


















Ai2推出一系列开源AI开发代理,适用于任何代码库

人工智能正在迅速发展,改变了开发者的创作方式。代码流动速度加快,进入GitHub等代码库,机器智能现在与人类协作。
根据艾伦人工智能研究所的说法,编码代理存在一个根本问题:大多数是封闭的,训练成本高,难以研究或适应私有代码库。为了解决这个问题,公司今天发布了Ai2开放编码代理,这是一套使构建和训练自定义编码代理变得简单易行的工具。
该系列的首次发布名为SERA,即软验证高效代码库代理,能够解决超过55%的SWE-Bench验证问题,这一基准超越了先前同等规模的开源模型。
SERA的每个组件都是开放的,包括模型、代码和与Anthropic PBC的Claude Code的集成。它还可以通过一行代码启动。用户不需要任何大型语言模型训练经验。
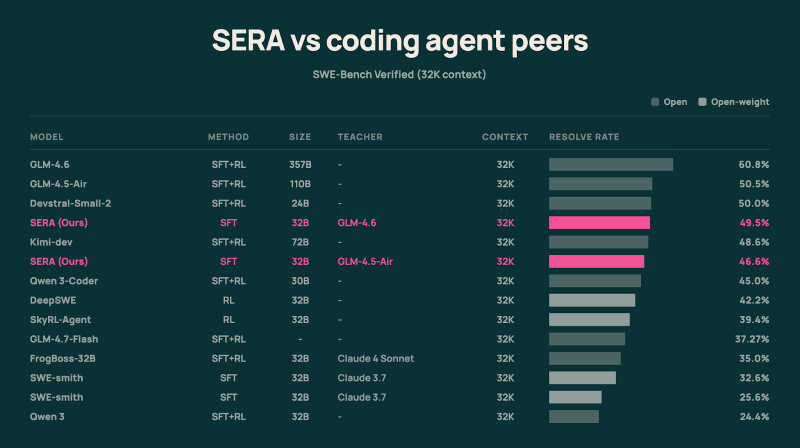
在内部,SERA有两个版本:SERA-32B和SERA-8B。第一个是一个320亿参数的模型,提供强大的SWE-bench验证性能。在标准设置中解决约55%的问题,优于大多数开源模型如Qwen3-Coder,以及封闭模型如Mistral3的Devstral Small 2。在匹配的推理设置中,第二个是一个80亿参数的模型,解决了29.4%的SWE-Bench验证问题,而在强化学习基线中为9.4%;例如,模型如SkyRL-Agent-8B-v0使用Qwen 3 8B模型解决9.4%的问题,而SERA-8B达到更高的评分。
Ai2使用专门的模型,每个代码库训练8000个合成轨迹,性能始终匹配并经常超过GLM-4.5-Air的表现,这是一种超过1000亿参数的模型,作为教师使用。
Ai2表示,一个特别有前景的结果是,较小的完全开放模型可以复制甚至超过更强大的“教师”编码代理的性能。由于在特定代码库上进行的有利的专业化和在320亿参数级别的微调,SERA可以超越一些1000亿通用模型,体积仅为其三分之一。在部署时,这意味着更小的内存占用和更低的计算成本,从而大大降低了成本,而不牺牲质量。
Ai2在普通云硬件上重现主要结果的总成本约为400美元,比市场上许多现有方法便宜约100倍。
公司解释说,发布包括开发者和研究人员需要的一切,以便快速上手重现、测试和构建SERA:基于两行代码的轻量级部署,用于启动、部署和推理。还有一个设置脚本和推理优化,使SERA能够与Claude Code一起工作。
Ai2表示,计划使用相同的方法继续改进并扩展到更大的骨干网络,但坚持认为当前的流程已经便宜且可行,任何人都可以运行、定制和迭代。









