











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何使用 LoRA 以一小部分成本微调 LLM
2023年05月25日 由 daydream 发表
931633
0
众所周知,大型语言模型(LLM)的训练、微调和运行成本很高。人们认为,它需要用价值数百万美元的计算训练出具有数千亿参数的模型,才能与GPT-3.5和ChatGPT的能力相匹配。

然而,最近发布的开源LLM已经证明,你不需要非常庞大的模型才能与最先进技术竞争。研究人员已经训练出了几十亿参数的LLM,表现水平可以与非常大的模型相媲美。开源大型语言模型的成功引发了人们对该领域的兴趣。
其中一些工作侧重于使LLM的微调更具成本效益。有助于大幅降低微调成本的技术之一是“低秩自适应”(LoRA)。使用LoRA,你可以以正常成本的一小部分来微调LLM。
这是你需要了解的有关 LoRA 的信息.
微调LLM是如何工作的?
开源LLM,如LLaMA,Pythia和MPT-7B是经过数千亿个单词预训练的基础模型。开发人员和机器学习工程师可以下载带有预训练权重的模型,并对其进行微调,以适应后续任务,如指令遵循。
每个LLM都是一个由几个层块组成的变换器模型,每个层块都包含可学习的参数。在预训练结束的地方继续进行微调。
该模型从微调数据集中获取输入,然后预测下一个标记,并将其输出与基准值进行比较。然后,它会调整权重以纠正其预测。反复进行这个过程,LLM会逐渐微调到下游任务。
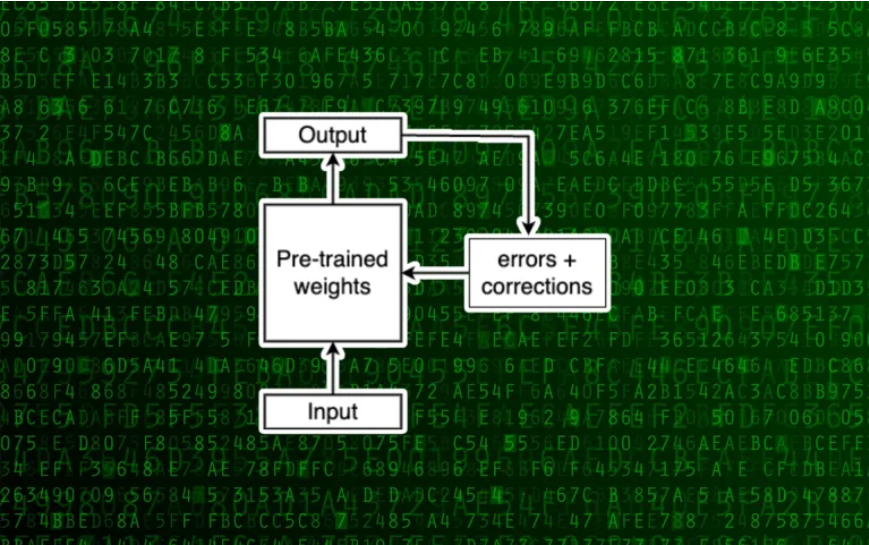
现在,让我们对微调过程进行一个小的修改。在这种新方法中,我们冻结了模型的原始权重,并且在微调过程中不会修改它们。相反,我们将修改应用于一组单独的权重,并将其新值添加到原始参数中。让我们将这两组称为“预训练”和“微调”权重。
分离预训练和微调的参数是 LoRA 的重要组成部分。
低秩适配
在继续讨论LoRA之前,让我们把模型参数想象成非常大的矩阵。如果你还记得线性代数课的话,矩阵可以形成向量空间。在这种情况下,我们讨论的是一个非常大的向量空间,它有很多维度来模拟语言。
每个矩阵都有一个“秩”,即它拥有的线性独立列的数量。如果列是线性独立的,则意味着它不能表示为矩阵中其他列的组合。另一方面,相关列可以表示为同一矩阵中一个或多个列的组合。你可以从矩阵中删除相关列而不会丢失信息。
