











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌的RT-2人工智能模型:迈向类似WALL-E的机器人的一步
2023年07月31日 由 daydream 发表
658517
0
周五,谷歌DeepMind宣布推出了Robotic Transformer 2(RT-2),这是一种“首次问世”的视觉-语言-动作(VLA)模型,利用从互联网上获取的数据,通过简单的语言命令实现更好的机器人控制。最终目标是创建可以在人类环境中导航的通用机器人,类似于WALL-E或C-3PO等虚构机器人。

当一个人想要学习一项任务时,我们经常阅读和观察。以类似的方式,RT-2利用了一个大型语言模型(ChatGPT背后的技术),该模型已经在网上找到的文本和图像上进行了训练。RT-2使用这些信息来识别模式并执行动作,即使机器人没有经过专门的训练来完成这些任务 - 这个概念称为泛化。
例如,谷歌表示RT-2可以使机器人在没有特别训练的情况下识别并清理垃圾。它利用对垃圾及其常见处理方式的理解来引导其行动。RT-2甚至会将废弃的食品包装或香蕉皮视为垃圾。

在另一个例子中,《纽约时报》讲述了一位谷歌工程师下达命令,“捡起灭绝的动物”,RT-2机器人从桌子上的三个小雕像中定位并挑选出一只恐龙。
这种能力是值得注意的,因为机器人通常是从大量手动获取的数据点训练的,由于覆盖每个可能场景的时间和成本很高,这使得这个过程变得困难。简而言之,现实世界是一个动态的混乱,充满了不断变化的情境和物体配置。一个实用的机器人助手需要能够以不可能明确编程的方式即时适应,这就是RT-2的用武之地。
超乎想象
通过RT-2,谷歌DeepMind采用了一种策略,利用了变压器AI模型的优势,这些模型以其概括信息的能力而闻名。RT-2借鉴了谷歌早期的人工智能工作,包括Pathways Language and Image模型(PaLI-X)和Pathways Language Model Embodied (PaLM-E)。此外,RT-2还在其前身模型(RT-1)的数据上进行了共同训练,这些数据是由13个机器人在“办公室厨房环境”中收集的,历时17个月。
RT-2架构涉及对基于机器人和网络数据的预训练VLM模型进行微调。生成的模型处理机器人相机图像并预测机器人应该执行的动作。
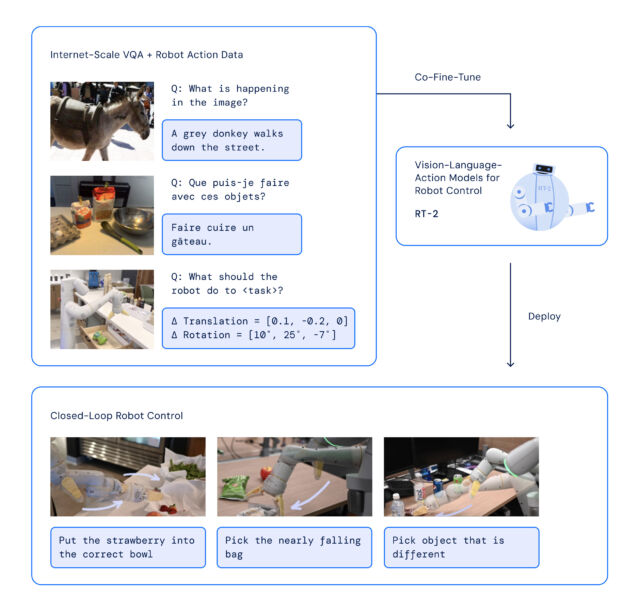
由于RT-2使用语言模型来处理信息,谷歌选择将动作表示为标记,这通常是一个词的片段。谷歌写道:"为了控制机器人,必须训练它输出动作。我们通过将动作表示为模型输出中的标记(类似于语言标记)来解决这个挑战,并将动作描述为可以通过常规自然语言分词器处理的字符串。"
在开发RT-2时,研究人员采用了与机器人首个版本RT-1相同的方法,将机器人动作分解为较小的部分。他们发现,通过将这些动作转化为一系列符号或代码(即"字符串"表示),他们可以使用与处理网络数据相同的学习模型教给机器人新的技能。
该模型还利用了思维链推理,使其能够进行多阶段推理,例如选择一个替代工具(例如把石头当作临时的锤子)或为疲劳的人选择最佳饮料(例如能量饮料)。

