











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






ChatGPT将造成不利于其发展的网络环境
2023年06月20日 由 Samoyed 发表
766633
0
生成式人工智能让每个人都更有创造力。像ChatGPT这样的大型语言模型可以生成优质的论文和文章。扩散模型,如稳定扩散和DALL-E可以创造出优秀的图像。
但是,当互联网充斥着人工智能生成的内容时,会发生什么呢?这些内容最终将被收集并用于训练生成模型的下一个迭代。根据牛津大学、剑桥大学、伦敦帝国理工学院和多伦多大学的研究人员的一项研究,用生成式人工智能生成的内容训练的机器学习模型将会有不可逆转的缺陷,这些缺陷会在几代之间逐渐加剧。

保持未来模型质量和完整性的唯一方法是确保它们接受人工生成内容的训练。但随着ChatGPT和GPT-4等大型语言模型能够大规模地创建内容,人工创建的数据可能很快就会成为一种奢侈品,很少有人能负担得起。
模型崩溃
在他们的论文中,研究人员研究了当由例如GPT-4产生的文本构成后续模型的大部分训练数据集时会发生什么。
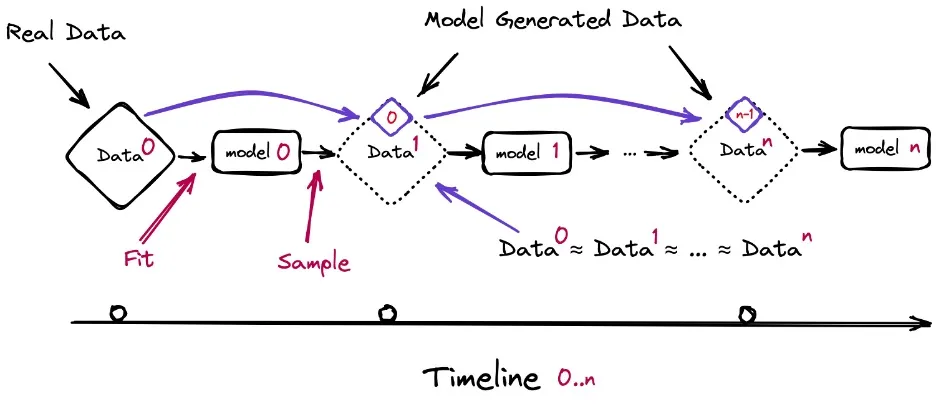
“随着n代的增加,GPT版本GPT-{n}会发生什么?”研究人员写道。"我们发现,从其他模型产生的数据中学习会导致模型崩溃——这是一个退化过程,随着时间的推移,模型会忘记真正的基础数据分布,甚至在分布没有随时间变化的情况下"。
机器学习模型是试图学习数据分布的统计引擎。所有种类的机器学习模型都是如此,从图像分类器到回归模型再到生成文本和图像的更复杂的模型。
模型的参数越接近基础分布,它们在预测现实世界的事件时就越准确。
然而,即使是最复杂的模型也只是真实世界的近似值。因此,他们倾向于高估可能性更大的事件,而低估可能性更小的事件,尽管差距很小。当递归地重新训练自己时,这些错误会堆积起来,模型会崩溃。最终,序列中的后期模型将偏离用于训练它们的自然数据的原始分布。
[caption id="attachment_53448" align="alignnone" width="936"]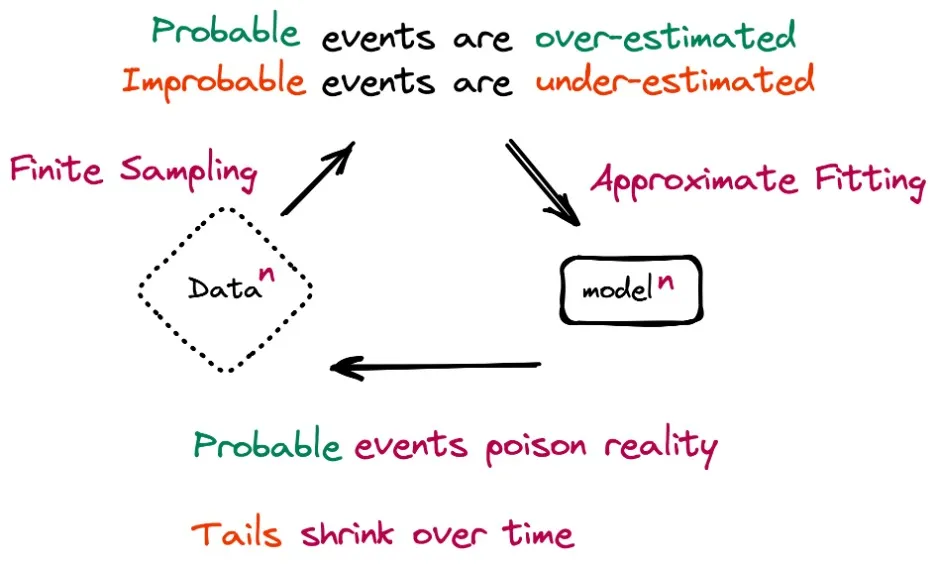 基于生成式AI数据的模型递归训练导致模型崩溃(来源:arXiv)[/caption]
基于生成式AI数据的模型递归训练导致模型崩溃(来源:arXiv)[/caption]
模型崩溃与灾难性遗忘有关,这种问题发生在不断接受新数据训练的模型上。灾难性遗忘导致机器学习模型逐渐忘记在其生命周期早期用于训练它们的信息。模型崩溃不会清除先前学习的数据,但会导致模型以错误的方式解释它。
模型崩溃还与数据中毒有关,在这个过程中,恶意行为者试图通过故意修改用于训练模型的数据来操纵模型的行为。模型崩溃可以被认为是数据中毒的一种形式。然而,不是有人故意污染训练数据,而是模型和训练过程污染了训练数据。
生成式人工智能的模型崩溃
在他们的研究中,研究人员在他们自己的数据上模拟了训练生成模型的效果。他们测试了三种模型:高斯混合模型(GMM)、变分自编码器(VAE)和大型语言模型(LLM)。
