


















通过简单的线性回归理解机器学习的基本原理
在本文中,我将使用一个简单的线性回归模型来解释一些机器学习(ML)的基本原理。线性回归虽然不是机器学习中最强大的模型,但由于容易熟悉并且可解释性好,所以仍然被广泛使用。简单地说,线性回归用于估计连续或分类数据之间的线性关系。
我将使用X和y来表示变量。如果你喜欢更具体的东西,可以想象y是销售额,X是广告支出,我们想估计广告花费如何影响销售额。我将展示一个线性回归如何学习绘制最适合通过这些数据的线:
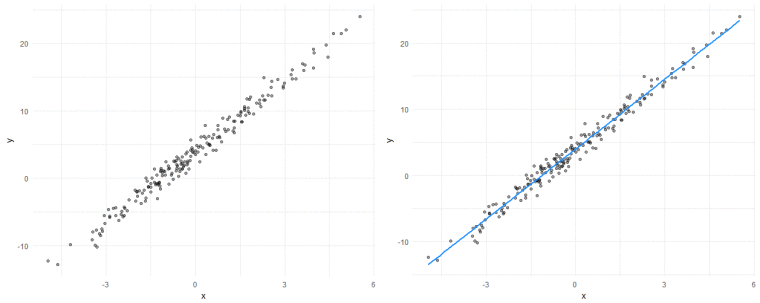
机器学到了什么?
机器学习最基础的问题是:
“机器(即统计模型)实际上学到了什么?”
这取决于不同的模型,但简单来说,模型学习函数f,使f(X)映射到y。换句话说,模型学习如何采取X(即特征,或者说自变量(S)),预测y(目标,或者说因变量)。
在简单的线性回归的情况下(y ~ b0 + b1 * X,其中X是列)的模型“学习”两个参数:
- B0:偏置(或者说,截距)
- b1:斜率
当X为0时的y水平坐标等于偏置(即广告支出为零时的销售额的值),斜率是X中每单位增长或减少对y预测增长或减少的比率(即,每英镑花在广告上会带来多少销售额的增长)。两个参数都是标量。
一旦模型学习到这些参数,你就可以用给定X值来计算y的估计值。换句话说,当你不知道y是什么时候,你可以用这些它们来预测y的值,这是一个预测模型!
学习参数:成本函数
学习LR模型的参数有几种方法,我将着重于最好说明统计学习的方法: 最小化成本函数。
请记住,机器学习的重点是从数据中学习。我们用一个简单的比喻来说明。对于孩子,我们通常会通过告知他禁止做什么事情,或者因为做了不该做的事情而让他受到惩罚的方式,教会他理解正确的行为。例如,你可以想象一个四岁的孩子坐在火旁保暖,但因为他不知道火的危险,她把手指放了进去烧伤了。下一次他坐在火旁,他就不会因为玩火导致烧伤,但是也许他会因为坐得离火太近,太热,不得不离开。第三次他坐在火旁边,发现有一个距离让她既可以保持温暖,也不会让她受到任何危险。换句话说,通过经验和反馈,孩子掌握了与火的最佳距离。这个例子中的火的热量是一个成本函数。
在机器学习中,使用成本函数来估计模型的表现。简而言之,成本函数是衡量模型在估计X和Y之间关系方面的错误程度的度量。成本函数(你也可以参考损失函数或误差函数)可以通过迭代地运行模型来估计的对“地面真值”(即y的已知值)的预测。
因此,ML模型的目标是找到使成本函数最小化的参数,权重或结构。
最小化成本函数:梯度下降
既然我们知道模型是通过最小化成本函数来学习的,那么你可能想知道成本函数是如何最小化的,那么让我们开始介绍梯度下降。梯度下降是一种有效的优化算法,试图找到函数的局部或全局最小值。
梯度下降使模型能够学习模型应该采取的梯度或方向,以减少误差(实际y与预测y之间的差异)。简单线性回归示例中的方向是指如何调整或修正模型参数b0和b1以进一步降低成本函数。随着模型迭代,它逐渐收敛到最小值,继续对参数做更进一步的调整只能产生很小(甚至没有)的损失变化。
这个过程是整个ML过程不可或缺的一部分,它极大地加快了学习过程。梯度下降过程的替代方案可能是粗暴地穷举所有可能的参数组合,直到确定使成本最小化的组为止。显而易见,这是不可行的。因此,梯度下降使得学习过程能够对所学习的估计进行纠正更新,将模型导向最佳参数组合。
在线性回归模型中观察学习
