











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






从声音到视觉:认识AudioToken,一种音频到图像合成的技术
2023年06月25日 由 Neo 发表
952106
0
神经生成模型已经改变了我们消费数字内容的方式,革新了各个方面。它们具有生成高质量图像、确保文本长跨度的连贯性以及生成语音和音频的能力。在不同的方法中,基于扩散的生成模型近期受到了广泛的关注,并在各种任务上展现出了令人瞩目的效果。
在扩散过程中,模型学习将预定义的噪声分布映射到目标数据分布。在每一步,模型预测噪声并从目标分布生成信号。扩散模型可以处理不同形式的数据表示,例如原始输入和潜在表示。
诸如Stable Diffusion、DALLE和Midjourney等最先进的模型已经为文本到图像合成任务开发出来。尽管近年来对X到Y生成的兴趣增加了,但音频到图像模型还没有得到深入的探索。 使用音频信号而不是文本提示的原因是因为视频背景下图像和音频之间的相互联系。相比之下,尽管基于文本的生成模型可以产生出色的图像,但文本描述与图像并没有内在的联系,这意味着文本描述通常是手动添加的。音频信号还具有表示复杂场景和对象的能力,例如同一乐器(如古典吉他、原声吉他、电吉他等)或同一对象(如在录音室和现场演出中录制的古典吉他)的不同变化。对于不同对象的这种详细信息的手动注释是劳动密集型的,这使得可扩展性面临挑战。
先前的研究提出了几种从图像输入生成音频的方法,主要使用生成对抗网络(GAN)根据音频录制生成图像。然而,他们的工作与所提出的方法有显著区别。一些方法只专注于生成MNIST数字,没有将其方法扩展到包括一般音频声音。其他人确实从一般音频生成图像,但结果是低质量的图像。
为了克服这些研究的局限性,Audio提出了一种用于音频到图像生成的深度学习模型。其概述如下图所示。
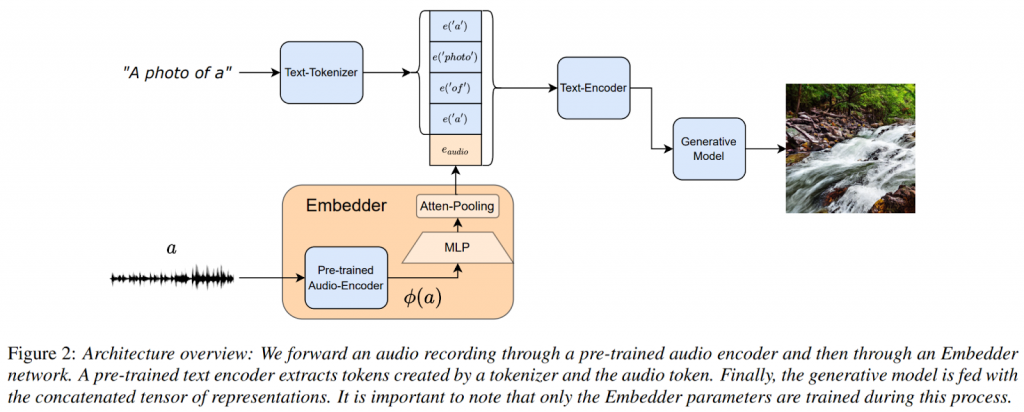
该方法涉及利用一个预训练的文本到图像生成模型和一个预训练的音频表示模型来学习它们输出和输入之间的映射适应层。借鉴最近关于文本反转的工作,引入了一个专用的AudioToken来将音频表示映射到一个嵌入向量。然后将该向量作为一个连续表示转发到网络中,反映了一个新的词嵌入。
音频嵌入器利用一个预训练的音频分类网络来捕捉音频的表示。通常,判别网络的最后一层用于分类目的,但它经常忽略了与判别任务无关的重要音频细节。为了解决这个问题,该方法将较早的层与最后一个隐藏层结合起来,得到一个音频信号的时序嵌入。
下面报告了由所提出的模型产生的一些样本结果。

来源:https://www.marktechpost.com/2023/06/22/from-sound-to-sight-meet-audiotoken-for-audio-to-image-synthesis/
在扩散过程中,模型学习将预定义的噪声分布映射到目标数据分布。在每一步,模型预测噪声并从目标分布生成信号。扩散模型可以处理不同形式的数据表示,例如原始输入和潜在表示。
诸如Stable Diffusion、DALLE和Midjourney等最先进的模型已经为文本到图像合成任务开发出来。尽管近年来对X到Y生成的兴趣增加了,但音频到图像模型还没有得到深入的探索。 使用音频信号而不是文本提示的原因是因为视频背景下图像和音频之间的相互联系。相比之下,尽管基于文本的生成模型可以产生出色的图像,但文本描述与图像并没有内在的联系,这意味着文本描述通常是手动添加的。音频信号还具有表示复杂场景和对象的能力,例如同一乐器(如古典吉他、原声吉他、电吉他等)或同一对象(如在录音室和现场演出中录制的古典吉他)的不同变化。对于不同对象的这种详细信息的手动注释是劳动密集型的,这使得可扩展性面临挑战。
先前的研究提出了几种从图像输入生成音频的方法,主要使用生成对抗网络(GAN)根据音频录制生成图像。然而,他们的工作与所提出的方法有显著区别。一些方法只专注于生成MNIST数字,没有将其方法扩展到包括一般音频声音。其他人确实从一般音频生成图像,但结果是低质量的图像。
为了克服这些研究的局限性,Audio提出了一种用于音频到图像生成的深度学习模型。其概述如下图所示。
该方法涉及利用一个预训练的文本到图像生成模型和一个预训练的音频表示模型来学习它们输出和输入之间的映射适应层。借鉴最近关于文本反转的工作,引入了一个专用的AudioToken来将音频表示映射到一个嵌入向量。然后将该向量作为一个连续表示转发到网络中,反映了一个新的词嵌入。
音频嵌入器利用一个预训练的音频分类网络来捕捉音频的表示。通常,判别网络的最后一层用于分类目的,但它经常忽略了与判别任务无关的重要音频细节。为了解决这个问题,该方法将较早的层与最后一个隐藏层结合起来,得到一个音频信号的时序嵌入。
下面报告了由所提出的模型产生的一些样本结果。
来源:https://www.marktechpost.com/2023/06/22/from-sound-to-sight-meet-audiotoken-for-audio-to-image-synthesis/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消