











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






提高机器学习效率:GPU加速的Pandas和Scikit-learn助力数据分析
2023年07月12日 由 Alex 发表
653615
0
介绍
如果您希望将机器学习(ML)项目的速度和可扩展性提升到新的水平,GPU加速的数据分析可以帮助您以突破性的性能快速提供见解。从更快的计算到高效的模型训练,GPU为日常的机器学习任务带来了许多好处。
使用GPU加速数据科学管道
GPU加速的数据分析可以通过GPU DataFrame库RAPIDS cuDF和GPU加速的ML库RAPIDS cuML来实现。
cuDF是一个基于Apache Arrow列式内存格式的Python GPU DataFrame库,用于加载、连接、聚合、过滤和操作数据。它有一个类似于pandas的API, pandas是一个建立在Python之上的开源软件库,专门用于数据操作和分析。这使得它成为数据分析工作流的有用工具,包括数据预处理和为ML准备数据框架的探索性任务。
数据经过预处理后,cuDF就会与cuML无缝集成,后者利用GPU加速提供大量ML算法,可以帮助大规模执行复杂的ML任务,比scikit-learn等基于CPU的框架快得多。
cuML提供了一个直接的API,与scikit-learn API非常相似,使其易于集成到现有的ML项目中。借助cuDF和cuML,从事ML项目的数据科学家和数据分析师可以轻松地使用最流行的开源数据科学工具,并利用GPU在数据管道中的加速功能进行交互。这将最大限度地减少采用时间,从而推动ML工作流向前发展。
了解Meteonet数据集
在深入分析之前,了解Meteonet数据集的结构和内容非常重要,它非常适合时间序列分析。该数据集是一个全面的天气数据集合,对气象研究人员和数据科学家非常有益。
Meteonet数据集的概述和每一列的含义如下:
1. number_sta:每个气象站的唯一标识符。
2. lat和lon:气象站的经纬度,代表气象站的地理位置。
3. height_sta:气象站海拔高度,单位为米。
4. data:记录数据的日期和时间,对时间序列分析至关重要。
5. dd:以度为单位的风向,表示风从哪个方向来。
6. ff:风速,单位为米/秒。
7. precip:以毫米计的降水量。
8. hu:湿度,用百分数表示,表示空气中水蒸气的浓度。
9. td:露点温度,以摄氏度为单位,表示空气中水分饱和的时间。
10. t:空气温度,单位是摄氏度。
11. psl:海平面气压,单位hPa(百帕斯卡)。
使用RAPIDS进行机器学习
本文将介绍使用cuDF和cuML加速三种基本ML算法:回归、分类和聚类。
安装
在分析Meteonet数据集之前,安装并设置RAPIDS cuDF和cuML。
分类
分类是一种ML算法,用于根据一组特征预测分类值。在这种情况下,目标是使用温度、湿度和其他因素来预测天气状况(如晴天、多云或雨天)和风向。
随机森林是一种强大而通用的ML方法,能够执行回归和分类任务。本节使用cuML随机森林分类器对某一时间和地点的天气状况和风向进行分类。模型的精度可以用来评价其性能。
在本文中,西北站3年的数据被合并到一个名为NW_data.csv的数据框中。
import cudf, cuml
from cuml.ensemble import RandomForestClassifier as cuRF
# Load data
df = cudf.read_csv('./NW_data.csv').dropna()
要为分类准备数据,需要执行预处理任务,例如将日期列转换为datetime格式并提取小时。
# Convert date column to datetime and extract hour
df['date'] = cudf.to_datetime(df['date'])
df['hour'] = df['date'].dt.hour
# Drop the original 'date' column
df = df.drop(['date'], axis=1)
创建两个新的分类列:wind_direction和weather_condition。
对于wind_direction,将dd列(假设以度为单位的风向)离散为四类::北(0-90度)、东(90-180度)、南(180-270度)和西(270-360度)。