为了在线性回归中观察学习,我手动设置参数b0和b1并使用模型从数据中学习这些参数。换句话说,我们知道X与y之间关系的地面真值,并且可以通过参数迭代校正对成本的回应来观察学习这种关系的模型。
library(dplyr)
library(ggplot2)
n <- 200 # number of observations
bias <- 4
slope <- 3.5
dot <- `%*%` # defined for personal preference
x <- rnorm(n) * 2
x_b <- cbind(x, rep(1, n))
y <- bias + slope * x + rnorm(n)
df <- data_frame(x = x, y = y)
learning_rate <- 0.05
n_iterations <- 100
theta <- matrix(c(20, 20))
b0 <- vector("numeric", length = n_iterations)
b1 <- vector("numeric", length = n_iterations)
sse_i <- vector("numeric", length = n_iterations)
这里我定义了偏置和斜率(分别等于4和3.5)。我也为X添加了一个列(用于支持矩阵乘法)。我也给y添加了一些高斯噪声来掩盖真正的参数,即创建完全随机的误差。现在我们有一个包含两个变量X和y的dataframe,这个变量似乎有一个正的线性趋势(即y随着增加X值而增加)。
接下来我定义了学习率,它控制每个梯度的步骤大小。如果这太大,模型可能会错过函数的局部最小值。如果太小,模型会需要很长时间才能收敛。Theta存储参数b0和b1,它们用随机值初始化。n_iterations控制模型迭代和更新值的次数。最后,在模型的每次迭代中,我创建了一些占位符来捕获b0,b1的值和误差平方和(SSE)。
这里的SSE是成本函数,它仅仅是预测y和实际y之间的平方差的和(即残差)。
现在,我们运行循环。在每次迭代中,模型将根据Theta值预测y,计算残差,然后应用梯度下降估计校正梯度,然后使用这些梯度更新theta的值,重复此过程100次。当循环结束时,我创建一个dataframe来存储学习的参数和每次迭代的损失。
for (iteration in seq_len(n_iterations)) {
residuals_b <- dot(x_b, theta) - y
gradients <- 2/n * dot(t(x_b), residuals_b)
theta <- theta - learning_rate * gradients
sse_i[[iteration]] <- sum((y - dot(x_b, theta))**2)
b0[[iteration]] <- theta[2]
b1[[iteration]] <- theta[1]
}
model_i <- data.frame(model_iter = 1:n_iterations,
sse = sse_i,
b0 = b0,
b1 = b1)当迭代完成后,我们可以绘制超过模型估计的线。
p1 <- df %>%
ggplot(aes(x=x, y=y)) +
geom_abline(aes(intercept = b0,
slope = b1,
colour = -sse,
frame = model_iter),
