


















Vectara推出幻觉校正器以提升企业AI的可靠性

人工智能代理和助手平台的提供商Vectara公司今天宣布推出一款新的幻觉校正器,直接集成到其服务中,旨在检测和缓解企业AI模型产生的代价高昂且不可靠的响应。
幻觉是指生成式AI大型语言模型自信地提供错误信息,这一直困扰着行业。对于传统模型,据估计它们的发生率为大约3%到10%的查询平均而言,具体取决于模型。
最近推理AI模型的出现,这些模型通过分步骤解决复杂问题来“思考”它们,导致幻觉率显著增加。
根据Vectara的一份报告,推理模型DeepSeek-R1的幻觉率显著高于其前身DeepSeek R3的3.9%,达到14.3%。同样,OpenAI的GPT-o1也是一个推理模型,其幻觉率从GPT-4o的1.5%跃升至2.4%。《新科学家》 发表了一份类似的报告发现相同和其他推理模型的幻觉率甚至更高。
“虽然大型语言模型最近在解决幻觉问题上取得了显著进展,但它们仍然远未达到金融服务、医疗保健、法律等高度监管行业所需的准确性标准,”Vectara创始人兼首席执行官Amr Awadallah说。
在初步测试中,Vectara表示幻觉校正器将企业AI系统中的幻觉率降低到约0.9%。
它与公司已经广泛使用的Hughes幻觉评估模型一起工作,该模型提供了一种在运行时比较响应与源文档并识别陈述是否准确的方法。HHEM根据源文档对答案进行评分,概率分数在1到0之间,其中0表示完全不准确——完全幻觉,1表示完全准确。例如,0.98表示答案有98%的可能性是高度准确的。HHEM在
Hugging Face上可用上个月下载量超过25万次,使其成为平台上最受欢迎的幻觉检测器之一。
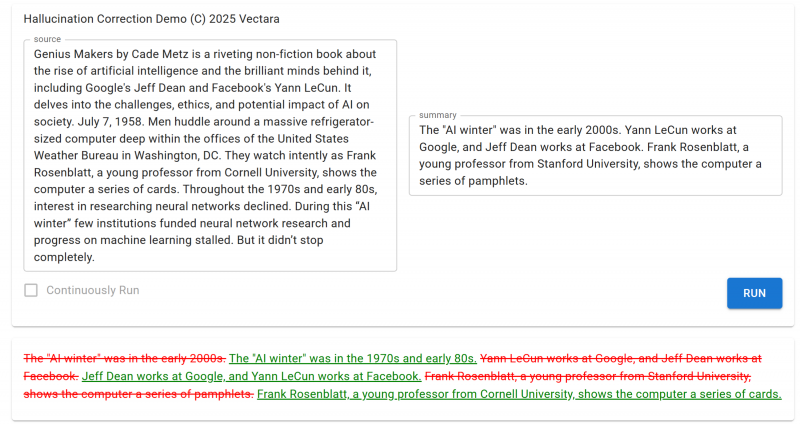
在事实不一致的响应情况下,校正器提供详细的输出,包括为什么陈述是幻觉的解释和一个包含最小更改的准确版本。
公司表示,它会自动在最终用户的摘要中使用校正后的输出,但专家可以使用完整的解释和建议的修正来测试应用程序,以改进或微调他们的模型和防护措施以对抗幻觉。它还可以显示原始摘要,但使用校正信息标记潜在用途,同时提供校正后的摘要作为可选修正。
对于属于误导但不完全错误的LLM答案,幻觉校正器可以根据客户的设置来优化响应以减少其不确定性核心。