微软研究人员在一篇论文中提出的LoRA表明,在为下游任务微调LLM时,不需要全秩权重矩阵。他们建议,你可以保留模型的大部分学习能力,同时减少下游参数的维度。(这就是为什么将预先训练和微调的权重分开是有意义的)。
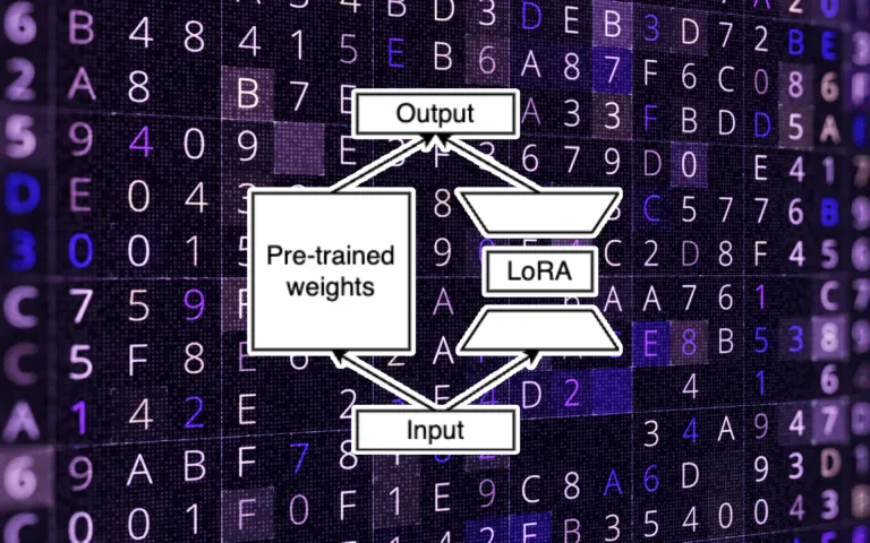
基本上,在LoRA中,你可以创建两个下游权重矩阵。将输入参数从原始维度转换为低秩维度。第二个矩阵将低秩数据转换为原始模型的输出维度。
在训练过程中,会对LoRA参数进行修改,这些参数现在比原始权重小得多。这就是为什么它们可以更快地进行训练,并且只需进行完全微调的一小部分成本。在推理时,将LoRA的输出添加到预先训练的参数中,以计算最终值。
LoRA的额外改进
由于LoRA要求我们将预训练和微调的权重分开,因此会产生内存开销。此外,在推理时添加预训练和微调的权重的操作会导致较小的计算损失。为了克服这个缺点,你可以在使用LoRA对LLM进行微调之后合并微调和预训练的权重。
然而,由于下游权重只占原始权重的一小部分(有时低至千分之一),因此你可能需要将它们分开。将预训练权重和下游权重分开是有好处的。
例如,假设你正在托管一个多个客户端用于不同应用程序的 LLM。每个客户端都希望使用自己的特定数据集和自己的应用程序微调模型。你可以使用 LoRA 为每个客户端或应用程序创建一组下游权重,而不是为每个客户端创建单独的微调模型版本。在推理时,你加载基本模型和每个客户端的LoRA权重,以进行最终计算。你将受到轻微的性能影响,但存储方面的收益将是巨大的。
在 Python 实现 LoRA
这篇文章对LoRA的工作原理进行了非常全面的概述。它有更多的技术细节和细微差别,例如它适用于哪种类型的权重以及它具有的超参数。Sebastian Raschka有一篇很长的文章,他在其中提供了LoRA的技术和实现细节。
来源:https://bdtechtalks.com/2023/05/22/what-is-lora/
然而,最近发布的开源LLM已经证明,你不需要非常庞大的模型才能与最先进技术竞争。研究人员已经训练出了几十亿参数的LLM,表现水平可以与非常大的模型相媲美。开源大型语言模型的成功引发了人们对该领域的兴趣。
其中一些工作侧重于使LLM的微调更具成本效益。有助于大幅降低微调成本的技术之一是“低秩自适应”(LoRA)。使用LoRA,你可以以正常成本的一小部分来微调LLM。
这是你需要了解的有关 LoRA 的信息.
微调LLM是如何工作的?
