











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






人工智能助力中风预测:从理论到实践
2023年06月14日 由 Alex 发表
882659
0
介绍
根据世界中风组织的数据,我们中有四分之一的人会在我们生命中的某个时刻遭受中风。中风通常是健康因素和生活方式共同作用的结果。知道了这一点,如果我们能够弄清楚哪些行为导致的风险最大,我们就可以在中风发生之前预测到它。
进口
启动任何python项目需要做的第一件事是导入必要的库。(注意,其中一些是在项目后期因需要时导入的)
数据
与任何项目一样,我们也需要数据。让我们将CSV文件读入DataFrame并查看其内容。

正如我们所看到的,我们的数据中有各种列,包括个人属性(如年龄、婚姻状况和职业)、健康问题(如心脏病和高血压)和生活方式(如吸烟状况)。我们还有三个未命名的指标。有些人可能会说这些指标没用,但实际上我们稍后可以用它们来看看它们与中风之间是否存在相关性。
我们再来看看我们的数据统计:
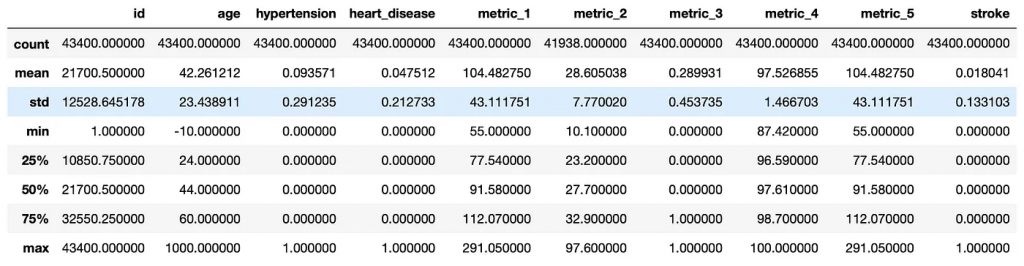
从这些统计信息中,我们可以看出在构建模型之前我们需要对数据进行一些清洗工作。例如,我们有一些难以理解的数据,比如最小年龄是-10岁。我们的 metric_2 和 smoking_status 列中也有一些N/A数据。我们可以针对这些数据进行清洗。
我们可以删除id列,因为它不会向数据集添加任何内容。我们还可以删除年龄小于零的任何行,因为应该假定该数据是错误的。我们可以删除 smoking_status 中的任何N/A列,但在完成模型后,发现使用 fillna(0) 返回了更高的准确度分数。接下来,我们想使用 LabelEncoder() 将所有的对象类型列转换为数字列,以便我们的模型可以使用它们。现在,我们的所有数据都是干净的,没有缺失值。
变量
我们可能不想在模型中使用数据中的每一列。这是因为我们的某些变量将比其他变量更具相关性。我们可以通过手动测试模型中的各种变量来找出提供最佳结果的变量,但有一种更简便的方法。我们可以使用 df.corr() 找到 DataFrame 中每个变量之间的相关性。我还使用 seaborn 的热图来使其更具视觉吸引力。
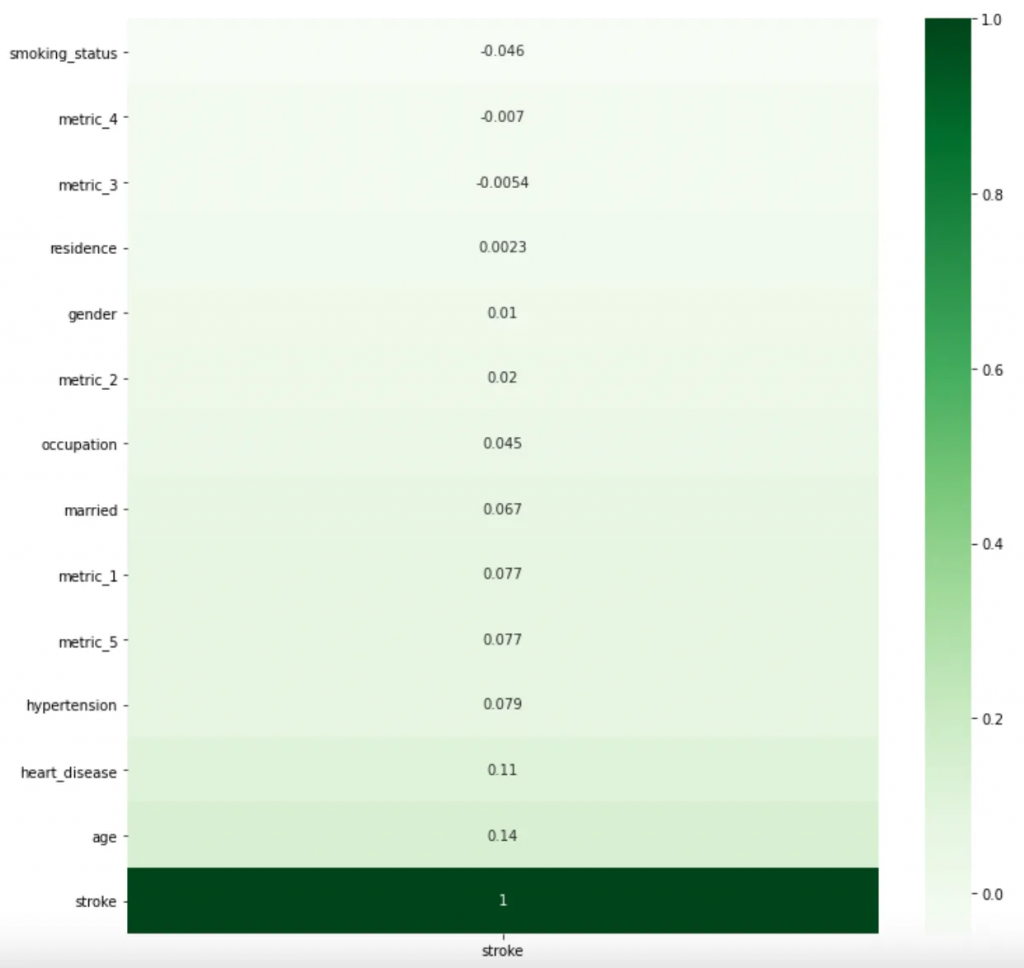
我们现在有一张最相关变量的图表。我们可以看到,年龄、心脏病和高血压等明显的因素都是相对较高的。令人惊讶的是,中风和吸烟之间存在负相关,因为吸烟是众所周知的导致中风的原因。这是一个很好的例子,说明我们为什么需要使用df.corr()。如果我们不这样做,我们可能会假设吸烟者和中风患者之间存在很强的正相关性,并在错误的假设下创建了模型。