data = model_i,
alpha = .50
) +
geom_point(alpha = 0.4) +
geom_abline(aes(intercept = b0,
slope = b1),
data = model_i[100, ],
alpha = 0.5,
size = 2,
colour = "dodger blue") +
geom_abline(aes(intercept = b0,
slope = b1),
data = model_i[1, ],
colour = "red",
alpha = 0.5,
size = 2) +
scale_color_continuous(low = "red", high = "grey") +
guides(colour = FALSE) +
theme_minimal()
p2 <- model_i[1:30,] %>%
ggplot(aes(model_iter, sse, colour = -sse)) +
geom_point(alpha = 0.4) +
theme_minimal() +
labs(x = "Model iteration",
y = "Sum of Sqaured errors") +
scale_color_continuous(low = "red", high = "dodger blue") +
guides(colour = FALSE)
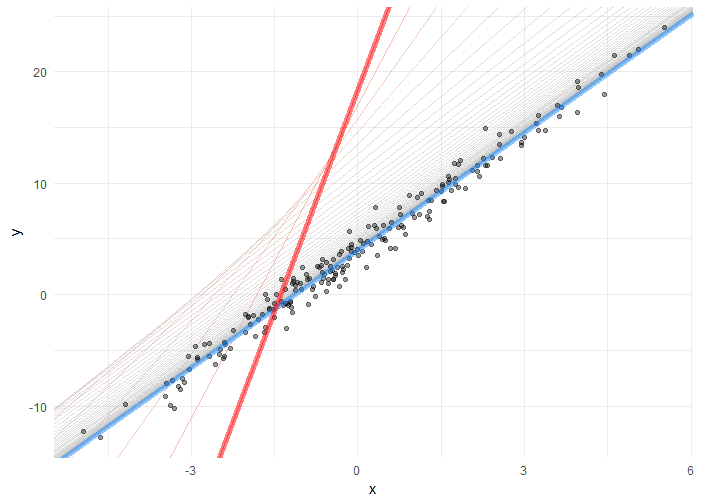
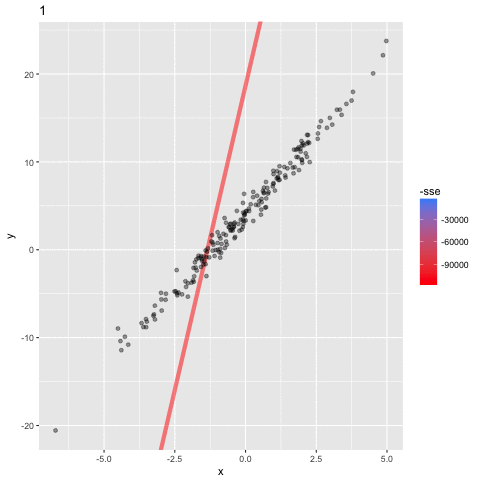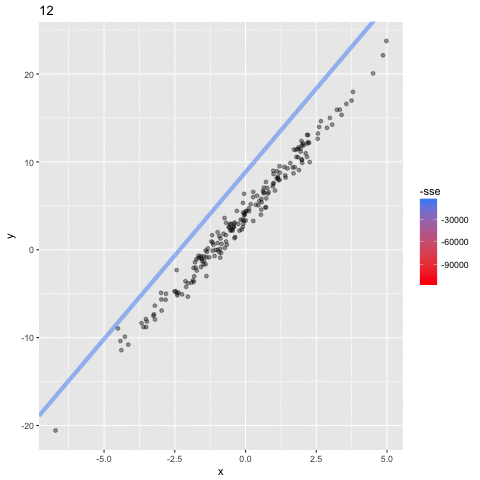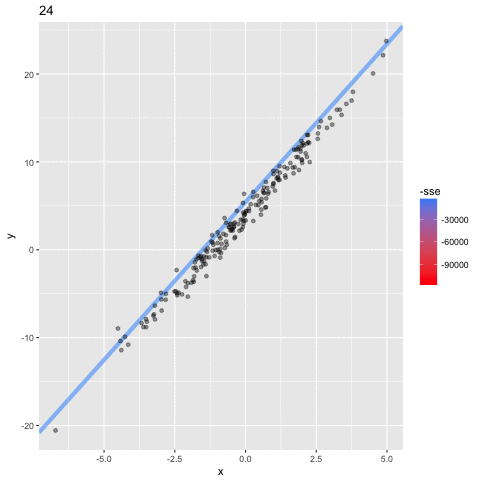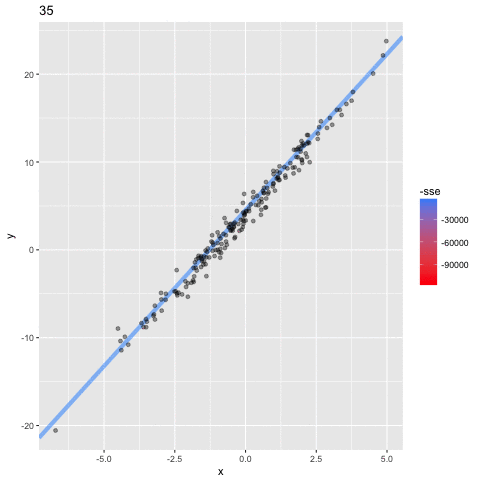
首先要注意的是粗的红线。这是从b0和b1的初始值估计的线。你可以看到,这并不适合数据点,正因为如此,它有最高的SSE。但是,你会看到逐渐向数据点移动的线,直到找到最适合的线(粗蓝线)。换句话说,在每次迭代时,模型为b0和b1学习了更好的值,直到找到最小化成本函数的值为止。模型学习b0和b1的最终值分别是3.96和3.51,因此非常接近我们设置的参数4和3.5。
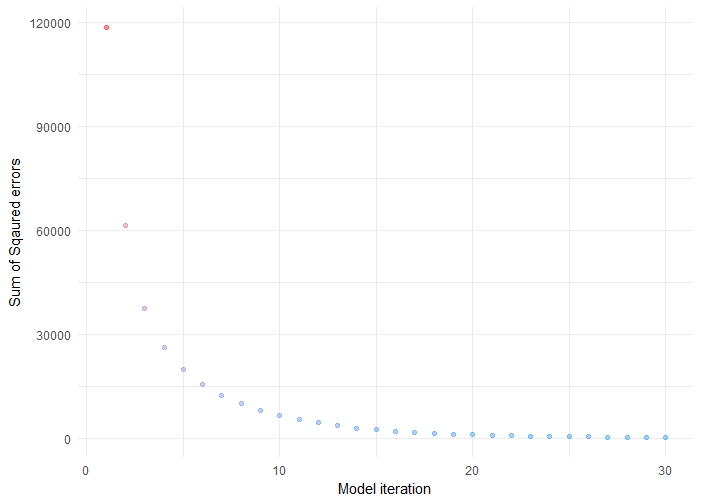
我们还可以在模型的迭代中看到SSE的减少。在收敛和稳定之前,它在早期迭代中急剧下降。
我们现在可以使用的B0和B1存储在theta的学习值为新的X值预测y值。
predict_from_theta < - function(x){
x < - cbind(x,rep(1,length(x)))
点(x,theta)
}
predict_from_theta(rnorm(10))
[,1 ]
[ 1,] - 1.530065
[ 2,] 8.036859
[ 3,] 6.895680
[ 4,] 3.170026
[ 5,] 4.905467
[ 6,] 2.644702
[ 7,] 12.555390
[ 8,] 1.172425
[ 9,] 3.776509
[ 10,] 4.849211总结
本文介绍了一种简要理解机器学习的方法。毫无疑问,机器学习还有很多知识本文中没有被提到,但是了解“底层”的基本原理获得初步的直觉可以大大提高你对更复杂模型的理解。









