


















Anthropic发布Claude Opus 4.1,在关键编码指标上超越OpenAI的o3

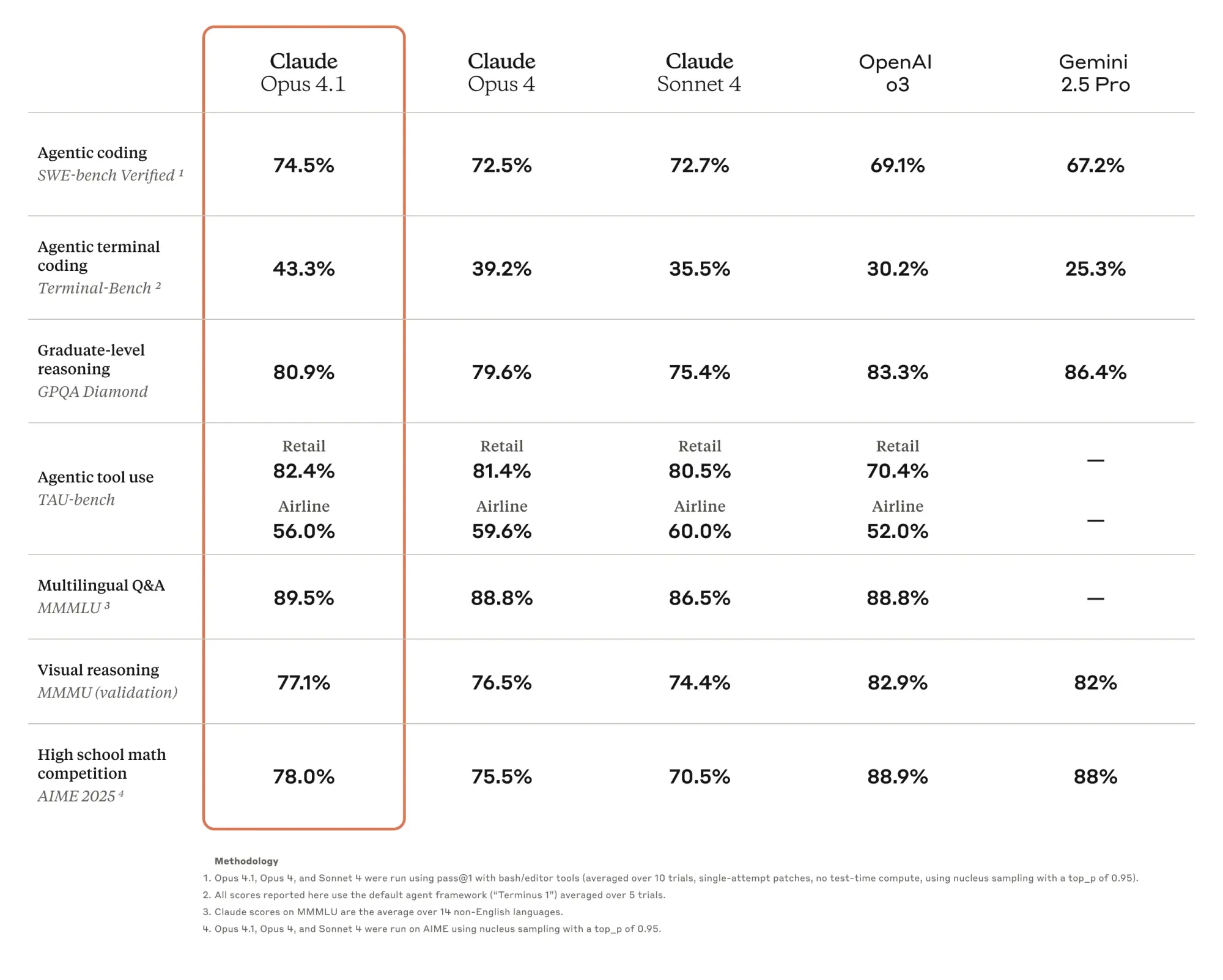
Anthropic今天发布了Claude Opus 4.1,在SWE-bench Verified测试中取得了74.5%的高分,成为解决真实GitHub问题的AI模型中的佼佼者,表现堪比人类工程师。这一成绩略高于OpenAI的o3,自四月发布以来,o3一直以69.1%的得分领先。
关于这些数据的背景:SWE-bench测试AI解决来自GitHub的真实软件问题的能力——模型需要接收一个代码库和问题描述,然后生成一个解决问题的补丁。这些问题不仅是理论上的,而是开发人员每天处理的实际错误和功能请求。
这里的进步令人瞩目。当SWE-bench首次推出时,最好的模型只能解决2%的问题。即使是备受关注的Cognition的AI编码代理Devin,推出时也仅达到13.86%。Claude 3.6 Sonnet达到了50.8%,Gemini 2.0 Flash达到了51.8%,然后o3跃升至69.1%——一个惊人的20%的提升。现在Claude Opus 4.1将这一标准推得更高。
GitHub指出,Claude Opus 4.1在大多数能力上相较于Opus 4有所提升,尤其是在多文件代码重构方面表现显著。这对于实际开发至关重要。乐天集团发现Opus 4.1在大型代码库中能够精准定位确切的修正,而不会做出不必要的调整或引入错误。换句话说,它不仅解决问题,而且解决得非常干净。
GitHub Copilot立即将Claude Opus 4.1添加到他们的模型选择器中,使其对GitHub Copilot Enterprise和Pro+计划用户可用。这是来自最重要的AI编码采用平台的信任投票。
需要注意的是:SWE-bench Verified仅测试Python库,大多数问题相对简单,人类工程师修复这些问题通常需要不到1小时。在旧企业代码库上的体验可能会有所不同。此外,o3在其他基准测试中仍然优于Claude——这绝不是全面胜利。
但对于正在考虑今天使用哪个模型进行实际编码任务的开发人员来说,Claude Opus 4.1提供了一个有力的理由。价格不变,随处可用,并且现在在所有人关注的基准测试中得分最高。
Anthropic表示,他们计划在未来几周内发布大幅改进的模型。鉴于这些排行榜变化如此之快——我们可能不需要等待太久就会看到下一个变化。









