











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Google发布了Hive-BigQuery开源连接器
2023年07月24日 由 Samoyed 发表
974298
0
Google最近宣布全面推出 Hive-BigQuery 连接器,它简化了Apache Hive和Google BigQuery之间的集成和迁移。开源连接器是一个Hive存储处理程序,它使Hive能够与BigQuery的存储层进行交互。

新选项支持在Hive中使用类SQL查询语言HiveQL对BigQuery进行读写。数据工程师可以在不移动数据的情况下访问和查询BigQuery数据集,BigQuery用户可以利用Hive的工具、库和框架进行数据处理和分析。Google Cloud的解决方案架构师Julien Phalip写道:
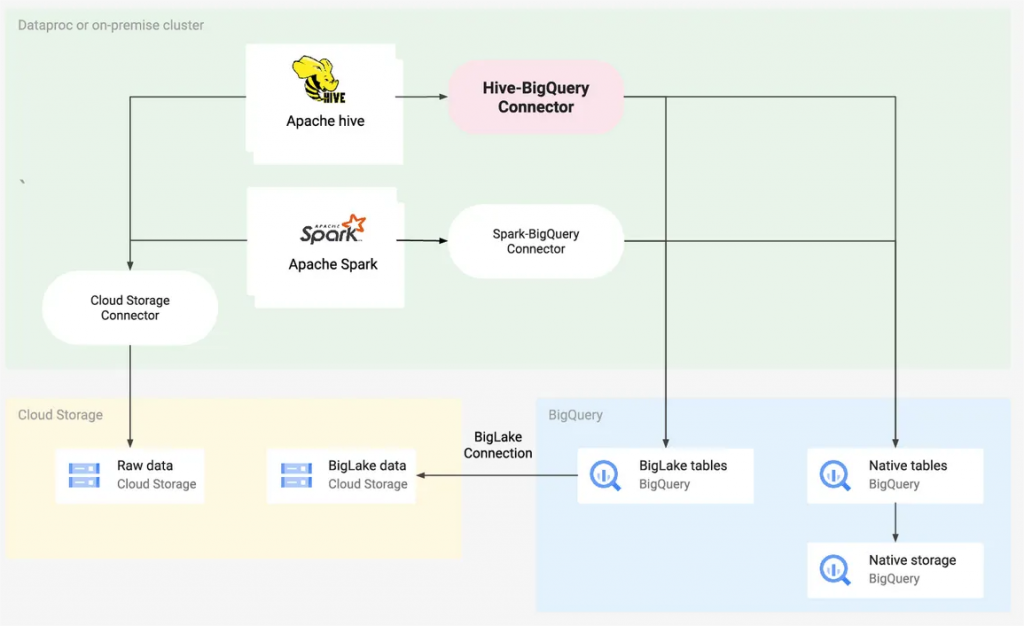
Apache Hive是一个流行的建立在Hadoop之上的分布式数据仓库选项,它允许用户对大型数据集进行查询。BigQuery是Google Cloud上的无服务器数据仓库,提供对海量数据集的可扩展查询。开源连接器使用 Hive 的元数据表示存储在 BigQuery 中的表,从而确保了数据的一致性和可靠性。
连接器支持使用MapReduce和Tez执行引擎进行查询,在Hive中创建和删除BigQuery表,以及将BigQuery和BigLake表与Hive表连接。它还支持使用Storage Read API流和Apache Arrow格式从BigQuery表中快速读取数据。
据云服务提供商称,Hive-BigQuery连接器可以在以下场景中帮助公司:确保迁移过程中的操作连续性,将BigQuery用于数据仓库需求的子集,或者维护完整的开源软件堆栈。
通过BigQuery迁移服务,Google已经支持BigQuery批处理SQL转换和交互式SQL转换,将Hive查询转换为BigQuery自己的ANSI兼容SQL语法。Phalip解释道:
这并不是Google发布的第一个减少数据转换、可以分析不同的数据集的开源连接器:Cloud Storage连接器实现了Hadoop兼容文件系统(HCFS) API来存储和访问云存储中的数据文件,而BigQuery的Apache Spark SQL连接器实现了Spark SQL数据源API,将BigQuery表读取到Spark的数据框架中,并将数据框架写回BigQuery。
Hive-BigQuery连接器支持Dataproc 2.0和2.1。Google概述了关于分区的一些限制,由于Hive和BigQuery的分区方式不同,所以不支持Hive PARTITIONED BY子句。但是,开发人员仍然可以使用BigQuery支持的时间单位列和摄取时间分区选项。
来源:https://www.infoq.com/news/2023/07/google-hive-bigquery-connector/?topicPageSponsorship=be5ab845-3650-4ca6-b998-6e258cb0cba1&itm_source=presentations_about_ai-ml-data-eng&itm_medium=link&itm_campaign=ai-ml-data-eng
