











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






稳定扩散:生成式人工智能背后的基本直觉
2023年06月30日 由 Samoyed 发表
320648
0
本文主要内容为稳定扩散的总体概述,并着重建立对生成式人工智能如何工作的基本理解。
在过去的几年里,无论是在计算机视觉还是自然语言处理领域,人工智能的世界都快速转向了生成式模型。dale -2和Midjourney引起了人们的注意,并让人们认识到生成式人工智能领域正在发挥着重要作用。
目前大多数人工智能生成的图像都依赖于扩散模型作为基础。本文的目的是说明关于稳定扩散的一些概念,并提供对所采用方法的基本理解。
这个流程图显示了一个稳定扩散架构的简化版本。我们将一点一点地介绍它,以便更好地了解它的内部工作原理。我们将详细说明训练过程,以提供更好的理解,而推理过程则只有一些细微的变化。
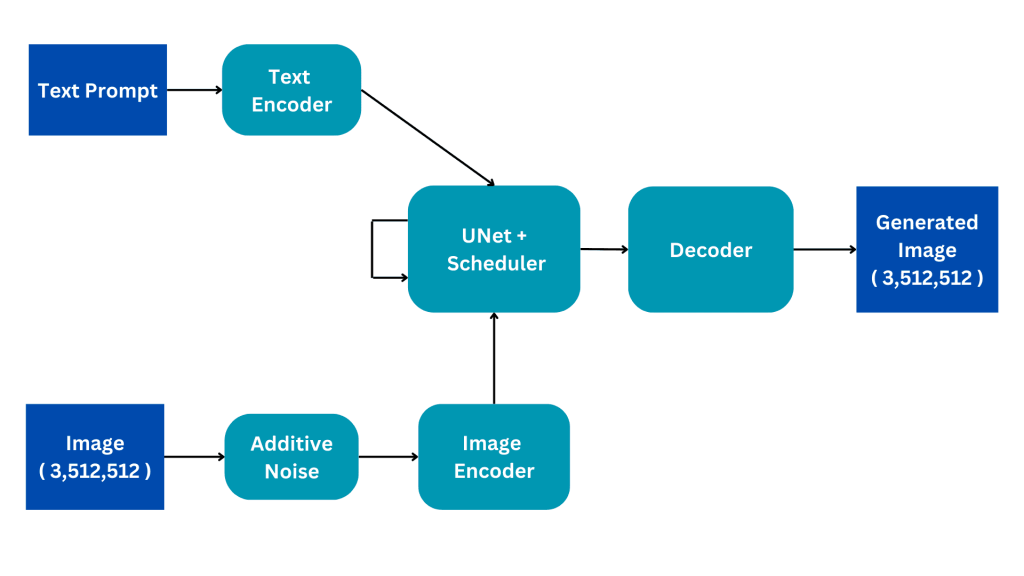
输入
稳定扩散模型是在图像标题数据集上训练的,每张图像都有一个相关的标题或提示来描述该图像。因此,该模型有两个输入;一个自然语言的文本提示和一个大小为(3,512,512)的图像,有3个颜色通道,尺寸为512。
添加噪声
通过在原始图像中加入高斯噪声,将图像转换为完全噪声。这个过程经过连续的步骤进行,例如,图像会连续50步添加一小部分噪声,直到图像完全变为噪声。扩散过程将旨在去除这些噪声并重新生成原始图像。如何做到这一点将进一步解释。
图像编码器
图像编码器的功能是Variational AutoEncoder的一个组件,将图像转换为“潜在空间”并将其调整为较小的尺寸,例如(4,64,64),同时还包括额外的批处理尺寸。这个过程减少了计算需求并提高了性能。与原始扩散模型不同,稳定扩散模型将编码步骤纳入潜在维数,从而减少了计算量、训练和推理时间。
文本编码器
文本编码器将自然语言提示转换为矢量化嵌入。这个过程使用了一个Transformer Language模型,比如BERT或基于GPT的CLIP Text模型。增强的文本编码器模型显著提高了生成图像的质量。文本编码器的输出结果由每个单词的768维嵌入向量数组组成。为了控制提示符长度,设置了最大77个限制。因此,文本编码器产生一个尺寸为(77,768)的张量。
UNet
这是架构中计算成本最高的部分,主要的扩散处理在这里进行。它接收文本编码和噪声潜在图像作为输入。该模块旨在从接收到的噪声图像中再现原始图像。它通过几个推理步骤来实现这一点,这些推理步骤可以设置为一个超参数。通常50个推理步骤就足够了。
考虑一个简单的场景,通过在50个连续步骤中逐渐引入少量噪声,将输入图像转换为噪声。这种累积的噪声最终将原始图像转化为完全的噪声。UNet的目标是通过预测在前一个时间段添加的噪声来逆转这一过程。在去噪过程中,UNet首先预测初始时间段在第50个时间段添加的噪声。然后,它从输入图像中减去这个预测的噪声并重复这一过程。在随后的每个时间段,UNet预测在前一个时间段添加的噪声,逐渐从完全的噪声中恢复原始输入图像。在整个过程中,UNet内部依靠文本嵌入矢量作为调节因素。
UNet输出一个大小为(4,64,64)的张量,该张量被传递给变分自动编码器的解码器部分。
解码器
解码器将编码器进行的潜在表示转换逆转回图像空间。它接收一个潜在表示并将其转换回图像空间。因此,它输出一个大小为(3,512,512)的图像,与原始输入空间的大小相同。在训练过程中,我们的目标是最小化原始图像和生成图像之间的损失。因此,通过给定一个文本提示,我们可以从完全噪声的图像中生成与提示相关的图像。
在推理过程中,我们没有输入图像。我们只在文本到图像模式下工作。我们去掉了加性噪声部分,转而使用一个随机生成的所需大小的张量。架构的其余部分保持不变。
UNet经过训练,利用文本提示嵌入,从完全的噪声中生成一个图像。这个特定的输入在推理阶段被使用,使我们能够成功地从噪声中生成合成图像。这个一般概念是所有生成性计算机视觉模型背后的基本直觉。
