











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何利用AutoML Python包优化机器学习模型的开发和调整过程
2023年06月15日 由 Alex 发表
202567
0
介绍
自动机器学习(AutoML)是人工智能领域中一个不断发展的领域,其着重于使非专家能够更轻松地使用机器学习。自动机器学习的目标是自动化构建和部署机器学习模型中最耗时和复杂的任务,例如特征工程、算法选择和超参数调整。许多 ML/DL 工程师都会认同,在每个新项目中不断经历相同阶段的过程可能会变得乏味。
AutoML背后的思想是创建一组工具,这些工具可以自动化整个ML过程,从数据准备和模型选择到训练、测试和部署。最终目标是使机器学习更容易访问和使用,因此各种规模的企业和组织都可以从它提供的洞察力和预测能力中受益。对于资源有限或缺乏构建和维护自己的ML基础架构的专业知识的企业来说,这尤其有价值。
这个领域已经发展了几年,现在有很多AutoML包和库可以帮助自动化ML过程。今天看下其中最受欢迎的几个。
AutoML包
“AutoKeras”
它是一个流行的Python开源AutoML库,允许用户轻松构建和训练深度学习模型,而无需在该领域拥有深厚的专业知识。该库可以作为Python pip包安装,需要Python>=3.7和TensorFlow>=2.8.0。顾名思义,这个库在底层使用Keras框架。
AutoKeras自动化了模型选择、超参数调优和架构搜索的过程。它使用一种称为神经结构搜索(NAS)的技术来自动找到给定任务的最佳结构。它是通过随机或基于某种预定义策略评估多个候选架构来搜索最佳神经网络架构的过程。该库支持各种任务,如图像分类、回归、文本分类、结构化数据分类和时间序列预测。它还包括用于数据增强、规范化和特征工程的预处理模块。
由于使用了直观但有限的API,这个库的使用示例相对较短。根据任务的不同,你需要创建优化器的实例类:
Max_trials表示要进行实验的模型的最大数量。AutoKeras提供了一些自定义的神经架构搜索,所以你可以指定哪种类型的架构你想要运行搜索,例如,仅ResNets:
在指定模型类型之后,运行NAS时唯一需要关心的是每个假设的epoch数:
