


















如何构建MCP以自动化我的数据科学工作

在本文中,我将分解:
- 通过数据科学MCP节省的时间和结果
- 用于创建MCP的资源和参考材料
- 我集成到工作流程中的基本设置、API和服务
# 构建数据科学MCP
如果你还不知道MCP是什么,它代表模型上下文协议,是一个允许你将大型语言模型连接到外部服务的框架。
这个视频是MCP的一个很好的介绍。
//核心问题
我想通过我的新数据科学MCP解决的问题是:
我如何整合分散在各个来源的信息并生成可以直接被利益相关者和团队成员使用的结果?
为此,我构建了一个包含三个组件的MCP,如下图所示:
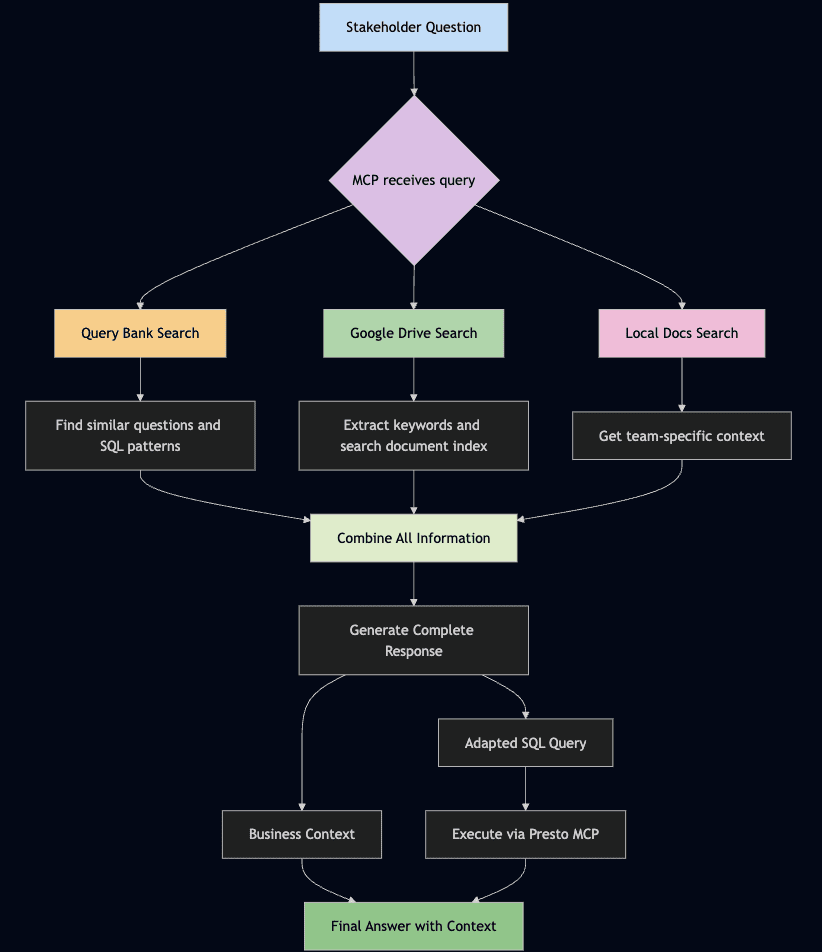
//组件1:查询库集成
作为我的MCP的知识库,我使用了团队的查询库(其中包含问题、回答问题的示例查询以及关于表格的一些背景信息)。
当利益相关者问我这样的问题时:
广告收入中有多少百分比来自搜索广告?
我不再需要查看多个表格和列名来生成查询。相反,MCP在查询库中搜索类似问题。然后,它获取关于应查询的相关表格的背景信息,并将这些查询适应于我的具体问题。我所需要做的就是调用MCP服务器,粘贴我的利益相关者的请求,我在几分钟内就能得到相关的查询。
//组件2:Google Drive集成
产品文档通常存储在Google Drive中——无论是幻灯片、文档还是电子表格。
我将MCP服务器连接到团队的Google Drive,因此它可以访问我们几十个项目的所有文档。这有助于快速提取数据并回答诸如以下问题:
你能告诉我们上个月的广告收入是多少吗?