谷歌表示,在6000多次试验中,RT-2在其经过训练的任务(称为“已知”任务)上表现与其前身RT-1相当。然而,在新的“未知”场景中进行测试时,RT-2的性能几乎提升了一倍,达到了62%,而RT-1只有32%。
虽然RT-2展现出了将已学到的知识应用于新情境的巨大能力,但谷歌承认它并不完美。在RT-2技术论文的"局限性"部分,研究人员承认,尽管在训练材料中包含网络数据"提升了关于语义和视觉概念的泛化能力",但它并没有神奇地赋予机器人执行物理运动的新能力,而这些能力还没有从其前身的机器人训练数据中学到。换句话说,它不能执行以前没有实际练习过的动作,但它会更好地以新的方式使用它已经知道的动作。
虽然谷歌DeepMind的最终目标是创造通用机器人,但该公司知道,在实现这一目标之前,还有很多研究工作要做。但像RT-2这样的技术似乎是朝着这个方向迈出的坚实一步。
来源:https://arstechnica.com/information-technology/2023/07/googles-rt-2-ai-model-brings-us-one-step-closer-to-wall-e/
当一个人想要学习一项任务时,我们经常阅读和观察。以类似的方式,RT-2利用了一个大型语言模型(ChatGPT背后的技术),该模型已经在网上找到的文本和图像上进行了训练。RT-2使用这些信息来识别模式并执行动作,即使机器人没有经过专门的训练来完成这些任务 - 这个概念称为泛化。
例如,谷歌表示RT-2可以使机器人在没有特别训练的情况下识别并清理垃圾。它利用对垃圾及其常见处理方式的理解来引导其行动。RT-2甚至会将废弃的食品包装或香蕉皮视为垃圾。
在另一个例子中,《纽约时报》讲述了一位谷歌工程师下达命令,“捡起灭绝的动物”,RT-2机器人从桌子上的三个小雕像中定位并挑选出一只恐龙。
这种能力是值得注意的,因为机器人通常是从大量手动获取的数据点训练的,由于覆盖每个可能场景的时间和成本很高,这使得这个过程变得困难。简而言之,现实世界是一个动态的混乱,充满了不断变化的情境和物体配置。一个实用的机器人助手需要能够以不可能明确编程的方式即时适应,这就是RT-2的用武之地。
超乎想象
通过RT-2,谷歌DeepMind采用了一种策略,利用了变压器AI模型的优势,这些模型以其概括信息的能力而闻名。RT-2借鉴了谷歌早期的人工智能工作,包括Pathways Language and Image模型(PaLI-X)和Pathways Language Model Embodied (PaLM-E)。此外,RT-2还在其前身模型(RT-1)的数据上进行了共同训练,这些数据是由13个机器人在“办公室厨房环境”中收集的,历时17个月。
RT-2架构涉及对基于机器人和网络数据的预训练VLM模型进行微调。生成的模型处理机器人相机图像并预测机器人应该执行的动作。
由于RT-2使用语言模型来处理信息,谷歌选择将动作表示为标记,这通常是一个词的片段。谷歌写道:"为了控制机器人,必须训练它输出动作。我们通过将动作表示为模型输出中的标记(类似于语言标记)来解决这个挑战,并将动作描述为可以通过常规自然语言分词器处理的字符串。"
在开发RT-2时,研究人员采用了与机器人首个版本RT-1相同的方法,将机器人动作分解为较小的部分。他们发现,通过将这些动作转化为一系列符号或代码(即"字符串"表示),他们可以使用与处理网络数据相同的学习模型教给机器人新的技能。
该模型还利用了思维链推理,使其能够进行多阶段推理,例如选择一个替代工具(例如把石头当作临时的锤子)或为疲劳的人选择最佳饮料(例如能量饮料)。
谷歌表示,在6000多次试验中,RT-2在其经过训练的任务(称为“已知”任务)上表现与其前身RT-1相当。然而,在新的“未知”场景中进行测试时,RT-2的性能几乎提升了一倍,达到了62%,而RT-1只有32%。
虽然RT-2展现出了将已学到的知识应用于新情境的巨大能力,但谷歌承认它并不完美。在RT-2技术论文的"局限性"部分,研究人员承认,尽管在训练材料中包含网络数据"提升了关于语义和视觉概念的泛化能力",但它并没有神奇地赋予机器人执行物理运动的新能力,而这些能力还没有从其前身的机器人训练数据中学到。换句话说,它不能执行以前没有实际练习过的动作,但它会更好地以新的方式使用它已经知道的动作。
虽然谷歌DeepMind的最终目标是创造通用机器人,但该公司知道,在实现这一目标之前,还有很多研究工作要做。但像RT-2这样的技术似乎是朝着这个方向迈出的坚实一步。
来源:https://arstechnica.com/information-technology/2023/07/googles-rt-2-ai-model-brings-us-one-step-closer-to-wall-e/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消