总的来说,AutoKeras是一个功能强大的库,可以非常快速地为标准任务列表构建模型。让我们总结一下AutoKeras的优缺点:
优点:
缺点:
“AutoGluon”
AutoGluon是另一个由Amazon Web Services(AWS)团队开发的用于自动机器学习(AutoML)的开源库。除了我们为AutoKeras讨论的NAS之外,这个库还包括一个称为“堆叠”的功能,它结合了多个ML/DL模型来提高预测的整体准确性。堆叠包括在相同的数据集上训练多个模型,然后将它们的预测作为另一个模型的输入,该模型输出最终的预测。
AutoGluon的另一个特性是,它内置了对分布式训练的支持,允许用户在多台机器上训练模型,以提高性能。通过在本地机器上搜索,这一点并不是很明显,但如果在云基础架构中运行NAS,这将成为一个关键优势。分布式搜索的设置非常简单,只需要指定可用资源的数量和远程机器的地址即可。
与AutoKeras相比,AutoGluon还支持更广泛的任务,例如,可解释的基于规则的模型、表格数据的特征工程和对象检测任务。该库在优化过程中提供了一些自定义的模型搜索,并提供了广泛的超参数,此外还可以通过库API为NAS预定义搜索空间。
文本分类模型的一个简单示例如下:
所有经过训练的模型都被序列化并保存以备部署。库有一个非常强大的文档,搜索栏,多个任务的备忘单和非常活跃的github开发人员社区。
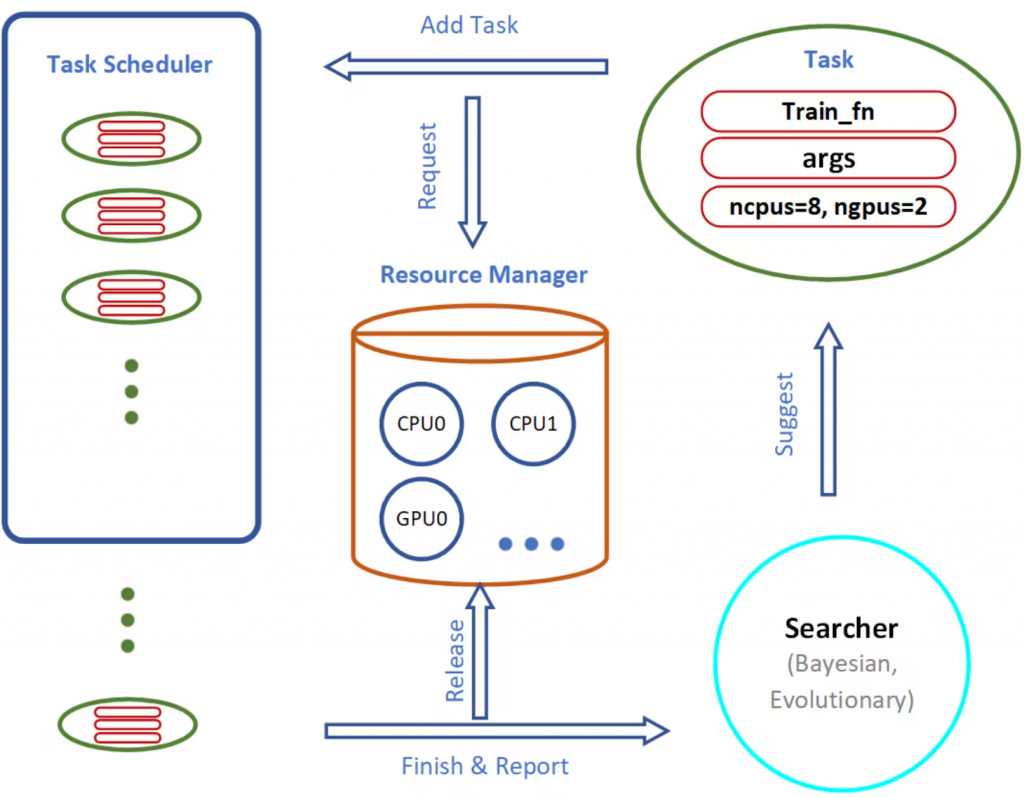
让我们总结一下AutoGluon的优缺点:
优点:
缺点:
“AutoSklearn”
它建立在流行的机器学习库scikit-learn之上。AutoSklearn将开发人员从算法选择和超参数调优中解放出来。它利用了贝叶斯优化、元学习和集成构建方面的最新优势(来自团队的NIPS论文)。这是在数据集上测试多个模型的最有限但同时也是最快的方法之一。该库不需要任何ML知识并提供简单的API。最简单的用法示例只需要4行代码:
可以在github存储库中找到更多关于库使用的示例。值得一提的是,该库已经朝着自定义模型的微调方向发展。例如,对于MLP,你可以定义超参数搜索空间并利用AutoSklearn的最优优化策略(与bruteforce超参数调优相比)。
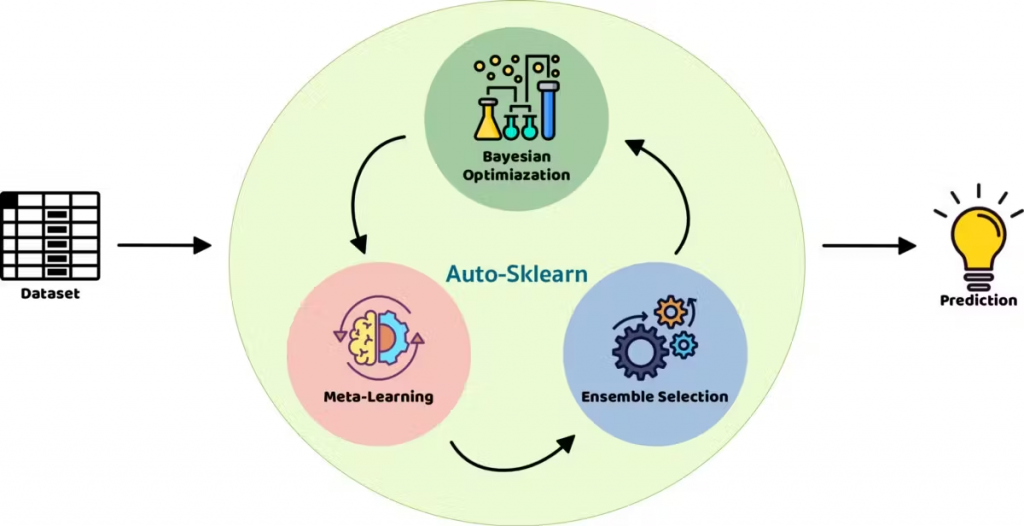