模型
现在我们可以开始构建模型了。首先要做的是准备将我们的数据输入到模型中。
经过一系列实验,我发现当只使用正相关变量时,会产生最佳的准确性分数,因此我们选择这些变量作为best_variables。然后我们将数据分成训练和测试数据集。
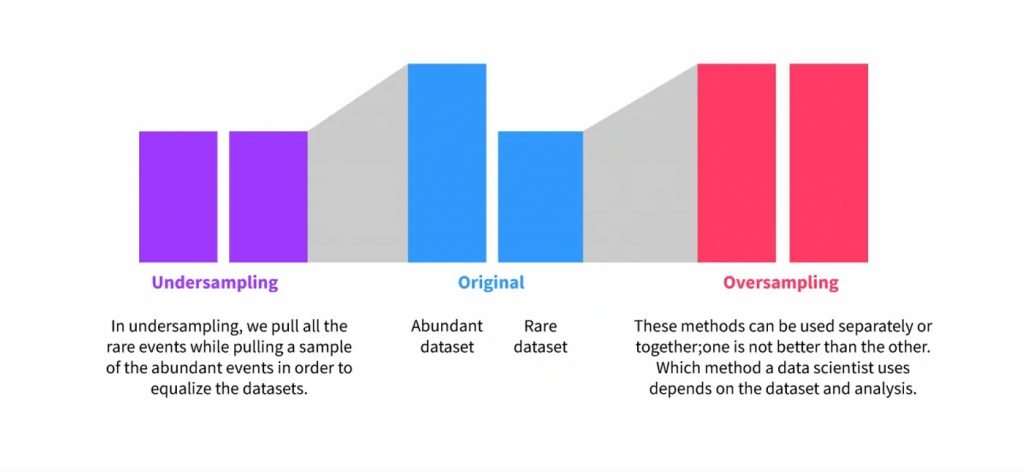
接下来,我们需要平衡我们的数据。这是因为在这个数据集中,中风实际上是非常罕见的,因为我们的数据是纪录不同年龄的普通人的调查结果。如果不经过平衡,我们的模型将非常不准确,因为它没有足够的中风患者来学习准确地预测中风。有许多方法可以做到这一点,但我们将使用一种称为过采样的方法。具体来说,我们将使用一种称为 SMOTE或合成少数过采样技术的技术。我最初打算使用 RandomOverSampler,但 SMOTE 返回了更高的准确度分数。SMOTE将创建大量与其他中风患者具有相似指标的合成中风患者,并将它们随机插入到我们的数据集中。如果您不熟悉过采样技术,以下是一个例子。
现在,我们可以创建模型了。首先,让我们使用逻辑回归模型,因为我们正在试图预测二元结果。我们还将使用StandardScaler,因为我们的数据范围变化很大。
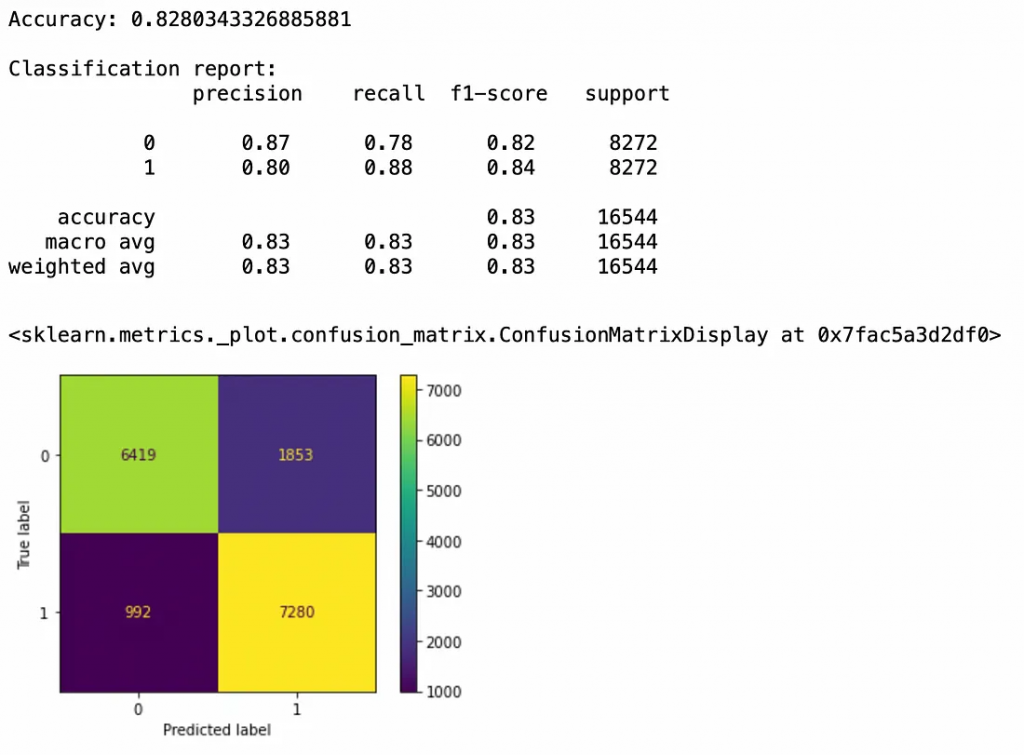
由此可见,我们的模型做得很好。我们的准确率达到了82.8%。我们也可以参考混淆矩阵。我们有6,419个真阴性和7,280个真阳性,相比之下有2,845个假阳性或假阴性。但是,我们可以通过使用不同的模型来提高准确性。让我们试着用不同的模型来提高分数。
我考虑过使用RandomForestClassifier,但它返回的分数与LogisticRegression模型相似。但是,使用流行的XGBoost库,我们可以大大提高准确性。我对超参数进行了一些尝试,并获得了更高的分数。
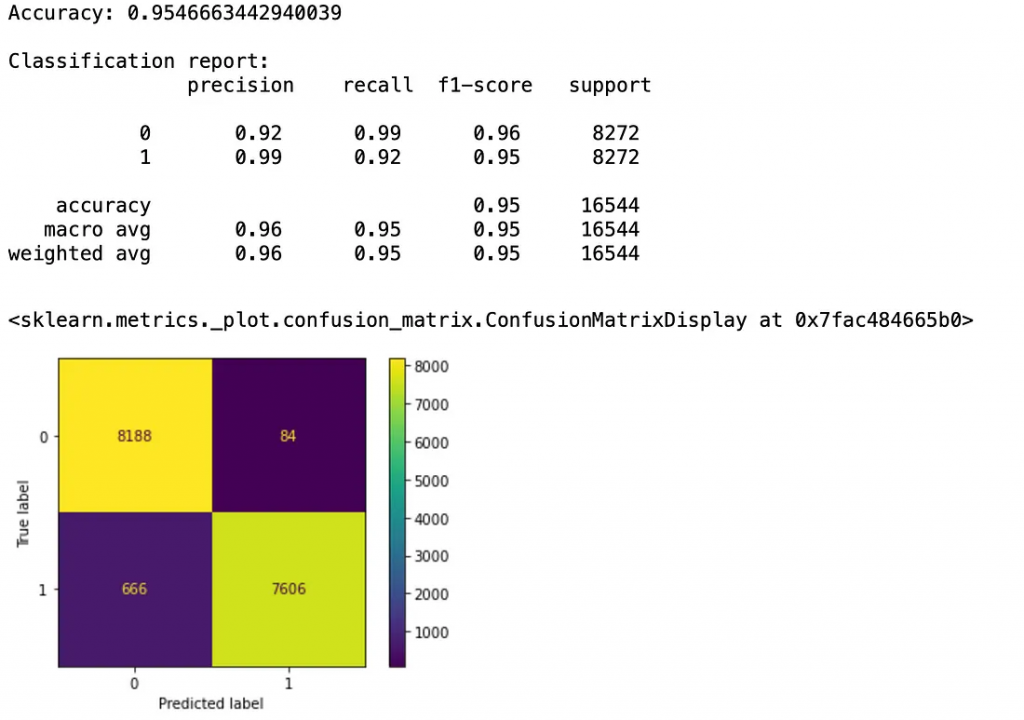
现在,我们有一个大约95.5%的准确模型来预测一个人是否会中风。需要注意的一点是,这个模型在预测中风时非常准确。我们可以通过7606个真阳性和84个假阳性来看到这一点。如果我们是保险公司之类的机构,这样的信息可能非常有价值。
结论
总的来说,我们能够用我们的模型获得非常高的准确度分数。如果我想要最大化模型的效果,我可以进一步进行超参数调整。具体来说,利用 RandomSearchCV 或 GridSearchCV 可能会提高结果。此外,我还可以尝试使用不同的数据清理方法。例如,metric_2 在某些地方遗漏了数据。我正在考虑用该列的平均值替换N/A以查看其效果。总的来说,我认为这是一个成功的项目。
来源:https://medium.com/@gabewalter7/stroke-prediction-machine-learning-model-430f2231cc5d