GMM的任务是分离两个人工生成的高斯函数。该模型首先在由固定函数生成的数据集上进行训练。然后用它来生成新数据并重新训练下一个模型。在50代的时间里,数据的分布完全改变了。在第2000代,它失去了所有的方差。
[caption id="attachment_53450" align="alignnone" width="740"]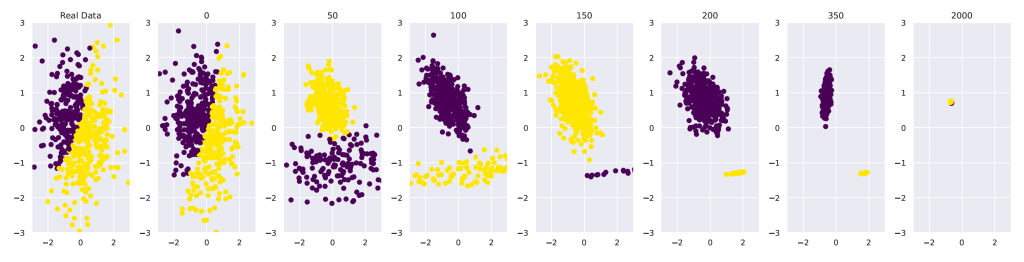 高斯混合模型(GMM)的模型跨代崩溃。[/caption]
高斯混合模型(GMM)的模型跨代崩溃。[/caption]
使用VAE生成手写数字。初始模型是在真实数据上进行训练的。下一代是根据以前模型产生的数据进行训练的。图像逐渐变得模糊,到第10代时,它们变得难以理解。
[caption id="attachment_53457" align="alignnone" width="740"] 变分自编码器(VAE)跨代模型崩溃。[/caption]
变分自编码器(VAE)跨代模型崩溃。[/caption]
然后,研究人员在OPT-125m (Meta的开源大型语言模型的一个小版本)上测试了他们的假设。他们评估了一个常见的场景,在这个场景中,一个预先训练好的模型与最近的数据进行了微调,其微调数据是由另一个微调的预训练模型产生的。
他们测试了两种不同的场景。在第一种方法中,只有大型语言模型生成的数据用于微调。在第二种方法中,原始人工生成数据的一小部分也被添加到训练组合中。
研究人员写道:“这两种训练方式都会导致我们模型的性能下降,但我们发现,使用生成的数据进行学习是可能的,模型可以成功地学习(部分)基本的任务。”
然而,他们的发现也表明,随着时间的推移,这些模型产生的样本会被原始模型产生的概率更高。
“同时,我们发现生成的数据具有更长的尾部,这意味着由于生成数据的学习而累积的错误,一些数据永远不会被原始模型生成。”研究人员写道。
研究人员写道:“与此同时,我们发现生成的数据有更长的尾部,这表明一些数据永远不会由原始模型产生——这些错误是由于对代际数据的学习而积累起来的。”
[caption id="attachment_53455" align="alignnone" width="740"]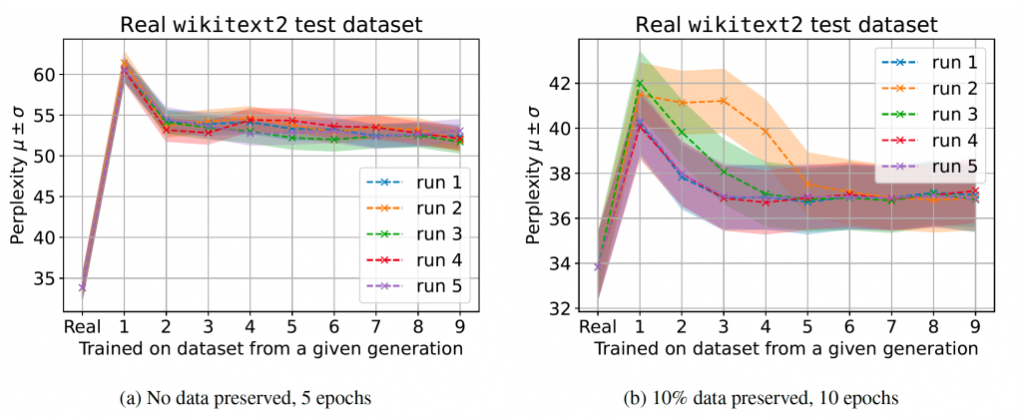 跨代的大型语言模型(LLM)上的模型崩溃。[/caption]
跨代的大型语言模型(LLM)上的模型崩溃。[/caption]
未来几代ChatGPT会发生什么?
数字时代造成了各种各样的数据污染。搜索引擎算法在很大程度上影响了人们撰写在线内容的方式。不良行为者采用各种技术来确保他们的内容在搜索引擎结果页面上排名靠前。我们在社交媒体内容推荐算法上也看到了同样的效果,不良行为者使用有争议的标题来吸引用户并推广他们的内容。
然而,虽然前面的问题可以通过更改排名算法来缓解,但大型语言模型造成的影响很难检测和抵消。