总结一下这个库,它的优缺点:
优点:
缺点:
TPOT
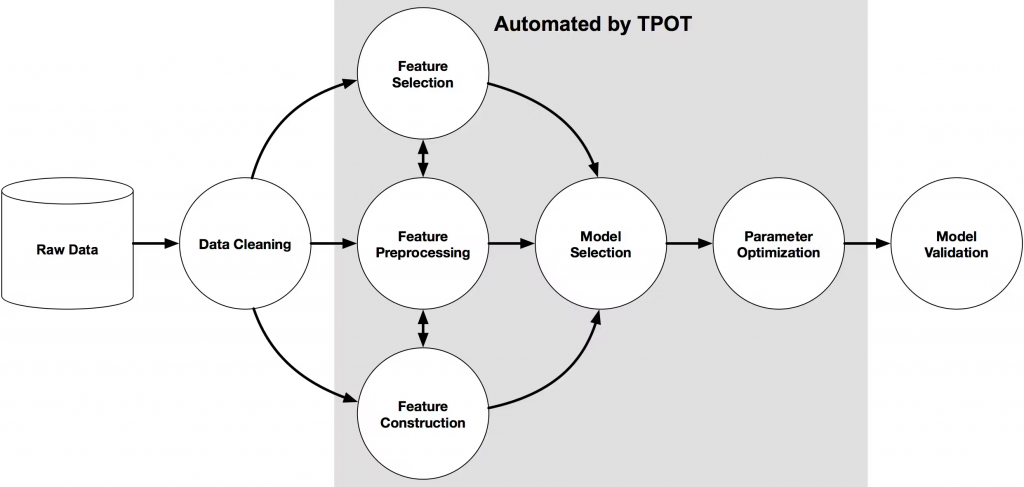
我们在最后介绍的库是TPOT。该库使用遗传编程自动化构建机器学习管道的过程。它旨在通过探索数千种可能的管道来找到最适合你的数据的管道,从而自动化ML中最乏味的部分。
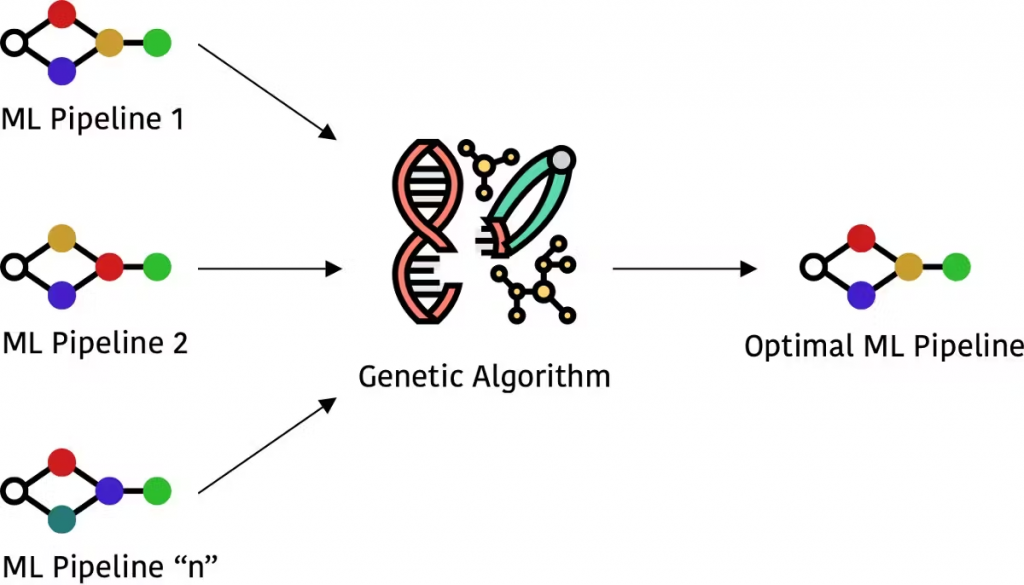
遗传编程方法受到达尔文关于自然选择的概念的启发,具有以下特点:
该库建立在scikit-learn之上,并使用类似的界面来训练和测试模型。TPOT支持分类和回归任务,并包括广泛的预构建机器学习操作,如缩放、输入、特征选择和模型选择。它还允许用户指定自己的自定义操作,使他们在设计管道时具有更大的灵活性。分类任务的最小工作示例类似于AutoSklearn:
总结一下这个库,它的优缺点:
优点:
缺点:
结论
总之,AutoML包为构建、优化和部署机器学习模型提供了自动化的解决方案。这些软件包可以自动执行繁琐和耗时的任务,如超参数调优、特征选择或模型架构选择,为机器学习从业者节省大量的时间和精力。
每个AutoML包使用不同的优化方案,为管道提供不同的模型列表,支持各种类型的自定义,并提供分布式搜索机会。没有适用于所有任务和需求的万能解决方案,你应该根据你的任务和可用资源选择最合适的软件包。在AutoML包的帮助下,ML/DL工程师可以更多地关注问题的高级方面,而不是构建和优化模型的低级细节。
来源:https://rtriangle.hashnode.dev/automl-python-packages
自动机器学习(AutoML)是人工智能领域中一个不断发展的领域,其着重于使非专家能够更轻松地使用机器学习。自动机器学习的目标是自动化构建和部署机器学习模型中最耗时和复杂的任务,例如特征工程、算法选择和超参数调整。许多 ML/DL 工程师都会认同,在每个新项目中不断经历相同阶段的过程可能会变得乏味。
AutoML背后的思想是创建一组工具,这些工具可以自动化整个ML过程,从数据准备和模型选择到训练、测试和部署。最终目标是使机器学习更容易访问和使用,因此各种规模的企业和组织都可以从它提供的洞察力和预测能力中受益。对于资源有限或缺乏构建和维护自己的ML基础架构的专业知识的企业来说,这尤其有价值。