根据世界中风组织的数据,我们中有四分之一的人会在我们生命中的某个时刻遭受中风。中风通常是健康因素和生活方式共同作用的结果。知道了这一点,如果我们能够弄清楚哪些行为导致的风险最大,我们就可以在中风发生之前预测到它。
进口
启动任何python项目需要做的第一件事是导入必要的库。(注意,其中一些是在项目后期因需要时导入的)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from imblearn.over_sampling import RandomOverSampler
from imblearn.over_sampling import SMOTE
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
数据
与任何项目一样,我们也需要数据。让我们将CSV文件读入DataFrame并查看其内容。
df = pd.read_csv("stroke data.csv")
df.head()正如我们所看到的,我们的数据中有各种列,包括个人属性(如年龄、婚姻状况和职业)、健康问题(如心脏病和高血压)和生活方式(如吸烟状况)。我们还有三个未命名的指标。有些人可能会说这些指标没用,但实际上我们稍后可以用它们来看看它们与中风之间是否存在相关性。
我们再来看看我们的数据统计:
df.describe()
df.isnull().sum()
id 0
gender 0
age 0
married 0
hypertension 0
heart_disease 0
occupation 0
residence 0
metric_1 0
metric_2 1462
metric_3 0
metric_4 0
metric_5 0
smoking_status 13292
stroke 0
dtype: int64
从这些统计信息中,我们可以看出在构建模型之前我们需要对数据进行一些清洗工作。例如,我们有一些难以理解的数据,比如最小年龄是-10岁。我们的 metric_2 和 smoking_status 列中也有一些N/A数据。我们可以针对这些数据进行清洗。
# 通过删除不必要的列、删除不正确的值来处理数据(age = -10); 将列切换为数值数据
df.drop( "id" , axis = 1 , inplace = True )
df.drop(df[(df[ "age" ] < 0 )].index, inplace = True )
# fillna(0)对于 smoking_status 返回比 dropna() 更高的准确度
# 有些问题 fillna() 在 metric_2 上不起作用,所以只需在 fillna(0) 之后使用 dropna()
df[ "smoking_status" ].fillna( 0 )
