


















阿里巴巴推出了Qwen3,这是一系列大型语言模型(LLM),公司称其为通向通用人工智能(AGI)和超级人工智能(ASI)之路的重要里程碑。这些模型引入了混合推理,支持超过100种语言,标志着多语言AI的重大进步。
该系列包括八个模型,均作为开源全球发布。通过在“思考”和“非思考”模式之间的动态切换,Qwen3有望与当今表现最好的AI系统竞争。
深入了解Qwen3
Qwen3模型旨在推进混合推理、多语言支持和代理能力。该系列包括六个密集模型和两个专家混合(MoE)模型,参数范围从0.6亿到2350亿。除了令人印象深刻的规模外,Qwen3的核心特征是什么?
混合推理和模式切换
Qwen3使用双模式系统,允许用户在复杂推理和代码任务的“思考模式”与快速响应和一般对话的“非思考模式”之间切换。这种灵活性使用户能够根据任务优化深度或速度,确保计算资源的高效使用。
高级代理能力
这些AI模型展示了先进的代理能力,在思考和非思考模式下无缝集成外部工具。Qwen3能够精确执行复杂的工具增强任务,确立其作为代理应用中最强大的开源模型之一的地位。
广泛的多语言支持
Qwen3支持119种语言和方言,旨在实现全球可访问性。其强大的多语言能力使其能够在各种语言环境中进行高质量的指令跟随和翻译。
顶级基准测试表现
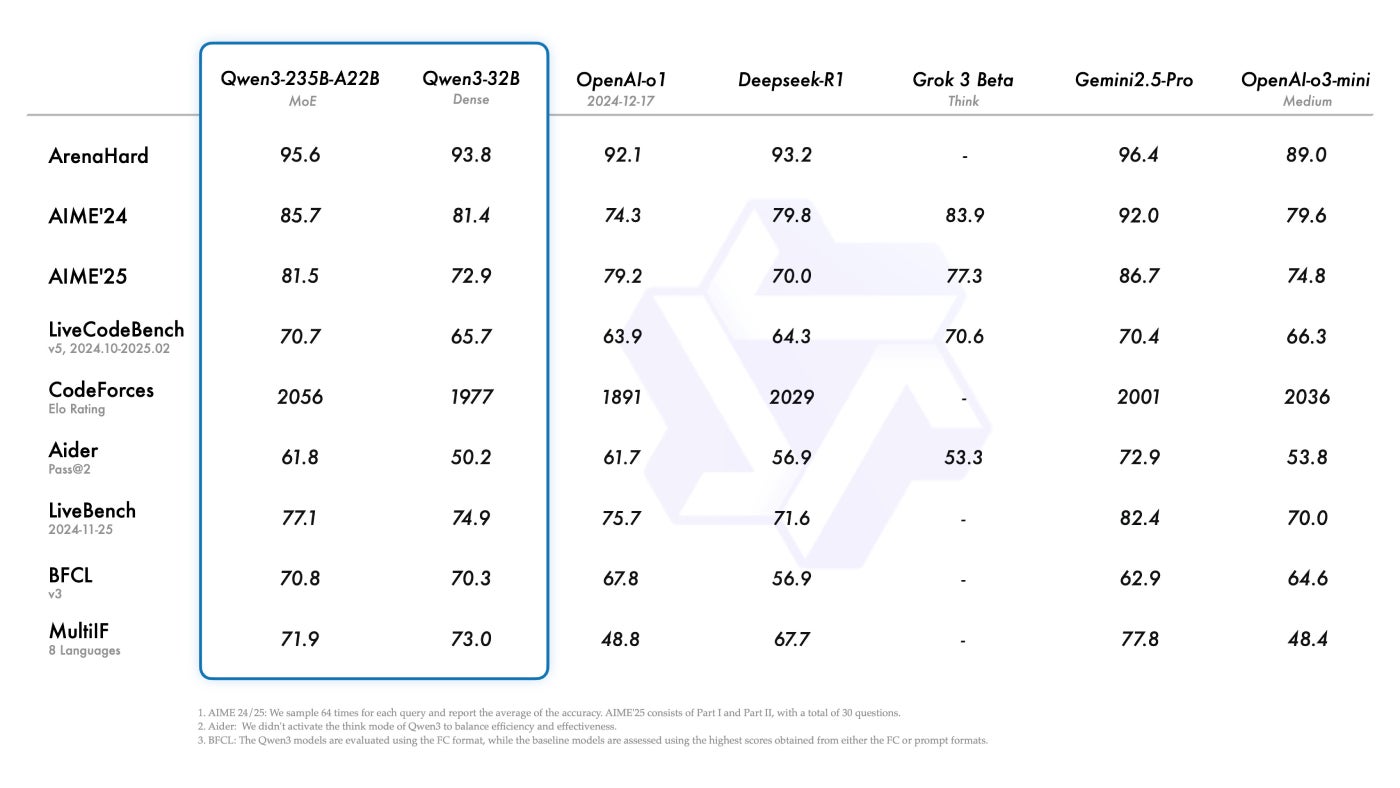
旗舰产品Qwen3-235B-A22B在行业基准测试中表现出色,在编码、数学和一般推理方面优于OpenAI的o1和DeepSeek的-R1。它还在Codeforces等平台上超越了OpenAI的o3-mini和谷歌的Gemini 2.5 Pro。
庞大而多样的训练数据
在超过36万亿个标记上进行训练——包括教科书、问答对、代码和合成数据——Qwen3庞大的训练集支撑了其强大的推理和指令跟随性能。
开源可访问性
所有Qwen3模型均在Apache 2.0许可证下发布,可在Hugging Face、ModelScope、Kaggle和GitHub上免费使用和集成。这鼓励了广泛的采用和社区驱动的发展。
扩展的上下文处理
Qwen3-8B是该系列的一个模型,拥有82亿个参数,分布在36层。它可以一次处理多达32,768个输入标记,使其能够管理需要广泛上下文的任务,如文档摘要或多步骤对话。
Qwen3开启了可访问AI创新的新时代
Qwen3的高级功能,如混合推理、MoE架构和广泛的多语言支持,加上其成本效益的可扩展性,为用户和企业带来了新的可能性。公司现在可以部署根据其需求和预算量身定制的强大AI模型,而用户可以受益于更智能、更具上下文感知的工具和服务。
随着阿里巴巴追求AGI作为其核心使命,Qwen3是这一雄心的有力证明。它代表了可访问、高性能AI的新标准,能够改变行业。