这个领域已经发展了几年,现在有很多AutoML包和库可以帮助自动化ML过程。今天看下其中最受欢迎的几个。
AutoML包
“AutoKeras”
它是一个流行的Python开源AutoML库,允许用户轻松构建和训练深度学习模型,而无需在该领域拥有深厚的专业知识。该库可以作为Python pip包安装,需要Python>=3.7和TensorFlow>=2.8.0。顾名思义,这个库在底层使用Keras框架。
AutoKeras自动化了模型选择、超参数调优和架构搜索的过程。它使用一种称为神经结构搜索(NAS)的技术来自动找到给定任务的最佳结构。它是通过随机或基于某种预定义策略评估多个候选架构来搜索最佳神经网络架构的过程。该库支持各种任务,如图像分类、回归、文本分类、结构化数据分类和时间序列预测。它还包括用于数据增强、规范化和特征工程的预处理模块。
由于使用了直观但有限的API,这个库的使用示例相对较短。根据任务的不同,你需要创建优化器的实例类:
#for images
img_clf = autokeras.ImageClassifier(max_trials=10, num_classes=10)
img_reg = autokeras.ImageRegressor(overwrite=True, max_trials=1)
#for texts
text_clf = autokeras.TextClassifier(overwrite=True, max_trials=1)
text_reg = autokeras.TextRegressor(overwrite=True, max_trials=10)
#for structured data
str_clf = autokeras.StructuredDataClassifier(overwrite=True,max_trials=3)
str_reg = autokeras.StructuredDataRegressor(overwrite=True,max_trials=3)
Max_trials表示要进行实验的模型的最大数量。AutoKeras提供了一些自定义的神经架构搜索,所以你可以指定哪种类型的架构你想要运行搜索,例如,仅ResNets:
input_node = autokeras.ImageInput()