# Discretize wind direction
df['wind_direction'] = cudf.cut(df['dd'], bins=[-0.1, 90, 180, 270, 360], labels=['N', 'E', 'S', 'W'])
对于weather_condition,将precip列(即降水量)离散为三类:晴天(无雨)、多云(少雨)和雨天(多雨)。
# Discretize weather condition based on precipitation amount
df['weather_condition'] = cudf.cut(df['precip'], bins=[-0.1, 0.1, 1, float('inf')], labels=['sunny', 'cloudy', 'rainy'])
然后将这些分类列转换为RandomForestClassifier可以使用.cat.codes处理的数字标签。
# Convert 'wind_direction' and 'weather_condition' columns to category
df['wind_direction'] = df['wind_direction'].astype('category').cat.codes
df['weather_condition'] = df['weather_condition'].astype('category').cat.codes
模型训练
现在预处理已经完成,下一步是定义一个函数来预测风向和天气状况:
def train_and_evaluate(target):
# Split into features and target
X = df.drop(target, axis=1)
y = df[target]
# Split the dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define the model
model = cuRF()
# Train the model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy for predicting {target} is {accuracy}")
return model
现在函数已经准备好了,下一步是使用下面的调用来训练模型,并提到目标变量:
# Train and evaluate models
weather_condition_model = train_and_evaluate('weather_condition')
wind_direction_model = train_and_evaluate('wind_direction')
本文使用cuML随机森林分类器对西北数据集中的天气条件和风向进行分类。预处理步骤包括转换日期列、离散风向和天气条件以及将分类列转换为数字标签。对模型进行训练和评估,以准确性作为评估指标。
回归
回归是一种ML算法,用于根据一组特征预测连续值。例如,您可以根据房屋的特征(如卧室数量、平方英尺和位置)使用回归来预测房屋的价格。
线性回归是预测定量响应的常用算法。使用线性回归的cuML实现来预测不同时间和地点的温度、湿度和降水。R^2分数可以用来评估你的回归模型的性能。
首先导入所需的库:
from cuml import make_regression, train_test_split
from cuml.linear_model import LinearRegression as cuLinearRegression
from cuml.metrics.regression import r2_score
from cuml.preprocessing.LabelEncoder import LabelEncoder
接下来,通过将NW_data.csv文件读入一个数据帧并删除任何缺失值的行来加载NW数据集:
# Load data
df = cudf.read_csv('/NW_data.csv').dropna()
对于许多ML算法,必须将分类输入数据转换为数字形式。对于本例,number_sta(表示“站点编号”)使用LabelEncoder进行转换,LabelEncoder为每个类别分配唯一的数值。
其次,数值特征必须归一化,以防止模型受到变量尺度的偏差。
