










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
dlicari/distil-ita-legal-bert


 英文
英文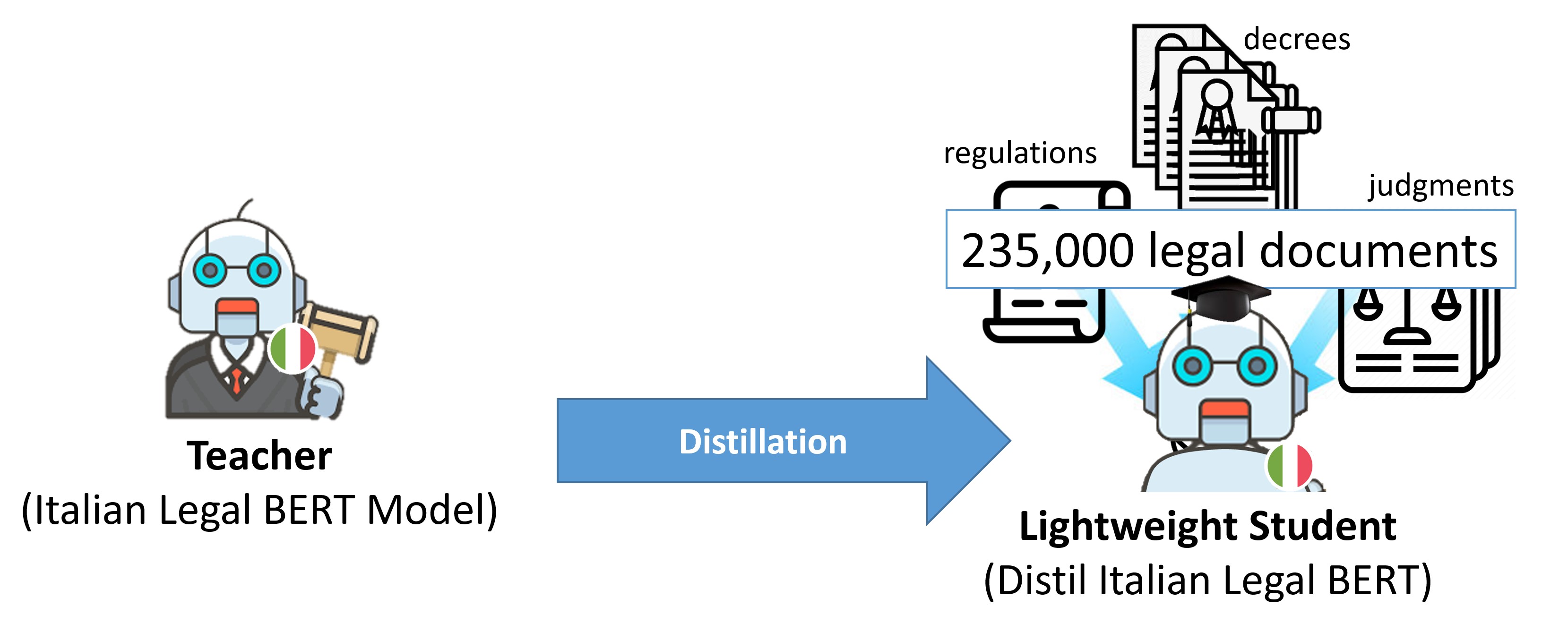
DISTIL-ITA-LEGAL-BERT
我们使用知识蒸馏的过程,创建了一个快速、轻量级的学生模型,只有4个级别的Transformer,能够生成与复杂的ITALIAN-LEGAL-BERT教师模型产生的句子嵌入相似的句子嵌入。
它在ITALIAN-LEGAL-BERT训练集(3.7 GB)上进行了优化,使用Sentence-BERT库,通过最小化其嵌入和教师模型产生的嵌入之间的均方误差(MSE)。
这是一个 sentence-transformers 模型:它将句子和段落映射到一个768维的稠密向量空间,并可用于聚类或语义搜索等任务。
用法(Sentence-Transformers)
如果已经安装了 sentence-transformers ,使用这个模型变得很容易:
pip install -U sentence-transformers
然后你可以像这样使用模型:
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('dlicari/distil-ita-legal-bert')
embeddings = model.encode(sentences)
print(embeddings)
用法(HuggingFace Transformers)
如果没有 sentence-transformers ,你可以像这样使用模型:首先,你通过变换器模型传递输入,然后你必须在上下文词嵌入之上应用正确的池化操作。
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('dlicari/distil-ita-legal-bert')
model = AutoModel.from_pretrained('dlicari/distil-ita-legal-bert')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
评估结果
对于这个模型的自动评估,请参见Sentence Embeddings Benchmark:
https://seb.sbert.net训练
该模型的训练参数如下:
DataLoader:
torch.utils.data.dataloader.DataLoader的长度为409633,参数如下:
{'batch_size': 24, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
Loss:
sentence_transformers.losses.MSELoss.MSELoss
fit()方法的参数:
{
"epochs": 4,
"evaluation_steps": 5000,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"correct_bias": false,
"eps": 1e-06,
"lr": 0.0001
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
完整的模型架构
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)