output_node = autokeras.ImageBlock(
# Only search ResNet architectures.
block_type="resnet",
normalize=False,
augment=False,
)(input_node)
output_node = autokeras.RegressionHead()(output_node)
regr = autokeras.AutoModel(inputs=input_node, outputs=output_node,
overwrite=True, max_trials=1
)
在指定模型类型之后,运行NAS时唯一需要关心的是每个假设的epoch数:
img_clf.fit(X_train, y_train, validation_data=(X_val, y_val))
_, acc = img_clf.evaluate(X_test, y_test)
总的来说,AutoKeras是一个功能强大的库,可以非常快速地为标准任务列表构建模型。让我们总结一下AutoKeras的优缺点:
优点:
1.自动化:实现模型选择、超参数调优和架构搜索过程的自动化;
2.灵活性:支持多种任务,包括图像分类、回归、文本分类、结构化数据分类、时间序列预测等;
3.速度:它可以快速搜索大量可能的模型和超参数,使用户能够比手动更快地构建和训练模型;
缺点:
1.有限的定制:虽然库是灵活的,但它不像手动编写深度学习代码那样可定制。你可能会发现很难执行自定义损失函数和层类型;
2.资源强度:它可能是资源密集型的,特别是在搜索大量模型和超参数时;
3.黑盒:图书馆的内部工作对用户是隐藏的,尤其是架构搜索过程。可能很难理解为什么AutoKeras选择一个特定的模型或一组超参数。
“AutoGluon”
AutoGluon是另一个由Amazon Web Services(AWS)团队开发的用于自动机器学习(AutoML)的开源库。除了我们为AutoKeras讨论的NAS之外,这个库还包括一个称为“堆叠”的功能,它结合了多个ML/DL模型来提高预测的整体准确性。堆叠包括在相同的数据集上训练多个模型,然后将它们的预测作为另一个模型的输入,该模型输出最终的预测。
AutoGluon的另一个特性是,它内置了对分布式训练的支持,允许用户在多台机器上训练模型,以提高性能。通过在本地机器上搜索,这一点并不是很明显,但如果在云基础架构中运行NAS,这将成为一个关键优势。分布式搜索的设置非常简单,只需要指定可用资源的数量和远程机器的地址即可。
extra_node_ips = ['172.31.3.95']
scheduler = ag.scheduler.FIFOScheduler(
train_fn,
resource={'num_cpus': 2, 'num_gpus': 1},
dist_ip_addrs=extra_node_ips)
scheduler.run(num_trials=20)
scheduler.join_jobs()
与AutoKeras相比,AutoGluon还支持更广泛的任务,例如,可解释的基于规则的模型、表格数据的特征工程和对象检测任务。该库在优化过程中提供了一些自定义的模型搜索,并提供了广泛的超参数,此外还可以通过库API为NAS预定义搜索空间。
文本分类模型的一个简单示例如下:
import uuid
from autogluon.core.utils.loaders import load_pd
from autogluon.multimodal import MultiModalPredictor
# data with 2 columns 'sentence' for text and 'label' for label
train_data = load_pd.load('PATH_TO_DATA')
test_data = load_pd.load('PATH_TO_DATA')
model_path = f"./tmp/{uuid.uuid4().hex}-automm_sst"
predictor = MultiModalPredictor(label='label', eval_metric='acc', path=model_path)
# here we limit each trial with time unlike number of models max_trials in AutoKeras
predictor.fit(train_data, time_limit=180)
test_score = predictor.evaluate(test_data, metrics=['acc', 'f1'])
test_predictions = predictor.predict(test_data)
