


















腾讯的新Hy3 AI模型:高效的中文大模型
腾讯在周四悄然推出了其迄今为止最强大的AI模型,基准测试数据令人瞩目。Hy3预览版是公司在全面基础设施重建后的首个模型,今天在GitHub、Hugging Face和ModelScope上开源。
它也可以在腾讯云的官方网站上通过付费计划获得。
Hy3总共拥有2950亿参数(衡量模型潜在知识广度的指标),但在任何给定时间只有210亿是活跃的。这就是专家混合架构的优势——模型将每个查询路由到其“专家”子网络的一个专门子集,而不是一次性运行所有内容。计算量更少,成本更低,输出质量大致相同。它还支持多达256,000个上下文标记,足以在单个提示中处理一本完整的小说。
该模型旨在平衡腾讯表示不再相互牺牲的三件事:能力广度、诚实评估和成本效益。他们之前的旗舰Hy2拥有超过4000亿参数。腾讯明确表示回撤,认为2950亿是推理完全成熟但增加更多参数的成本不再值得的最佳平衡点。
这并不意味着模型更差。经过更好训练且参数更少的模型经常超越更大的通用模型。
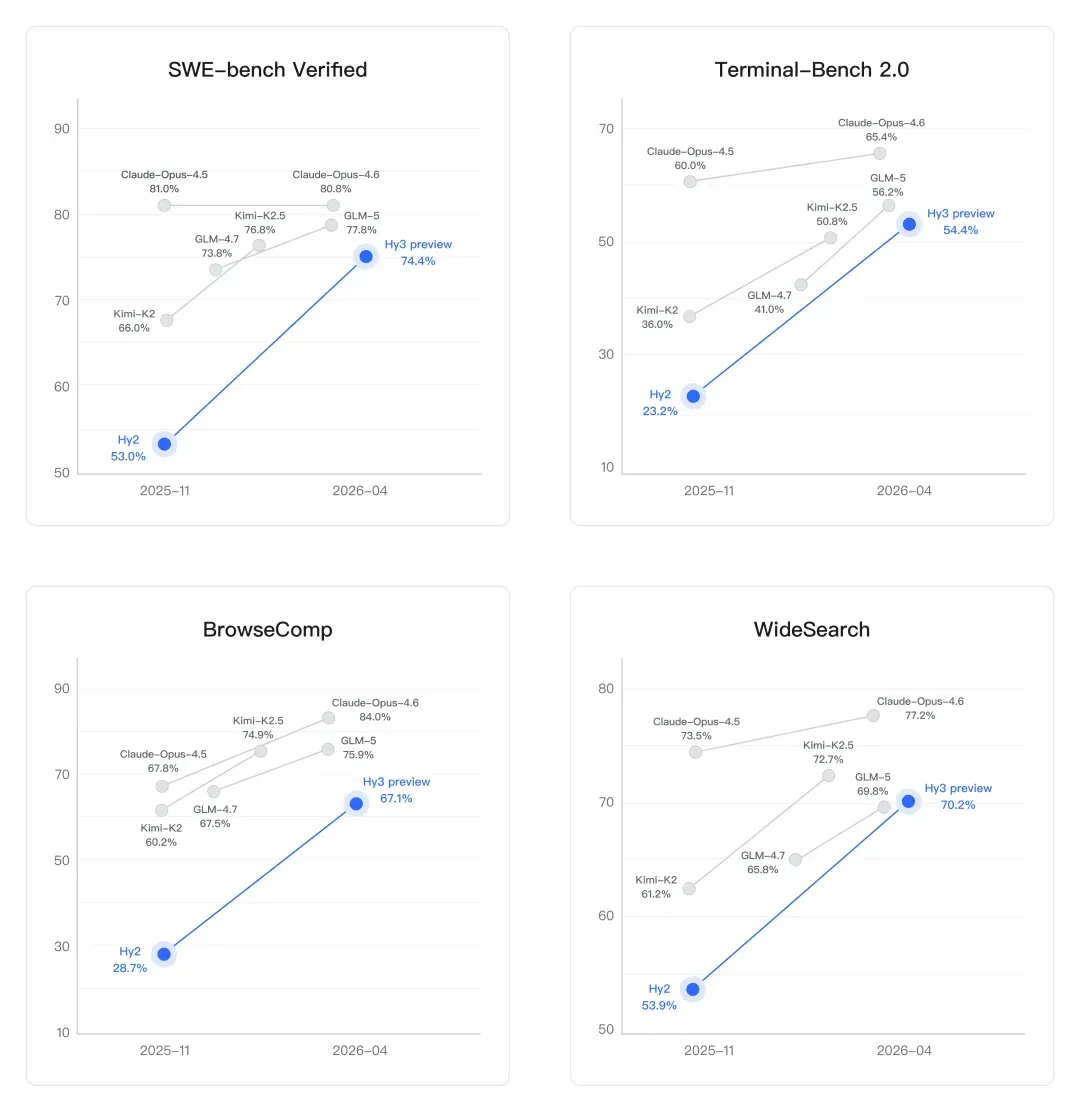
在编码方面,改进是显著的。SWE-bench Verified是一个基准测试,测试模型是否能实际修复GitHub存储库中的真实错误——不是玩具问题,而是生产代码。Hy2得分为53.0%。Hy3预览版得分为74.4%。这是一代之间40%的跃升,使其达到Claude Opus 4.6(80.8%)的范围,并超过GLM-5(77.8%)和Kimi-K2.5(76.8%)。Terminal-Bench 2.0,测量在真实命令行环境中的自主任务执行,从23.2%提高到54.4%——也是一个巨大的飞跃。
然而,对于使用代理构建的人来说,该模型可能是一个非常有趣的选择。代理有一套非常复杂的指令,涉及记忆、技能和工具调用。它们通常会遗漏一些东西,这可能会破坏工作流程或产生不良结果。这就是为什么代理能力对于AI开发者来说变得越来越重要,因为这个领域成为行业中最受关注的事情。这也是为什么该模型立即在Openclaw上提供。