然后将“日期”一栏转换为“小时”特征,因为天气模式通常与一天中的时间相关。最后,删除' date '列,因为所使用的模型不能直接处理该列。
# Convert categorical variables to numeric variables
le = LabelEncoder()
df['number_sta'] = le.fit_transform(df['number_sta'])
# Normalize numeric features
numeric_columns = ['lat', 'lon', 'height_sta', 'dd', 'ff', 'hu', 'td', 't', 'psl']
for col in numeric_columns:
if df[col].dtype != 'object':
df[col] = (df[col] - df[col].mean()) / df[col].std()
else:
print(f"Skipping normalization for non-numeric column: {col}")
# Convert date column to datetime and extract hour
df['date'] = cudf.to_datetime(df['date'])
df['hour'] = df['date'].dt.hour
# Drop the original 'date' column
df = df.drop(['date'], axis=1)
模特训练与表现
预处理完成后,下一步是定义一个函数,该函数训练两个模型来预测来自气象站的温度和湿度。
为了评估回归模型的性能,使用R^2,即决定系数。R^2越高,表明模型能更好地预测数据。
def train_and_evaluate(target):
# Split into features and target
X = df.drop(target, axis=1)
y = df[target]
# Split the dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define the model
model = cuLinearRegression()
# Train the model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
r2 = r2_score(y_test, predictions)
print(f"R^2 score for predicting {target} is {r2}")
return model
现在函数已经写好了,下一步是用下面的调用来训练模型,指定目标变量:
# Train and evaluate models
temperature_model = train_and_evaluate('t')
humidity_model = train_and_evaluate('hu')
这个示例演示了如何使用cuML线性回归来使用西北数据集预测温度、湿度和降水。为了评估回归模型的性能,我们使用R^2分数。值得注意的是,通过探索特征选择、正则化和高级模型等技术,可以进一步提高模型性能。
聚类
聚类是一种无监督机器学习(ML)技术,用于根据相似实例的特征对其进行分组。它有助于识别数据中的模式和结构。将探讨使用K-Means(一种流行的基于质心的聚类算法)基于温度和降水对天气条件进行聚类。
首先,预处理数据集。重点关注两个具体特征:温度(t)和降水(pp)。为简单起见,任何缺少值的行都将被删除。
import cudf
from cuml import KMeans
# Load data
df = cudf.read_csv("/NW_data.csv").dropna()
# Select the features for clustering
features = ['t', 'pp']
df_kmeans = df[features]
接下来,对数据应用K-Means聚类。目标是将数据划分为指定数量的簇,每个簇由其中的数据点的平均值表示。
# Initialize the KMeans model
kmeans = KMeans(n_clusters=5, random_state=42)
# Fit the model
kmeans.fit(df_kmeans)
拟合模型后,检索聚类标签,表示每个数据点所属的聚类。