我还对这些文档进行了索引以提取特定的关键词和标题,因此MCP只需根据查询浏览关键词列表,而不是一次访问数百页。
例如,如果有人问与“移动视频广告”相关的问题,MCP将首先通过文档索引搜索以识别最相关的文件,然后再查看它们。
//组件3:本地文档访问
这是MCP最简单的组件,我有一个本地文件夹,MCP会在其中搜索。我根据需要添加或删除文件,允许我在团队项目的基础上添加自己的背景信息、信息和指令。
# 总结:我的数据科学MCP如何工作
以下是我的MCP目前如何工作以回答临时数据请求的示例:
- 问题来了:“我们在第三季度提供了多少视频广告展示次数,我们的广告需求相对于供应是多少?”
- 文档检索MCP在我们的项目文件夹中搜索“Q3”、“视频”、“广告”、“需求”和“供应”,并找到相关的项目文档
- 然后从团队文档中检索有关第三季度视频广告活动、其供应和需求的具体细节
- 它在查询库中搜索关于广告服务的类似问题
- 它使用从文档和查询库中获得的背景信息生成关于第三季度视频活动的SQL查询
- 最后,查询被传递到一个连接到Presto SQL的单独MCP中,自动执行
- 然后我收集结果,审核并发送给我的利益相关者
# 实施细节
以下是我如何实现这个MCP的:
//步骤1:Cursor安装
我使用Cursor作为我的MCP客户端。你可以从这个链接安装Cursor。它本质上是一个AI代码编辑器,可以访问你的代码库并用来生成或修改代码。
//步骤2:Google Drive凭证
几乎所有MCP使用的文档(包括查询库)都存储在Google Drive中。
要让你的MCP访问Google Drive、Sheets和Docs,你需要设置API访问:
- 进入Google Cloud Console并创建一个新项目。
- 启用以下API:Google Drive、Google Sheets、Google Docs。
- 创建凭证(OAuth 2.0客户端ID)并将其保存在一个名为
credentials.json的文件中。
//步骤3:设置FastMCP
FastMCP是一个用于构建MCP服务器的开源Python框架。我遵循了这个教程来使用FastMCP构建我的第一个MCP服务器。
(注意:本教程使用Claude Desktop作为MCP客户端,但步骤适用于Cursor或任何你选择的AI代码编辑器。)
使用FastMCP,你可以创建具有Google集成的MCP服务器(下面是示例代码片段):
@mcp.tool()
def search_team_docs(query: str) -> str:
"""Search team documents in Google Drive"""
drive_service, _ = get_google_services()
# Your search logic here
return f"Searching for: {query}"
//步骤4:配置MCP
一旦你的MCP构建完成,你可以在Cursor中配置它。这可以通过导航到Cursor的设置窗口→功能→模型上下文协议来完成。在这里,你会看到一个可以添加MCP服务器的部分。当你点击它时,一个名为mcp.json的文件将打开,你可以在其中包含新MCP服务器的配置。
这是你的配置应该是什么样的示例:
{
"mcpServers": {
"team-data-assistant": {
"command": "python",
"args": ["path/to/team_data_server.py"],
"env": {
"GOOGLE_APPLICATION_CREDENTIALS": "path/to/credentials.json"
}
}
}
}
在将更改保存到JSON文件后,你可以启用此MCP并在Cursor中开始使用它。
# 最后想法
这个MCP服务器是我决定构建的一个简单的副项目,以节省我个人数据科学工作流程的时间。它并不具有突破性,但这个工具解决了我的直接痛点:花费数小时回答临时数据请求,这些请求会分散我对核心项目的注意力。我相信这样的工具只是触及了生成式AI可能性的表面,并代表了数据科学工作方式的更广泛转变。
传统的数据科学工作流程正在远离:
- 花费数小时寻找数据
- 编写代码
- 构建模型
重点正在从动手的技术工作转移,数据科学家现在被期望关注更大的图景并解决业务问题。在某些情况下,我们被期望监督产品决策并作为产品或项目经理介入。
随着人工智能的不断发展,我相信技术角色之间的界限将会变得模糊。然而,理解业务背景的能力、提出正确问题、解释结果以及传达见解的技能仍然至关重要。如果你是一名数据科学家(或有志成为一名),毫无疑问,人工智能将改变你的工作方式。