labeler = LabelEncoder()
c = df.select_dtypes(include = "object" ).columns
df[c] = df[c].apply(labeler.fit_transform)
df.dropna(inplace = True)
我们可以删除id列,因为它不会向数据集添加任何内容。我们还可以删除年龄小于零的任何行,因为应该假定该数据是错误的。我们可以删除 smoking_status 中的任何N/A列,但在完成模型后,发现使用 fillna(0) 返回了更高的准确度分数。接下来,我们想使用 LabelEncoder() 将所有的对象类型列转换为数字列,以便我们的模型可以使用它们。现在,我们的所有数据都是干净的,没有缺失值。
df.isnull().sum()
gender 0
age 0
married 0
hypertension 0
heart_disease 0
occupation 0
residence 0
metric_1 0
metric_2 0
metric_3 0
metric_4 0
metric_5 0
smoking_status 0
stroke 0
dtype: int64
变量
我们可能不想在模型中使用数据中的每一列。这是因为我们的某些变量将比其他变量更具相关性。我们可以通过手动测试模型中的各种变量来找出提供最佳结果的变量,但有一种更简便的方法。我们可以使用 df.corr() 找到 DataFrame 中每个变量之间的相关性。我还使用 seaborn 的热图来使其更具视觉吸引力。
#Find 在模型中使用的最佳变量
plt.figure(figsize=(12,12))
sns.heatmap(df.corr()[["stroke"]].sort_values(by = "stroke"), annot = True, cmap="Greens")
我们现在有一张最相关变量的图表。我们可以看到,年龄、心脏病和高血压等明显的因素都是相对较高的。令人惊讶的是,中风和吸烟之间存在负相关,因为吸烟是众所周知的导致中风的原因。这是一个很好的例子,说明我们为什么需要使用df.corr()。如果我们不这样做,我们可能会假设吸烟者和中风患者之间存在很强的正相关性,并在错误的假设下创建了模型。
模型
现在我们可以开始构建模型了。首先要做的是准备将我们的数据输入到模型中。
# 拆分数据
best_variables = [k for k, v in df.corr()["stroke"].items() if v > 0 and k != "stroke"]