开源LLM,如LLaMA,Pythia和MPT-7B是经过数千亿个单词预训练的基础模型。开发人员和机器学习工程师可以下载带有预训练权重的模型,并对其进行微调,以适应后续任务,如指令遵循。
每个LLM都是一个由几个层块组成的变换器模型,每个层块都包含可学习的参数。在预训练结束的地方继续进行微调。
该模型从微调数据集中获取输入,然后预测下一个标记,并将其输出与基准值进行比较。然后,它会调整权重以纠正其预测。反复进行这个过程,LLM会逐渐微调到下游任务。
现在,让我们对微调过程进行一个小的修改。在这种新方法中,我们冻结了模型的原始权重,并且在微调过程中不会修改它们。相反,我们将修改应用于一组单独的权重,并将其新值添加到原始参数中。让我们将这两组称为“预训练”和“微调”权重。
分离预训练和微调的参数是 LoRA 的重要组成部分。
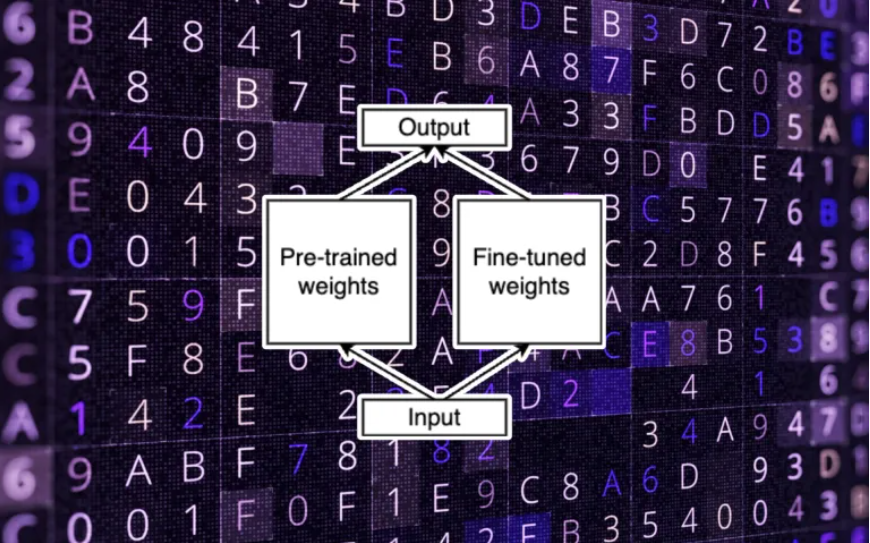
低秩适配
在继续讨论LoRA之前,让我们把模型参数想象成非常大的矩阵。如果你还记得线性代数课的话,矩阵可以形成向量空间。在这种情况下,我们讨论的是一个非常大的向量空间,它有很多维度来模拟语言。
每个矩阵都有一个“秩”,即它拥有的线性独立列的数量。如果列是线性独立的,则意味着它不能表示为矩阵中其他列的组合。另一方面,相关列可以表示为同一矩阵中一个或多个列的组合。你可以从矩阵中删除相关列而不会丢失信息。
微软研究人员在一篇论文中提出的LoRA表明,在为下游任务微调LLM时,不需要全秩权重矩阵。他们建议,你可以保留模型的大部分学习能力,同时减少下游参数的维度。(这就是为什么将预先训练和微调的权重分开是有意义的)。
基本上,在LoRA中,你可以创建两个下游权重矩阵。将输入参数从原始维度转换为低秩维度。第二个矩阵将低秩数据转换为原始模型的输出维度。
在训练过程中,会对LoRA参数进行修改,这些参数现在比原始权重小得多。这就是为什么它们可以更快地进行训练,并且只需进行完全微调的一小部分成本。在推理时,将LoRA的输出添加到预先训练的参数中,以计算最终值。
LoRA的额外改进
由于LoRA要求我们将预训练和微调的权重分开,因此会产生内存开销。此外,在推理时添加预训练和微调的权重的操作会导致较小的计算损失。为了克服这个缺点,你可以在使用LoRA对LLM进行微调之后合并微调和预训练的权重。
然而,由于下游权重只占原始权重的一小部分(有时低至千分之一),因此你可能需要将它们分开。将预训练权重和下游权重分开是有好处的。
例如,假设你正在托管一个多个客户端用于不同应用程序的 LLM。每个客户端都希望使用自己的特定数据集和自己的应用程序微调模型。你可以使用 LoRA 为每个客户端或应用程序创建一组下游权重,而不是为每个客户端创建单独的微调模型版本。在推理时,你加载基本模型和每个客户端的LoRA权重,以进行最终计算。你将受到轻微的性能影响,但存储方面的收益将是巨大的。
在 Python 实现 LoRA
这篇文章对LoRA的工作原理进行了非常全面的概述。它有更多的技术细节和细微差别,例如它适用于哪种类型的权重以及它具有的超参数。Sebastian Raschka有一篇很长的文章,他在其中提供了LoRA的技术和实现细节。
来源:https://bdtechtalks.com/2023/05/22/what-is-lora/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消