来源:https://www.kdnuggets.com/2023/06/stable-diffusion-basic-intuition-behind-generative-ai.html
介绍
在过去的几年里,无论是在计算机视觉还是自然语言处理领域,人工智能的世界都快速转向了生成式模型。dale -2和Midjourney引起了人们的注意,并让人们认识到生成式人工智能领域正在发挥着重要作用。
目前大多数人工智能生成的图像都依赖于扩散模型作为基础。本文的目的是说明关于稳定扩散的一些概念,并提供对所采用方法的基本理解。
简化结构
这个流程图显示了一个稳定扩散架构的简化版本。我们将一点一点地介绍它,以便更好地了解它的内部工作原理。我们将详细说明训练过程,以提供更好的理解,而推理过程则只有一些细微的变化。
输入
稳定扩散模型是在图像标题数据集上训练的,每张图像都有一个相关的标题或提示来描述该图像。因此,该模型有两个输入;一个自然语言的文本提示和一个大小为(3,512,512)的图像,有3个颜色通道,尺寸为512。
添加噪声
通过在原始图像中加入高斯噪声,将图像转换为完全噪声。这个过程经过连续的步骤进行,例如,图像会连续50步添加一小部分噪声,直到图像完全变为噪声。扩散过程将旨在去除这些噪声并重新生成原始图像。如何做到这一点将进一步解释。
图像编码器
图像编码器的功能是Variational AutoEncoder的一个组件,将图像转换为“潜在空间”并将其调整为较小的尺寸,例如(4,64,64),同时还包括额外的批处理尺寸。这个过程减少了计算需求并提高了性能。与原始扩散模型不同,稳定扩散模型将编码步骤纳入潜在维数,从而减少了计算量、训练和推理时间。
文本编码器
文本编码器将自然语言提示转换为矢量化嵌入。这个过程使用了一个Transformer Language模型,比如BERT或基于GPT的CLIP Text模型。增强的文本编码器模型显著提高了生成图像的质量。文本编码器的输出结果由每个单词的768维嵌入向量数组组成。为了控制提示符长度,设置了最大77个限制。因此,文本编码器产生一个尺寸为(77,768)的张量。
UNet
这是架构中计算成本最高的部分,主要的扩散处理在这里进行。它接收文本编码和噪声潜在图像作为输入。该模块旨在从接收到的噪声图像中再现原始图像。它通过几个推理步骤来实现这一点,这些推理步骤可以设置为一个超参数。通常50个推理步骤就足够了。
考虑一个简单的场景,通过在50个连续步骤中逐渐引入少量噪声,将输入图像转换为噪声。这种累积的噪声最终将原始图像转化为完全的噪声。UNet的目标是通过预测在前一个时间段添加的噪声来逆转这一过程。在去噪过程中,UNet首先预测初始时间段在第50个时间段添加的噪声。然后,它从输入图像中减去这个预测的噪声并重复这一过程。在随后的每个时间段,UNet预测在前一个时间段添加的噪声,逐渐从完全的噪声中恢复原始输入图像。在整个过程中,UNet内部依靠文本嵌入矢量作为调节因素。
UNet输出一个大小为(4,64,64)的张量,该张量被传递给变分自动编码器的解码器部分。
解码器
解码器将编码器进行的潜在表示转换逆转回图像空间。它接收一个潜在表示并将其转换回图像空间。因此,它输出一个大小为(3,512,512)的图像,与原始输入空间的大小相同。在训练过程中,我们的目标是最小化原始图像和生成图像之间的损失。因此,通过给定一个文本提示,我们可以从完全噪声的图像中生成与提示相关的图像。
将一切结合在一起
在推理过程中,我们没有输入图像。我们只在文本到图像模式下工作。我们去掉了加性噪声部分,转而使用一个随机生成的所需大小的张量。架构的其余部分保持不变。
UNet经过训练,利用文本提示嵌入,从完全的噪声中生成一个图像。这个特定的输入在推理阶段被使用,使我们能够成功地从噪声中生成合成图像。这个一般概念是所有生成性计算机视觉模型背后的基本直觉。
来源:https://www.kdnuggets.com/2023/06/stable-diffusion-basic-intuition-behind-generative-ai.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消