X = df[best_variables]
y = df["stroke"]
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, test_size=0.2, random_state = 42)
经过一系列实验,我发现当只使用正相关变量时,会产生最佳的准确性分数,因此我们选择这些变量作为best_variables。然后我们将数据分成训练和测试数据集。
接下来,我们需要平衡我们的数据。这是因为在这个数据集中,中风实际上是非常罕见的,因为我们的数据是纪录不同年龄的普通人的调查结果。如果不经过平衡,我们的模型将非常不准确,因为它没有足够的中风患者来学习准确地预测中风。有许多方法可以做到这一点,但我们将使用一种称为过采样的方法。具体来说,我们将使用一种称为 SMOTE或合成少数过采样技术的技术。我最初打算使用 RandomOverSampler,但 SMOTE 返回了更高的准确度分数。SMOTE将创建大量与其他中风患者具有相似指标的合成中风患者,并将它们随机插入到我们的数据集中。如果您不熟悉过采样技术,以下是一个例子。
# Balance Data!! Smote achieved slightly higher scores than RandomOverSampler, so went with Smote
# oversample = RandomOverSampler(sampling_strategy="minority")
# Xtrain, ytrain = oversample.fit_resample(Xtrain, ytrain)
# Xtest, ytest = oversample.fit_resample(Xtest, ytest)
smote=SMOTE()
Xtrain, ytrain=smote.fit_resample(Xtrain, ytrain)
Xtest, ytest=smote.fit_resample(Xtest, ytest)
现在,我们可以创建模型了。首先,让我们使用逻辑回归模型,因为我们正在试图预测二元结果。我们还将使用StandardScaler,因为我们的数据范围变化很大。
#创建和训练模型
pipe = Pipeline([("std", StandardScaler()), ("lr", LogisticRegression())])
pipe.fit(Xtrain, ytrain)
# 进行预测
ypred = pipe.predict(Xtest)
# 评分模型
print("Accuracy:", pipe.score(Xtest, ytest))
print("\nClassification report:\n", classification_report(ytest, ypred))
