


















谷歌推出设备端Gemini机器人模型

谷歌DeepMind的视觉-语言-动作引擎首次实现了真正的便携版本,现在可以完全在机器人本身上运行。这为即使在Wi-Fi断开时也能继续工作的仓库机器人和工厂协作机器人开辟了新的可能性。
关键点
- 可以完全离线运行,性能几乎与云端Gemini模型相当。
- 只需50到100次演示即可微调以适应新任务或不同的机器人机体。
- Gemini机器人SDK现已面向开发者推出,但最初的访问权限通过“受信任测试者”计划进行。
- 这是与Nvidia的GR00T和OpenAI的RT-2在通用机器人大脑领域展开的更广泛竞争的一部分。
谷歌DeepMind的新Gemini机器人设备端模型是一个小型而强大的装置。公司表示,它保留了与三月推出的混合云版本“几乎”相同的能力,但足够精简,可以完全在机器人的车载计算机上运行。在内部测试中,运行该模型的机器人能够拉拉链、折叠衬衫和分类从未见过的零件——这一切都无需向云端发送任何数据。
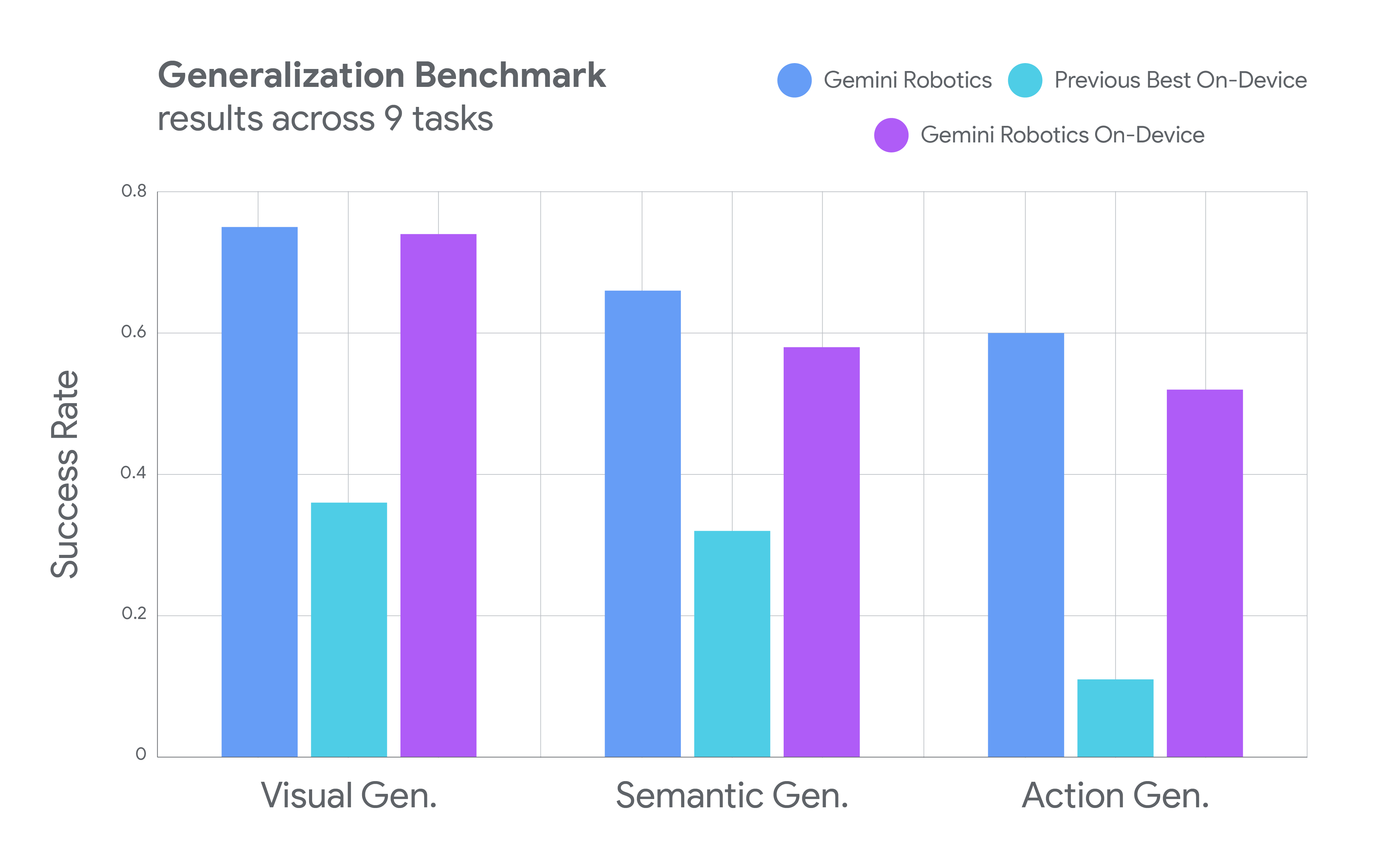
这对谷歌来说是一个重大转变,谷歌一直通过其RT-1和RT-2模型推动云连接机器人。但这个新的“Gemini机器人设备端”模型承认了任何曾经处理过不稳定WiFi的人都知道的事实:有时候你不能依赖互联网。
