初始化两个列表 - data和labels ,它们将分别保存预处理的图像和标签。
第46-48行 抓取所有图像路径并随机混洗它们。
并从那里,我们将循环每个这些 imagePaths :
我们遍历所有的 imagePaths 上 51行,然后进行加载图像(53行),并调整其大小,以适应我们的模型(54行)。
现在是更新我们的data和labels列表的时候了。
我们调用Keras的 img_to_array 函数将图像转换为与Keras兼容的数组(第55行),然后将图像附加到我们的data列表 (第56行)。
对于我们的labels列表,我们 从第60行 的文件路径中提取labels并在第61行上追加它(标签) 。
那么,为什么这个类标签解析过程起作用?
考虑到我们故意创建了我们的数据集目录结构以具有以下格式的事实 :
dataset/{CLASS_LABEL}/{FILENAME}.jpg使用第60行的路径分隔符,我们可以将路径分成一个数组,然后抓取列表中的倒数第二个条目 - 类标签。
如果这个过程让你感到困惑,我鼓励你打开一个Python shell,并通过在你的操作系统各自的路径分隔符上分割路径来探索一个示例 imagePath。
让我们继续前进。在下一个代码块中发生了一些事情 - 额外的预处理,二值化标签和分区数据:
在这里,我们第一次的转换 数据 阵列为NumPy的数组,然后缩放像素强度的范围 [ 0 ,1 ] (64行)。我们还将 列表中的标签转换为 65行的NumPy数组 。将打印一条信息消息,显示数据 矩阵的大小(以MB为单位) 。
然后,我们使用scikit-learn的LabelBinarizer (第70和71行)对标签进行二值化 。
随着深度学习或任何机器学习,通常的做法是进行训练和测试分离。这是在第75行和第76行处理的 ,我们创建了数据的80/20随机分割。
接下来,我们来创建我们的图像数据增强对象:
由于我们正在使用有限数量的数据点(每班少于250个图像),因此我们可以在训练过程中利用数据增强功能为模型提供更多图像(基于现有图像)进行训练。
数据增强是应该在每个深度学习实践者的工具箱中应用的工具。我使用Python涵盖了计算机视觉深度学习实践者套件中的 数据增强 。
我们 在 79-81行初始化我们的ImageDataGenerator的 aug 。
从那里,让我们编译模型并开始训练:
# initialize the model
print("[INFO] compiling model...")
model = SmallerVGGNet.build(width=IMAGE_DIMS[1], height=IMAGE_DIMS[0],
depth=IMAGE_DIMS[2], classes=len(lb.classes_))
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS, verbose=1)
在第85和第86行,我们用96 x 96 x 3的 输入空间维度初始化我们的Keras CNN模型 。当我经常收到这个问题时,我会再次说明--SmallerVGGNet被设计为接受 96 x 96 x 3 输入图像。如果你想要使用不同的空间维度,你可能需要:
- 降低较小图像的网络深度
- 增加较大图像的网络深度
不要盲目编辑代码。考虑更大或更小的图像将首先带来的影响!
我们将使用 具有学习速率衰减的 Adam优化器(第87行),然后 使用分类交叉熵编译 我们的 模型,因为我们有> 2个类(88行和89行)。
注意:对于只有两个类别,你应该使用二元交叉熵作为损失。
从那里,我们打电话给 Keras fit_generator 方法来训练网络(93-97行)。请耐心等待 - 这可能需要一些时间,具体取决于你是使用CPU还是使用GPU进行训练。
一旦我们的Keras CNN完成了训练,我们将需要保存(1)模型和(2)标签二进制器,因为当我们在训练/测试集以外的图像上测试网络时,我们需要从磁盘加载它们:
我们序列化模型(第101行)和标签二进制器(第105-107行),以便稍后在我们的classify.py 脚本中使用它们 。
标签binarizer文件包含人类可读类标签字典的类索引。该对象确保我们不必在希望使用Keras CNN的脚本中对我们的类标签进行硬编码。
最后,我们可以绘制我们的训练和损失的准确性:
我选择将我的情节保存到磁盘(第 121行),而不是显示它,原因有两个:(1)我在云端的headless服务器上;(2)我想确保我不会忘记保存plot。
用Keras训练我们的CNN
现在我们准备训练我们的Pokedex CNN。
然后执行以下命令来训练模式; 同时确保正确提供命令行参数:
$ $ python train.py --dataset dataset --model pokedex.model --labelbin lb.pickle
Using TensorFlow backend.
[INFO] loading images...
[INFO] data matrix: 252.07MB
[INFO] compiling model...
[INFO] training network...
name: GeForce GTX TITAN X
major: 5 minor: 2 memoryClockRate (GHz) 1.076
pciBusID 0000:09:00.0
Total memory: 11.92GiB
Free memory: 11.71GiB
Epoch 1/100
29/29 [==============================] - 2s - loss: 1.4015 - acc: 0.6088 - val_loss: 1.8745 - val_acc: 0.2134
Epoch 2/100
29/29 [==============================] - 1s - loss: 0.8578 - acc: 0.7285 - val_loss: 1.4539 - val_acc: 0.2971
Epoch 3/100
29/29 [==============================] - 1s - loss: 0.7370 - acc: 0.7809 - val_loss: 2.5955 - val_acc: 0.2008
...
Epoch 98/100
29/29 [==============================] - 1s - loss: 0.0833 - acc: 0.9702 - val_loss: 0.2064 - val_acc: 0.9540
Epoch 99/100
29/29 [==============================] - 1s - loss: 0.0678 - acc: 0.9727 - val_loss: 0.2299 - val_acc: 0.9456
Epoch 100/100
29/29 [==============================] - 1s - loss: 0.0890 - acc: 0.9684 - val_loss: 0.1955 - val_acc: 0.9707
[INFO] serializing network...
