


















AWS在Amazon S3上推出向量功能
在最近于纽约市举行的AWS峰会上,AWS宣布了Amazon S3 Vectors的预览版,声称这是首个支持存储大型向量数据集的云对象存储。新选项提供了亚秒级的查询性能,与传统向量数据库相比,降低了存储AI数据的成本。
S3向量引入了向量桶的概念,这是一种新的桶类型,具有一套专用的API,与现有的S3标准桶不同。S3表。Channy Yun,AWS的首席开发者倡导者,解释道:
通过S3 Vectors,您现在可以经济地存储代表大量非结构化数据(如图像、视频、文档和音频文件)的向量嵌入,从而支持可扩展的生成式AI应用,包括语义和相似性搜索、RAG和构建代理记忆。
一旦创建了S3向量桶,开发者可以在向量索引中组织向量数据,并对数据集运行相似性搜索查询。根据文档,每个向量桶最多可以有10,000个向量索引,每个向量索引可以容纳数千万个向量。
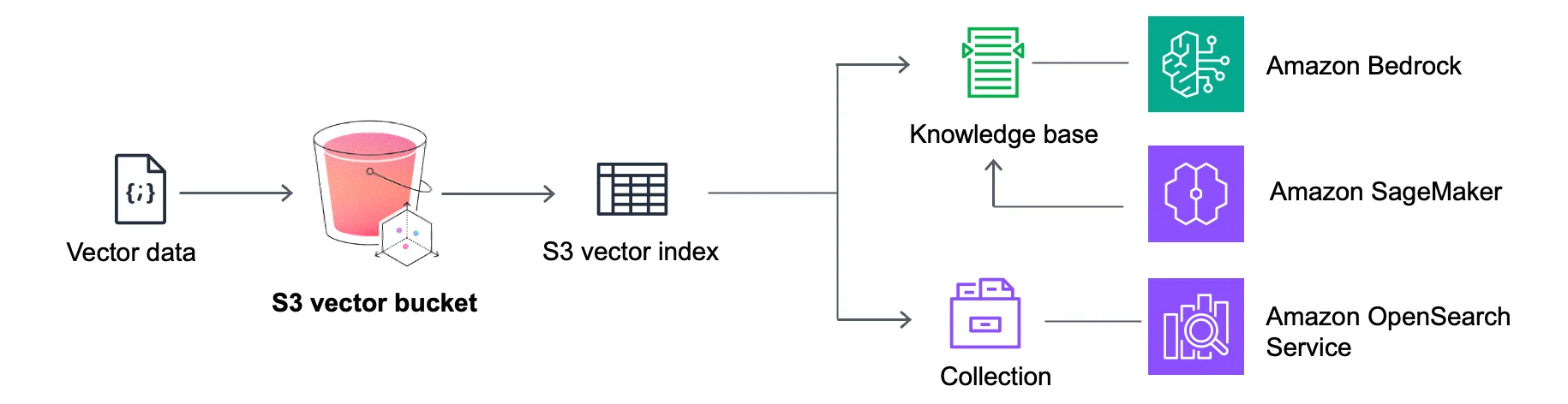
开发者可以将元数据作为键值对附加到向量上,默认情况下所有元数据都是可过滤的,向量索引支持字符串、数字、布尔和列表类型。
作为一个独立的解决方案,S3 Vectors专为查询不频繁的工作负载而设计。为了在AWS上构建RAG应用,S3 Vectors与Bedrock知识库和OpenSearch集成。Yun补充道:
通过与Amazon OpenSearch Service的集成,您可以通过将不常查询的向量保存在S3 Vectors中来降低存储成本,然后在需求增加时快速将它们移动到OpenSearch,以支持实时、低延迟的搜索操作。
Andrew Warfield,亚马逊的副总裁兼杰出工程师,在LinkedIn上澄清了目标:
对于S3团队来说,这是一个激动人心的时刻,因为我们正在积极观察S3上的工作负载变化。S3 Vectors的成本远低于传统的向量存储。至少目前,它没有提供DRAM存储中常见的高TPS和低延迟水平。我们的理由是,就像其他数据类型一样,构建者会欣赏一个高度耐用且低成本的向量基础层,并乐于在必要时将数据移到更高性能和功能更丰富的层。
为了简化在S3 Vectors中处理向量嵌入的过程,云提供商发布了S3 Vectors Embed CLI库,这是一个独立的命令行工具,用于在S3上创建、存储和查询向量嵌入。还提供了一个使用Python SDK的教程“S3 Vectors入门”。
在一个热门的Reddit帖子中,大多数开发者对这一新功能表示赞赏,Travis Cunningham写道:
这一举措将每个S3桶变成了一个迷你向量存储,增加了亚马逊已经摊销的硬件的利润,并关闭了试图分流AI工作负载的竞争对手的大门。
在Hacker News上,用户bob1029则评论道:
我仍然认为大多数人想要的是传统的全文搜索,而不是在LLM后面再加一层黑箱怪异。您已经有一个具有强大语义理解的模型。为什么我们还需要文档存储也变得聪明?模型可以根据其对上下文的理解,将多个OR子句投射到搜索词中。
在另一项公告中,Amazon S3元数据为桶中的所有对象引入了实时库存表。一个托管的Apache Iceberg表提供了桶中对象及其元数据的完整和当前快照,包括现有对象。
泄露在会议前几天意外泄露,S3 Vectors目前在包括北弗吉尼亚、俄亥俄和欧洲法兰克福在内的部分地区预览。