这不仅仅是为了方便。当机器人需要做出瞬间决策时——比如抓住掉落的物体或绕过突然出现的障碍物——每毫秒都至关重要。将视觉数据发送到云端、处理并返回指令会引入延迟,这可能会使有用的机器人变成潜在的风险。
谷歌的解决方案基于公司称之为视觉-语言-动作(VLA)模型的基础——这些AI系统可以观察环境,理解自然语言命令,并将两者转化为物理动作。可以将其视为一个更复杂的版本,类似于让Alexa开灯,但机器人实际上可以在现实世界中抓取、操控和移动物体。
设备端模型继承了谷歌旗舰云端Gemini机器人的灵活性,但将其压缩到可以在机器人的本地硬件上运行。在测试中,它执行了复杂的操作任务,如折纸和准备沙拉——这些任务在历史上一直被视为机器人技术的难题,因为它们需要精确和多步骤的操作。
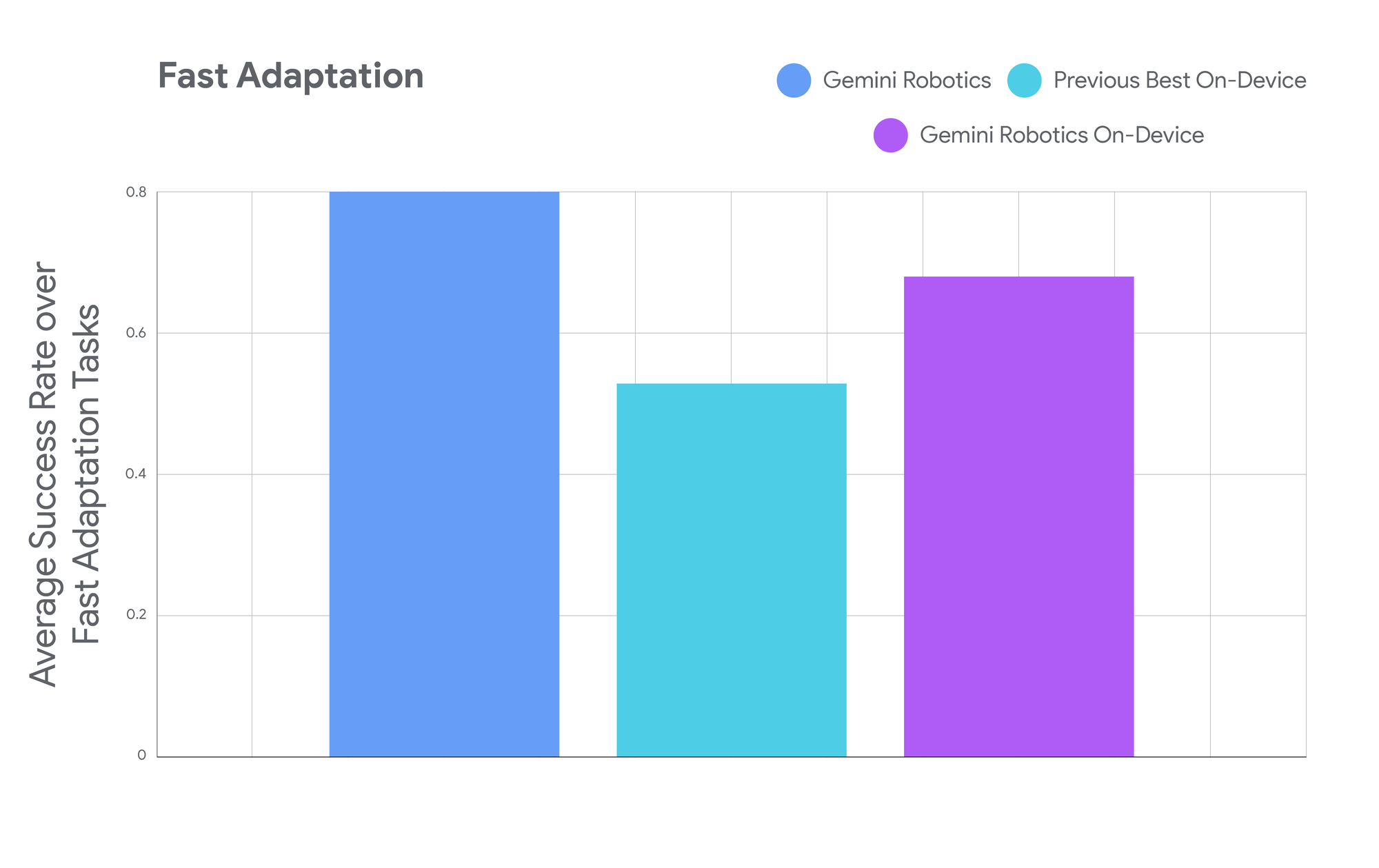
谷歌表示,该模型可以通过少至50次演示学习新任务,甚至可以将其知识转移到完全不同的机器人机体上。公司展示了同一AI控制学术ALOHA机器人和Apptronik的商业人形机器人,表明了一种可能加速机器人部署的泛化水平。
