


















谷歌推出新LiteRT加速器,加速骁龙安卓设备上的AI工作负载
谷歌为LiteRT推出了一款名为高通AI引擎直通(QNN)的全新加速器,旨在提升搭载骁龙8 SoC的高通安卓设备的AI性能。该加速器显著提高了性能,相较于CPU执行速度提升了最多100倍,相较于GPU提升了10倍。
尽管现代安卓设备普遍配备了GPU硬件,但谷歌的软件工程师卢王、Wiyi Wanf和安德鲁·王指出,单靠GPU处理AI任务可能会导致性能瓶颈。例如,他们提到,“在设备上运行一个计算密集型的文本到图像生成模型,同时使用基于机器学习的分割处理实时相机画面”可能会让即使是高端移动GPU也难以承受。结果可能导致用户体验卡顿和掉帧。
然而,许多移动设备现在配备了神经处理单元(NPUs),这些专门设计的AI加速器与GPU相比,可以显著加速AI工作负载,同时消耗更少的电力。
QNN是谷歌与高通密切合作开发的,用来替代之前的TFLite QNN代理。它通过集成广泛的SoC编译器和运行时,并通过简化的API提供给开发者,提供了统一和简化的工作流程。它支持90个LiteRT操作,目标是实现完整模型委托,这是实现最佳性能的关键因素。QNN还包括专门的内核和优化,进一步提升了像Gemma和FastLVM这样的LLM的性能。
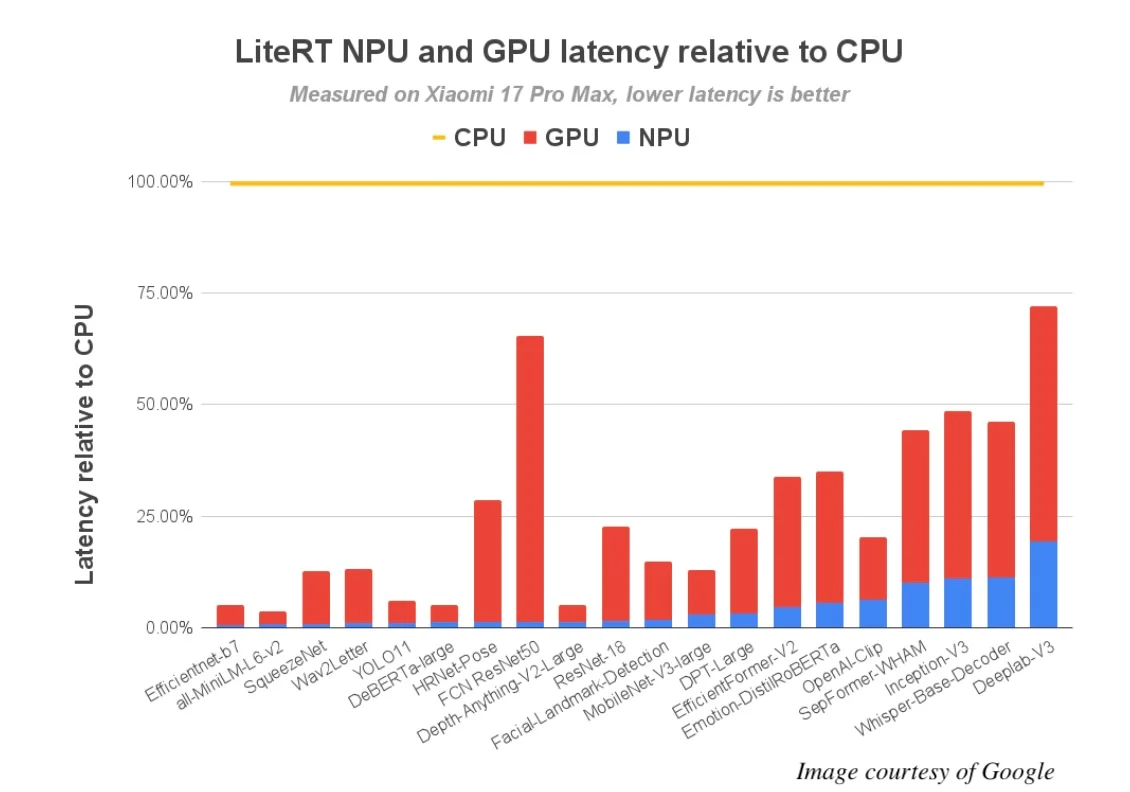
谷歌对72个机器学习模型进行了QNN基准测试,其中64个成功实现了完整的NPU委托。结果显示,与CPU执行相比,性能提升高达100倍,与GPU相比提升10倍。
在高通最新的旗舰SoC,骁龙8 Elite Gen 5上,性能提升显著:超过56个模型在NPU上运行时间不到5毫秒,而在CPU上只有13个模型能达到这一速度。这解锁了许多之前无法实现的实时AI体验。
谷歌工程师还开发了一个概念应用,利用了苹果FastVLM-0.5B视觉编码模型的优化版本。该应用几乎可以即时解释相机的实时场景。在骁龙8 Elite Gen 5 NPU上,它在1024×1024图像上的首次令牌时间(TTFT)仅为0.12秒,预填充速度超过11,000令牌/秒,解码速度超过100令牌/秒。苹果的模型通过int8权重量化和int16激活量化进行了优化。根据谷歌工程师的说法,这是解锁NPU最强大、高速int16内核的关键。
QNN仅支持有限的安卓硬件子集,主要是由骁龙8和骁龙8+ SoC驱动的设备。要开始使用,请访问NPU加速指南并下载GitHub上的LiteRT。