# Get the cluster labels
kmeans_labels = kmeans.labels_
# Add the cluster labels as new columns to the dataframe
df['KMeans_Labels_Temperature'] = cudf.Series(kmeans_labels)
df['KMeans_Labels_Precipitation'] = cudf.Series(kmeans_labels)
模型训练与表现
为了评估聚类模型的质量,检查惯性,它表示每个数据点与其最近的质心之间的距离的平方和。较低的惯性值会表明更紧密和更清晰。
# Print the inertia values
print("Temperature Inertia:")
print(kmeans.inertia_)
print("Precipitation Inertia:")
print(kmeans.inertia_)
确定K-Means中的最佳簇数是很重要的。肘形法通过绘制不同簇数的惯性值来帮助找到理想的簇数。“肘”点表示最小化惯性和避免过多集群之间的最佳平衡。
UMAP在cuML中可用,是一种强大的降维算法,用于可视化高维数据和揭示底层模式。虽然UMAP本身不是专用的聚类算法,但它将数据投射到较低维空间的能力经常揭示聚类结构。它广泛用于集群探索和分析,为数据提供有价值的见解。它在cuML中的高效实现聚类任务提供了高级数据分析和模式识别。
部署cuML模型
训练了cuML模型,您就可以将其部署到NVIDIA Triton上。Triton是一个开源、可扩展和生产就绪的推理服务器,可用于将cuML模型部署到各种平台,包括云、本地和边缘设备。
在生产环境中有效地部署经过训练的cuML模型对于提取其全部潜力至关重要。对于用cuML训练的模型,有两种主要方法:
1. Triton的FIL后端
2. Triton Python后端
FIL后端为NVIDIA Triton
Triton的FIL后端使Triton用户能够利用cuML的森林推理库(FIL)来加速树模型的推理,包括决策森林和梯度增强森林。
它提供了对XGBoost和LightGBM模型的本地支持,以及对使用Treelite序列化格式的cuML和Scikit-Learn树模型的支持。虽然FIL GPU模式提供了最先进的GPU加速性能,但它也为原型部署或极端小批量延迟比总体吞吐量更重要的部署提供了优化的CPU模式。
Triton Python后端
部署模型的另一种灵活方法是使用Triton Python后端。这个后端使您能够直接调用RAPIDS Python库。它非常灵活,因此您可以编写自定义Python脚本来处理预处理和后处理。
要使用Triton Python后端部署一个cuML模型,你需要:
1. 编写一个Python脚本,Triton Server可以调用该脚本进行推理。这个脚本应该处理任何必要的预处理和后处理。
2. 配置Triton Inference Server,让它使用这个Python脚本来服务你的模型。
在所有情况下,Triton Inference Server为所有的模型提供了一个统一的接口,使其更容易集成到您现有的服务和基础设施。它还支持传入请求的动态批处理,从而减少计算资源,从而降低部署成本。
RAPIDS 基准测试
本文是机器学习概论(Introduction to Machine Learning Using cuML notebook)的完整工作流程的简化讲解。该工作流程将数据加载、预处理和ML训练的组合工作流程的速度提高了44倍。这些结果是在具有RAPIDS 23.04和Intel Core i7-7800X CPU的NVIDIA RTX 8000 GPU上执行的。
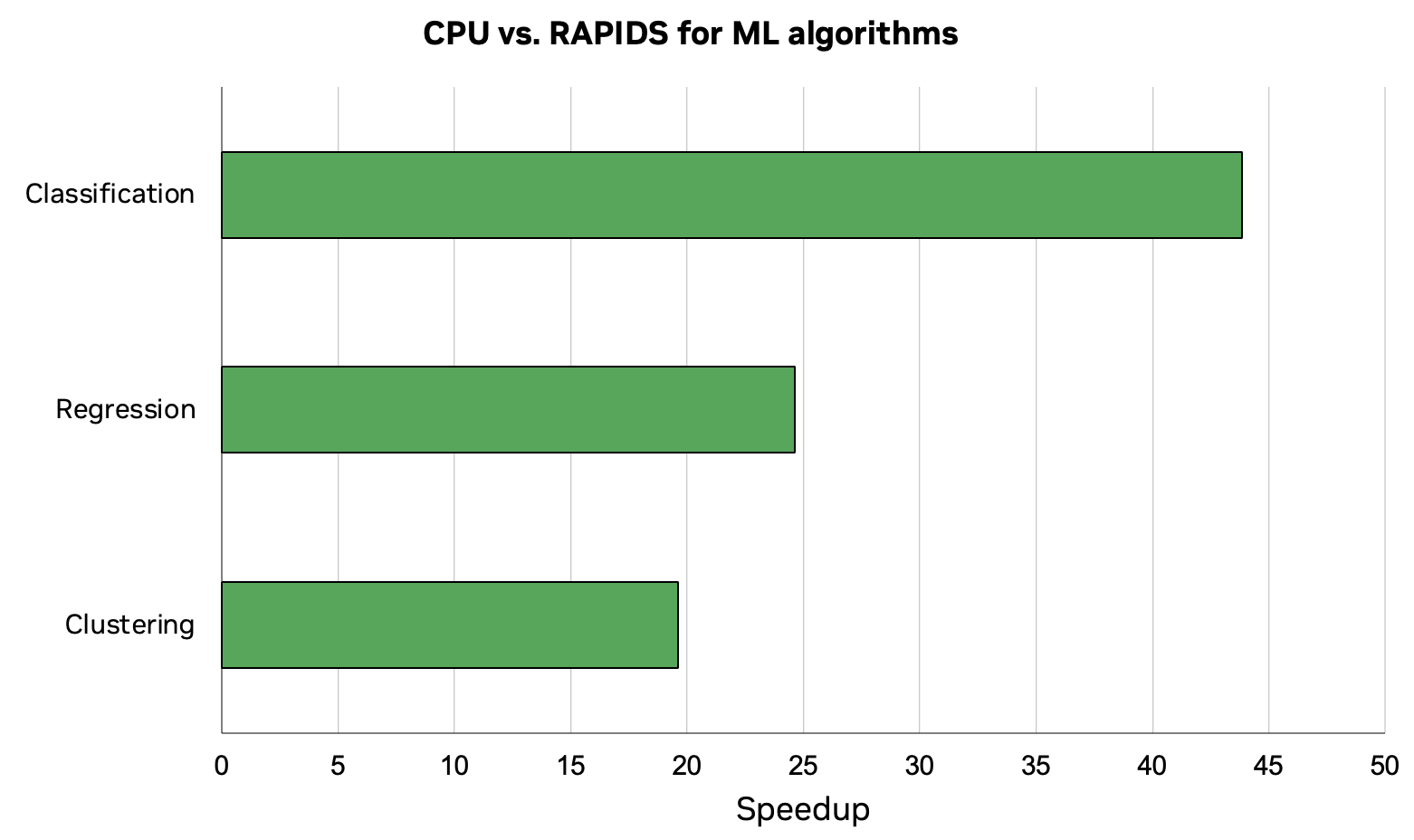
结论
GPU加速机器学习与cuDF和cuML可以大大加快你的数据科学管道。通过使用cuDF和与cuML scikit-learn兼容的API进行更快的数据预处理,可以很容易地开始利用GPU的功能进行机器学习。
来源:https://developer.nvidia.com/blog/accelerated-data-analytics-machine-learning-with-gpu-accelerated-pandas-and-scikit-learn/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消