但这种本地优先的方法也有其权衡。设备端处理意味着与谷歌庞大的云基础设施相比,计算能力更有限。虽然机器人可以“开箱即用”地处理广泛的任务,但最苛刻的应用可能仍然需要完整的云端Gemini机器人模型。
随着机器人公司竞相部署从仓库自动化到家庭助手的各种应用,连接性已成为一个关键瓶颈。特斯拉的Optimus机器人、波士顿动力的Atlas以及像Physical Intelligence这样的初创公司都在努力解决同一个基本问题:机器人上应该有多少智能,而云端又应该有多少?
谷歌对本地处理的押注也解决了日益增长的隐私问题。当你的机器人可以看到你的家、了解你的日常习惯并记住你的偏好时,将这些数据保存在本地不仅仅是一个技术考虑——这也是一个信任问题。
公司通过一个受信任测试者计划推出这项技术,并提供一个Gemini机器人SDK,允许开发者为其特定用例微调模型。这是一个谨慎、受控的发布,表明谷歌从有时混乱的消费者AI产品发布中吸取了教训。
这是否代表了机器人技术的未来或只是众多方法中的一种还有待观察。但谷歌将强大的AI能力直接带到机器人上——无需互联网连接——可能会加速在连接性无法保证的环境中部署有用机器人的进程。在一个甚至我们的汽车都变得更智能的世界中,这可能正是机器人技术需要的,才能最终走出实验室。