新选项支持在Hive中使用类SQL查询语言HiveQL对BigQuery进行读写。数据工程师可以在不移动数据的情况下访问和查询BigQuery数据集,BigQuery用户可以利用Hive的工具、库和框架进行数据处理和分析。Google Cloud的解决方案架构师Julien Phalip写道:
“Hive-BigQuery连接器实现了Hive StorageHandler API,允许Hive工作负载与BigQuery和BigLake表集成。虽然Hive的执行引擎仍然处理所有的计算操作,如聚合和连接,但连接器管理BigQuery数据层的所有交互,无论是存储在BigQuery本地还是通过BigLake连接存储在云端的底层数据。”
Apache Hive是一个流行的建立在Hadoop之上的分布式数据仓库选项,它允许用户对大型数据集进行查询。BigQuery是Google Cloud上的无服务器数据仓库,提供对海量数据集的可扩展查询。开源连接器使用 Hive 的元数据表示存储在 BigQuery 中的表,从而确保了数据的一致性和可靠性。
连接器支持使用MapReduce和Tez执行引擎进行查询,在Hive中创建和删除BigQuery表,以及将BigQuery和BigLake表与Hive表连接。它还支持使用Storage Read API流和Apache Arrow格式从BigQuery表中快速读取数据。
据云服务提供商称,Hive-BigQuery连接器可以在以下场景中帮助公司:确保迁移过程中的操作连续性,将BigQuery用于数据仓库需求的子集,或者维护完整的开源软件堆栈。
通过BigQuery迁移服务,Google已经支持BigQuery批处理SQL转换和交互式SQL转换,将Hive查询转换为BigQuery自己的ANSI兼容SQL语法。Phalip解释道:
“新的Hive-BigQuery连接器提供了一个额外的选择:您可以保留原来的HiveQL查询语言,继续在集群上使用Hive执行引擎运行这些查询,但让这些查询可以访问迁移到BigQuery和BigLake表的数据。”
这并不是Google发布的第一个减少数据转换、可以分析不同的数据集的开源连接器:Cloud Storage连接器实现了Hadoop兼容文件系统(HCFS) API来存储和访问云存储中的数据文件,而BigQuery的Apache Spark SQL连接器实现了Spark SQL数据源API,将BigQuery表读取到Spark的数据框架中,并将数据框架写回BigQuery。
Hive-BigQuery连接器支持Dataproc 2.0和2.1。Google概述了关于分区的一些限制,由于Hive和BigQuery的分区方式不同,所以不支持Hive PARTITIONED BY子句。但是,开发人员仍然可以使用BigQuery支持的时间单位列和摄取时间分区选项。
来源:https://www.infoq.com/news/2023/07/google-hive-bigquery-connector/?topicPageSponsorship=be5ab845-3650-4ca6-b998-6e258cb0cba1&itm_source=presentations_about_ai-ml-data-eng&itm_medium=link&itm_campaign=ai-ml-data-eng

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消