搜索和浏览代理——模型必须从开放网络中检索、过滤和综合信息而无需人工指导——也大幅改善。在BrowseComp上,一个跟踪复杂网络研究任务的基准测试中,Hy3预览版达到67.1%(从Hy2的28.7%提高)。在WideSearch上,它达到70.2%,超过GLM-5和Kimi-K2.5,但落后于Claude Opus 4.6的77.2%。
在推理方面,该模型在清华大学数学博士资格考试(2026年春季)中超过了所有中国竞争对手,三次运行的平均得分为88.4。这是真实世界的考试,而不是策划的数据集——腾讯表示优先考虑这种评估以避免基准测试作弊。该模型还在CHSBO 2025(中国国家高中生物奥林匹克竞赛)中得分87.8,是该类别中中国模型中的最高分。
Hy3预览版于2026年1月底开始训练,并于周四发布——从冷启动到开源发布不到三个月。对于一个前沿级模型来说,这个速度异常快。腾讯将其归因于2月份由其首席AI科学家姚顺宇领导的基础设施大修,他推动了预训练和强化学习堆栈的全面重建。
这与一年前中国AI实验室的做法截然不同,当时DeepSeek的R1以其成本效益震惊了行业。
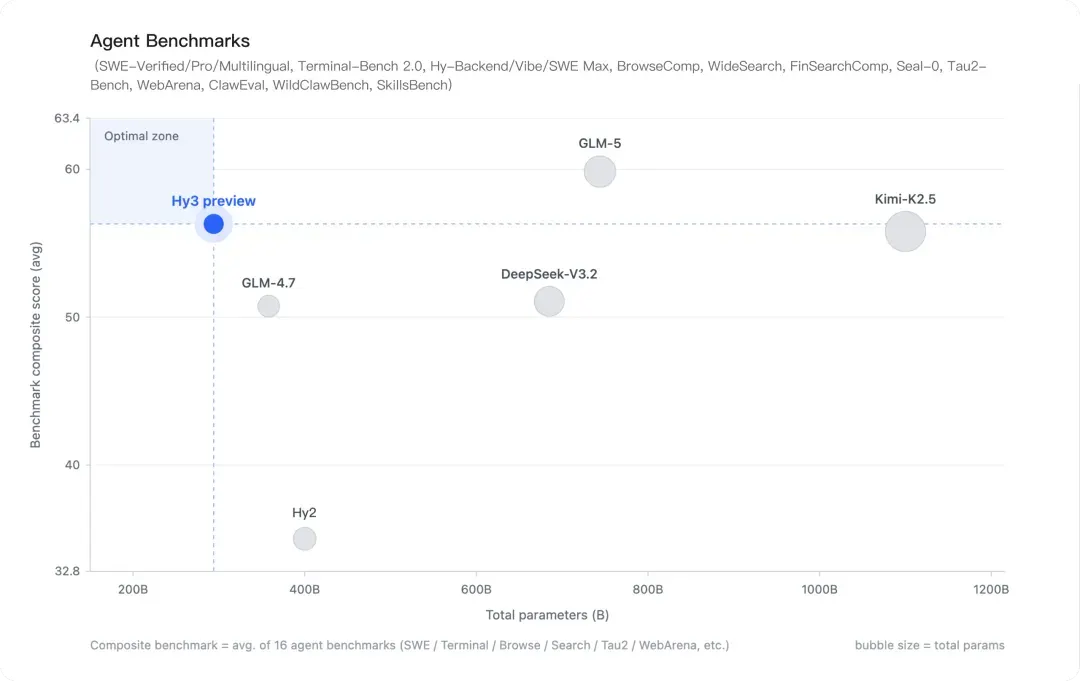
Hy3仍然落后于OpenAI和Google DeepMind的旗舰产品,但按尺寸与性能比来看,Hy3预览版难以忽视:代理基准综合显示其处于“最佳区域”,拥有约2950亿参数,领先于DeepSeek-V3.2(超过6000亿)并与Kimi-K2.5(超过1万亿参数)匹配,而计算成本仅为其一小部分。
混元模型已经在元宝、CodeBuddy、WorkBuddy、QQ和腾讯文档中部署。在CodeBuddy和WorkBuddy上,首个标记延迟下降54%,端到端生成时间减少47%,模型成功运行了长达495步的代理工作流。腾讯云提供API访问,价格约为每百万输入标记0.18美元和每百万输出标记0.59美元,个人标记计划套餐起价约为每月4.10美元。