研究人员写道:“我们的评估表明,大型语言模型等培训模式具有‘先发优势’。”这意味着能够访问真正的人工生成文本的平台和公司将在创建高质量模型方面具有优势。在那之后,网络可能会被人工智能生成的内容淹没。
研究人员建议采取措施,随着时间的推移保留对原始数据的访问。然而,目前尚不清楚如何大规模跟踪和过滤大型语言模型生成的内容。这可能成为未来几个月或几年科技公司之间新一波创新和竞争的焦点。
来源:https://bdtechtalks.com/2023/06/19/chatgpt-model-collapse/
但是,当互联网充斥着人工智能生成的内容时,会发生什么呢?这些内容最终将被收集并用于训练生成模型的下一个迭代。根据牛津大学、剑桥大学、伦敦帝国理工学院和多伦多大学的研究人员的一项研究,用生成式人工智能生成的内容训练的机器学习模型将会有不可逆转的缺陷,这些缺陷会在几代之间逐渐加剧。
保持未来模型质量和完整性的唯一方法是确保它们接受人工生成内容的训练。但随着ChatGPT和GPT-4等大型语言模型能够大规模地创建内容,人工创建的数据可能很快就会成为一种奢侈品,很少有人能负担得起。
模型崩溃
在他们的论文中,研究人员研究了当由例如GPT-4产生的文本构成后续模型的大部分训练数据集时会发生什么。
“随着n代的增加,GPT版本GPT-{n}会发生什么?”研究人员写道。"我们发现,从其他模型产生的数据中学习会导致模型崩溃——这是一个退化过程,随着时间的推移,模型会忘记真正的基础数据分布,甚至在分布没有随时间变化的情况下"。
机器学习模型是试图学习数据分布的统计引擎。所有种类的机器学习模型都是如此,从图像分类器到回归模型再到生成文本和图像的更复杂的模型。
模型的参数越接近基础分布,它们在预测现实世界的事件时就越准确。
然而,即使是最复杂的模型也只是真实世界的近似值。因此,他们倾向于高估可能性更大的事件,而低估可能性更小的事件,尽管差距很小。当递归地重新训练自己时,这些错误会堆积起来,模型会崩溃。最终,序列中的后期模型将偏离用于训练它们的自然数据的原始分布。
[caption id="attachment_53448" align="alignnone" width="936"]
基于生成式AI数据的模型递归训练导致模型崩溃(来源:arXiv)[/caption]模型崩溃与灾难性遗忘有关,这种问题发生在不断接受新数据训练的模型上。灾难性遗忘导致机器学习模型逐渐忘记在其生命周期早期用于训练它们的信息。模型崩溃不会清除先前学习的数据,但会导致模型以错误的方式解释它。
模型崩溃还与数据中毒有关,在这个过程中,恶意行为者试图通过故意修改用于训练模型的数据来操纵模型的行为。模型崩溃可以被认为是数据中毒的一种形式。然而,不是有人故意污染训练数据,而是模型和训练过程污染了训练数据。
生成式人工智能的模型崩溃
在他们的研究中,研究人员在他们自己的数据上模拟了训练生成模型的效果。他们测试了三种模型:高斯混合模型(GMM)、变分自编码器(VAE)和大型语言模型(LLM)。
GMM的任务是分离两个人工生成的高斯函数。该模型首先在由固定函数生成的数据集上进行训练。然后用它来生成新数据并重新训练下一个模型。在50代的时间里,数据的分布完全改变了。在第2000代,它失去了所有的方差。