[INFO] serializing label binarizer...
看看我们的训练脚本的输出结果,我们看到我们的Keras CNN获得了:
- 训练集上的分类准确率为96.84%
- 而 97.07%的准确度 测试集
训练损失/准确性图如下:
用Keras训练的Pokedex深度学习分类器的训练和验证损失/准确性图。
正如你在图3中看到的那样,我训练了100个时期的模型,并在有限的过拟合下实现了低损耗。利用额外的训练数据,我们也可以获得更高的准确性。
创建我们的CNN和Keras测试脚本
现在,我们的CNN已经过训练,我们需要实施一个脚本来对不属于我们训练或验证/测试集的图像进行分类。打开一个新的文件,将其命名classify.py ,并插入下面的代码:
# import the necessary packages
from keras.preprocessing.image import img_to_array
from keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
首先我们进口必要的包裹(2-9行)。
从那里,让我们解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to label binarizer")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
我们 需要解析三个必需的 命令行参数:
--model :我们刚刚训练的模型的路径。
- labelbin :标签二进制文件的路径。
--image:我们的输入图像文件路径。
这些参数中的每一个都是在第12-19行上建立和解析的 。请记住,你不需要修改这些行 - 我将向你展示如何使用运行时提供的命令行参数在下一节中运行该程序。
接下来,我们将加载并预处理图像:
# load the image
image = cv2.imread(args["image"])
output = image.copy()
# pre-process the image for classification
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
在这里,我们加载输入image (第22行)并 为显示目的制作一个称为output 副本 (第23行)。
然后我们 以与训练所用的方式完全相同的方式对image进行预处理 (26-29行)。
从那里,我们加载模型+标签二值化器,然后对图像进行分类:
# load the trained convolutional neural network and the label
# binarizer
print("[INFO] loading network...")
model = load_model(args["model"])
lb = pickle.loads(open(args["labelbin"], "rb").read())
# classify the input image
print("[INFO] classifying image...")
proba = model.predict(image)[0]
idx = np.argmax(proba)
label = lb.classes_[idx]
为了对图像进行分类,我们需要 内存中的 模型和标签二值化器。我们加载第34和35行。
随后,我们对图像进行分类 并创建 标签 (39-41行)。
剩余的代码块用于显示目的:
# we'll mark our prediction as "correct" of the input image filename
# contains the predicted label text (obviously this makes the
# assumption that you have named your testing image files this way)
filename = args["image"][args["image"].rfind(os.path.sep) + 1:]
correct = "correct" if filename.rfind(label) != -1 else "incorrect"
# build the label and draw the label on the image
label = "{}: {:.2f}% ({})".format(label, proba[idx] * 100, correct)
output = imutils.resize(output, width=400)
cv2.putText(output, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
# show the output image
print("[INFO] {}".format(label))
cv2.imshow("Output", output)
cv2.waitKey(0)
在第46行和第47行,我们从文件名中提取口袋妖怪的名字 ,并将其与标签进行比较 。基于此, 正确的 变量将是 “correct” 或 “incorrect” (正确或不正确)。显然,这两行假设你的输入图像具有包含真实标签的文件名。
从那里我们采取以下步骤:
将类标签 (第50行)添加概率百分比和 “正确” / “不正确”文本 。
调整输出 图像的大小, 使其适合我们的屏幕(第51行)。
在输出 图像上绘制 标签文本 (第52和53行)。
显示 输出 图像并等待按键退出(第57和58行)。
用我们的CNN和Keras分类图像
我们现在准备运行classify.py 脚本!
一旦你下载了解压缩文件并将其解压缩到这个项目的根目录下,然后从Charmander的图像开始。请注意,我们提供了三个命令行参数来运行脚本:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/charmander_counter.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] charmander: 99.77% (correct)
现在让我们来看一下我们的模型,妙蛙种子:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/bulbasaur_plush.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] bulbasaur: 99.35% (correct)
让我们来尝试一下超梦 :
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/mewtwo_toy.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] mewtwo: 100.00% (correct)
如果Pokedex无法识别皮卡丘:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/pikachu_toy.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] pikachu: 99.58% (correct)
让我们试试可爱的杰尼龟:
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/squirtle_plush.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] squirtle: 98.62% (correct)
最后,我们再次分类小火龙。这次不完整,被我的显示器遮住了一部分。
$ python classify.py --model pokedex.model --labelbin lb.pickle \
--image examples/charmander_hidden.png
Using TensorFlow backend.
[INFO] loading network...
[INFO] classifying image...
[INFO] charmander: 59.82% (correct)
这些宠物小精灵中的每一个都不匹配我的新Pokedex。
目前,大约有807种不同的口袋妖怪。我们的分类器只训练了五种不同的口袋妖怪(为了简单起见)。
如果你想要训练一个分类器来识别更多的口袋妖怪来获得更大的Pokedex,你需要为每个类增加额外的训练图像。 理想情况下,你的目标应该是每个班级有500-1,000张图片可供你识别。
模型的局限性
这种模式的主要局限之一是少量的训练数据。我测试了各种图像,有时分类不正确。发生这种情况时,我更仔细地检查了输入图像+网络,发现图像中最主要的颜色显著影响分类。
例如,图像中的许多红色和橙色可能会返回 “小火龙”作为标签。同样,图像中的黄色通常会产生 “皮卡丘”标签。
理想情况下,训练卷积神经网络时,每类至少应有500-1,000幅图像。在处理你自己的数据时请记住这一点。
在下篇文章中,我将展示如何将我们训练的Keras +卷积神经网络模型部署到智能手机!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消