


















谷歌的机器人现在可以思考、搜索网络并自学新技能

谷歌DeepMind本周推出了两个AI模型,旨在让机器人比以往更聪明。更新后的Gemini Robotics 1.5及其伴侣Gemini Robotics-ER 1.5不再专注于执行指令,而是让机器人思考问题、在互联网上搜索信息,并在不同的机器人代理之间传递技能。
据谷歌称,这些模型标志着“能够以智能和灵活性驾驭物理世界复杂性的基础步骤”。
“Gemini Robotics 1.5标志着在物理世界中解决AGI的重要里程碑,”谷歌在公告中表示。 “通过引入代理能力,我们超越了对命令做出反应的模型,创建了能够真正推理、计划、主动使用工具和泛化的系统。”
而这个术语“泛化”很重要,因为模型在这方面存在困难。
机器人——以及一般的算法——通常在这方面存在困难。例如,如果你教一个模型折叠一条裤子,它将无法折叠一件T恤,除非工程师提前编程每一个步骤。
新的模型改变了这一点。它们可以捕捉线索、读取环境、做出合理的假设,并执行过去无法实现的多步骤任务——或者至少对机器来说极其困难的任务。。
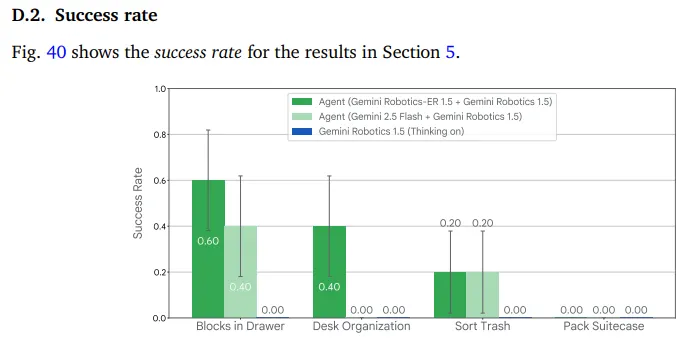
但更好并不意味着完美。例如,在其中一个实验中,团队向机器人展示了一组物品,并要求它们将其放入正确的垃圾桶。机器人使用其摄像头视觉识别每个物品,在线查找旧金山最新的回收指南,然后将它们放置在理想的位置,就像当地人一样。

这个过程结合了在线搜索、视觉感知和逐步计划——做出超越旧机器人能力的情境感知决策。注册的成功率在20%到40%之间;虽然不理想,但对于一个以前无法理解这些细微差别的模型来说,已经令人惊讶。
谷歌如何将机器人变成超级机器人
这两个模型分工合作。Gemini Robotics-ER 1.5像大脑一样,弄清楚需要发生什么并创建一个逐步计划。当需要信息时,它可以调用谷歌搜索。一旦有了计划,它就将自然语言指令传递给Gemini Robotics 1.5,后者负责实际的物理动作。
更技术性地说,新的Gemini Robotics 1.5是一个视觉-语言-动作(VLA)模型,将视觉信息和指令转化为运动指令,而新的Gemini Robotics-ER 1.5是一个视觉-语言模型(VLM),创建多步骤计划以完成任务。
例如,当机器人分类洗衣时,它会通过一系列思考来内部推理任务:理解“按颜色分类”意味着白色放在一个箱子里,彩色放在另一个箱子里,然后分解出拾取每件衣物所需的具体动作。机器人可以用简单的英语解释其推理,使其决策不再是一个黑箱。
谷歌CEO桑达尔·皮查伊在X上发表了意见,指出新模型将使机器人更好地推理、提前计划、使用搜索等数字工具,并在不同类型的机器人之间转移学习。他称之为谷歌“迈向真正有用的通用机器人的重要一步。”
新的Gemini Robotics 1.5模型将使机器人更好地推理、提前计划、使用搜索等数字工具,并在不同类型的机器人之间转移学习。我们迈向真正有用的通用机器人的重要一步——你可以看到机器人如何推理……pic.twitter.com/kw3HtbF6Dd
——桑达尔·皮查伊 (@sundarpichai)2025年9月25日
这一发布使谷歌与特斯拉、Figure AI和波士顿动力等开发商共享聚光灯,尽管每家公司采取不同的方法。特斯拉专注于其工厂的大规模生产,埃隆·马斯克承诺到2026年生产数千台。波士顿动力继续推动机器人运动能力的极限,其Atlas机器人能做后空翻。与此同时,谷歌押注于使机器人适应任何情况而无需特定编程的AI。
时机很重要。美国机器人公司正在推动制定国家机器人战略,包括在中国将AI和智能机器人作为国家优先事项的时刻,建立一个专注于促进该行业的联邦办公室。根据总部位于德国的国际机器人联合会的数据,中国是全球最大的工厂和其他工业环境中工作的机器人市场,2023年约有180万台机器人在运行。
DeepMind的方法不同于传统的机器人编程,后者需要工程师精心编写每一个动作的代码。相反,这些模型通过演示学习,并能随时适应。如果物体从机器人的抓握中滑落或有人在任务中途移动了某物,机器人会调整而不会错过节拍。
这些模型建立在DeepMind早期的工作基础上,三月份时机器人只能处理单一任务,如解开包或折纸。现在它们正在处理许多人类都难以应对的序列任务——例如在查看天气预报后为旅行适当打包。
对于想要实验的开发者来说,存在一种分裂的可用性方法。Gemini Robotics-ER 1.5于周四通过谷歌AI Studio的Gemini API推出,这意味着任何开发者都可以开始使用这个推理模型进行构建。动作模型Gemini Robotics 1.5仍然仅限于“精选”(可能是“富有的”)合作伙伴。