所有经过训练的模型都被序列化并保存以备部署。库有一个非常强大的文档,搜索栏,多个任务的备忘单和非常活跃的github开发人员社区。
让我们总结一下AutoGluon的优缺点:
优点:
1.全自动:AutoGluon自动化了ML/DL模型开发的许多方面(特征工程、特征分析、超参数调优、NAS);
2.最先进的模型:AWS团队不断改进软件包,并集成了最新的模型和方法,以实现高效的NAS。
缺点:
1.局限性:库不涵盖所有任务,只涵盖最流行的任务(表格/图像/文本预测,对象检测和NAS),但它仍然涵盖了许多任务或至少是ML管道中的组件;
2.计算资源:Autogluon主要是为了利用分布式计算而设计的,它可能需要大量的计算资源才能有效地运行。对于计算资源有限的小型组织或个人来说,这可能是一个障碍。
“AutoSklearn”
它建立在流行的机器学习库scikit-learn之上。AutoSklearn将开发人员从算法选择和超参数调优中解放出来。它利用了贝叶斯优化、元学习和集成构建方面的最新优势(来自团队的NIPS论文)。这是在数据集上测试多个模型的最有限但同时也是最快的方法之一。该库不需要任何ML知识并提供简单的API。最简单的用法示例只需要4行代码:
import autosklearn.classification
automl = autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train, y_train)
y_pred = automl.predict(X_test)
# for fitted models leaderboard
automl.leaderboard()
可以在github存储库中找到更多关于库使用的示例。值得一提的是,该库已经朝着自定义模型的微调方向发展。例如,对于MLP,你可以定义超参数搜索空间并利用AutoSklearn的最优优化策略(与bruteforce超参数调优相比)。
总结一下这个库,它的优缺点:
优点:
用法简单:库的API非常简单。正如我们在示例中所看到的,你不需要了解任何ML/DL理论来运行训练,4行代码足以快速获得结果;
缺点:
很明显,该库主要关注scikit-learn包模型。如果你有scikit-learn库无法解决的更复杂的任务,请根据你的需求和资源使用AutoKeras或AutoGluon。
TPOT
我们在最后介绍的库是TPOT。该库使用遗传编程自动化构建机器学习管道的过程。它旨在通过探索数千种可能的管道来找到最适合你的数据的管道,从而自动化ML中最乏味的部分。
遗传编程方法受到达尔文关于自然选择的概念的启发,具有以下特点:
1.选择阶段:对每个个体的适应度函数进行评估和归一化,使每个个体的值在0到1之间,所有值的总和为1。接下来,选择0到1之间的一个随机数。保留适应度函数值大于或等于所选数的个体;
2.交叉:选择上一阶段保留的最适合的个体,在它们之间进行交叉操作,生成新的种群;
3.突变:通过交叉生成的个体会经过随机修改,并且该过程会重复一定次数或直到获得最佳种群。
该库建立在scikit-learn之上,并使用类似的界面来训练和测试模型。TPOT支持分类和回归任务,并包括广泛的预构建机器学习操作,如缩放、输入、特征选择和模型选择。它还允许用户指定自己的自定义操作,使他们在设计管道时具有更大的灵活性。分类任务的最小工作示例类似于AutoSklearn:
from tpot import TPOTClassifier
tpot = TPOTClassifier(generations=10, population_size=50, random_state=5)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
总结一下这个库,它的优缺点:
优点:
TPOT使用遗传编程在可能的管道和超参数空间中搜索,以便为给定的数据集和任务找到最佳组合。与手动调整管道相比,这可以显著提高模型性能;
缺点:
TPOT具有有限的模型兼容性,目前只有sklearn库模型可以用于管道优化
结论
总之,AutoML包为构建、优化和部署机器学习模型提供了自动化的解决方案。这些软件包可以自动执行繁琐和耗时的任务,如超参数调优、特征选择或模型架构选择,为机器学习从业者节省大量的时间和精力。
每个AutoML包使用不同的优化方案,为管道提供不同的模型列表,支持各种类型的自定义,并提供分布式搜索机会。没有适用于所有任务和需求的万能解决方案,你应该根据你的任务和可用资源选择最合适的软件包。在AutoML包的帮助下,ML/DL工程师可以更多地关注问题的高级方面,而不是构建和优化模型的低级细节。
来源:https://rtriangle.hashnode.dev/automl-python-packages

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消