[caption id="attachment_53450" align="alignnone" width="740"]
高斯混合模型(GMM)的模型跨代崩溃。[/caption]使用VAE生成手写数字。初始模型是在真实数据上进行训练的。下一代是根据以前模型产生的数据进行训练的。图像逐渐变得模糊,到第10代时,它们变得难以理解。
[caption id="attachment_53457" align="alignnone" width="740"]
变分自编码器(VAE)跨代模型崩溃。[/caption]然后,研究人员在OPT-125m (Meta的开源大型语言模型的一个小版本)上测试了他们的假设。他们评估了一个常见的场景,在这个场景中,一个预先训练好的模型与最近的数据进行了微调,其微调数据是由另一个微调的预训练模型产生的。
他们测试了两种不同的场景。在第一种方法中,只有大型语言模型生成的数据用于微调。在第二种方法中,原始人工生成数据的一小部分也被添加到训练组合中。
研究人员写道:“这两种训练方式都会导致我们模型的性能下降,但我们发现,使用生成的数据进行学习是可能的,模型可以成功地学习(部分)基本的任务。”
然而,他们的发现也表明,随着时间的推移,这些模型产生的样本会被原始模型产生的概率更高。
“同时,我们发现生成的数据具有更长的尾部,这意味着由于生成数据的学习而累积的错误,一些数据永远不会被原始模型生成。”研究人员写道。
研究人员写道:“与此同时,我们发现生成的数据有更长的尾部,这表明一些数据永远不会由原始模型产生——这些错误是由于对代际数据的学习而积累起来的。”
[caption id="attachment_53455" align="alignnone" width="740"]
跨代的大型语言模型(LLM)上的模型崩溃。[/caption]未来几代ChatGPT会发生什么?
数字时代造成了各种各样的数据污染。搜索引擎算法在很大程度上影响了人们撰写在线内容的方式。不良行为者采用各种技术来确保他们的内容在搜索引擎结果页面上排名靠前。我们在社交媒体内容推荐算法上也看到了同样的效果,不良行为者使用有争议的标题来吸引用户并推广他们的内容。
然而,虽然前面的问题可以通过更改排名算法来缓解,但大型语言模型造成的影响很难检测和抵消。
研究人员写道:“我们的评估表明,大型语言模型等培训模式具有‘先发优势’。”这意味着能够访问真正的人工生成文本的平台和公司将在创建高质量模型方面具有优势。在那之后,网络可能会被人工智能生成的内容淹没。
研究人员建议采取措施,随着时间的推移保留对原始数据的访问。然而,目前尚不清楚如何大规模跟踪和过滤大型语言模型生成的内容。这可能成为未来几个月或几年科技公司之间新一波创新和竞争的焦点。
来源:https://bdtechtalks.com/2023/06/19/chatgpt-model-collapse/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消