ConfusionMatrixDisplay.from_estimator(pipe, Xtest, ytest)
由此可见,我们的模型做得很好。我们的准确率达到了82.8%。我们也可以参考混淆矩阵。我们有6,419个真阴性和7,280个真阳性,相比之下有2,845个假阳性或假阴性。但是,我们可以通过使用不同的模型来提高准确性。让我们试着用不同的模型来提高分数。
我考虑过使用RandomForestClassifier,但它返回的分数与LogisticRegression模型相似。但是,使用流行的XGBoost库,我们可以大大提高准确性。我对超参数进行了一些尝试,并获得了更高的分数。
# 第二个模型,RandomForestClassifier 返回低分,所以使用 XGBoost
# 创建模型
model = xgb.XGBClassifier(n_estimators= 1000 , max_depth= 5 , learning_rate= 0.1 , objective= "binary:logistic" )
# 拟合模型
model.fit(Xtrain, ytrain )
# 进行预测
ypred = model.predict(Xtest)
# 模型评分
print ( "Accuracy:" , model.score(Xtest, ytest))
print ( "\nClassification report:\n" , classification_report(ytest, ypred))
ConfusionMatrixDisplay .from_estimator(Model,Xtest,ytest)
现在,我们有一个大约95.5%的准确模型来预测一个人是否会中风。需要注意的一点是,这个模型在预测中风时非常准确。我们可以通过7606个真阳性和84个假阳性来看到这一点。如果我们是保险公司之类的机构,这样的信息可能非常有价值。
结论
总的来说,我们能够用我们的模型获得非常高的准确度分数。如果我想要最大化模型的效果,我可以进一步进行超参数调整。具体来说,利用 RandomSearchCV 或 GridSearchCV 可能会提高结果。此外,我还可以尝试使用不同的数据清理方法。例如,metric_2 在某些地方遗漏了数据。我正在考虑用该列的平均值替换N/A以查看其效果。总的来说,我认为这是一个成功的项目。
来源:https://medium.com/@gabewalter7/stroke-prediction-machine-learning-model-430f2231cc5d

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消