











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






梯度下降背后的数学原理几何?(上)
2020年01月11日 由 sunlei 发表
394512
0
对于诸位「MLer」而言,梯度下降这个概念一定不陌生,然而从直观上来看,梯度下降的复杂性无疑也会让人「敬而远之」。本文作者 Suraj Bansal 通过对梯度下降背后的数学原理进行拆解,并配之以简单的现实案例,以轻松而有趣的口吻带大家深入了解梯度下降这一在机器学习领域至关重要的方法。
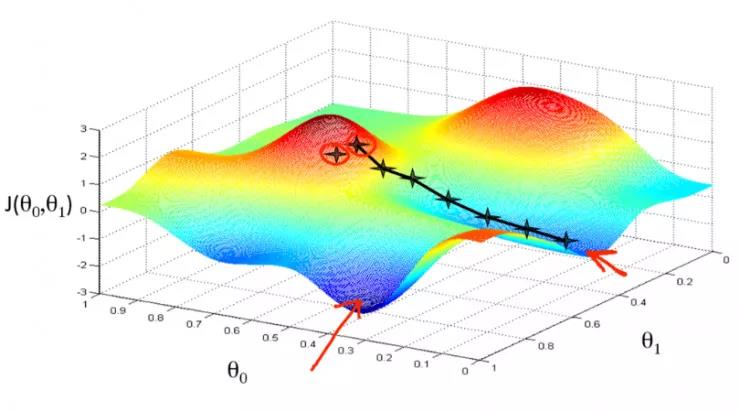
一、梯度下降变体:不止一个
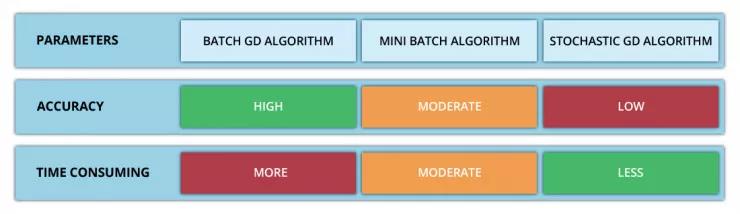
1、第一种变体:批量梯度下降
https://www.datadriveninvestor.com/2019/03/03/editors-pick-5-machine-learning-books/
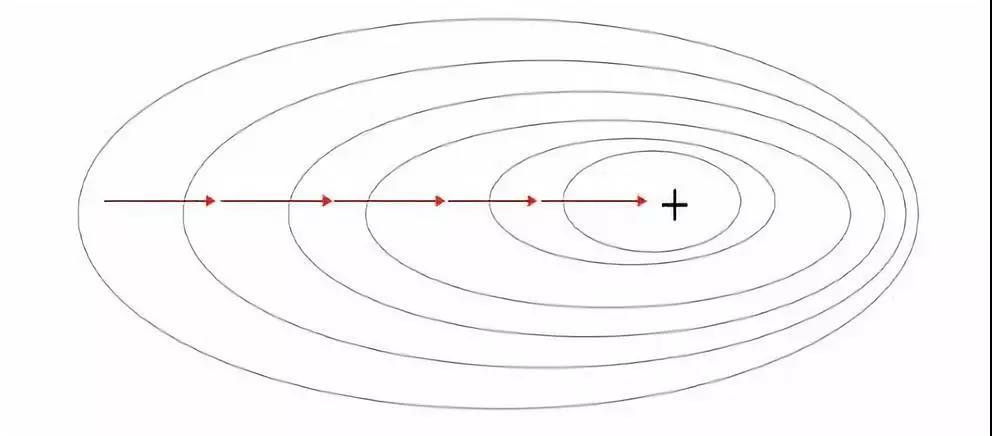
2、第二种变体:随机梯度下降
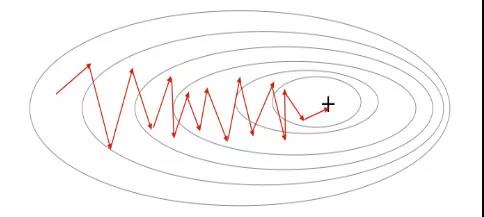
3、第三种变体:迷你批量梯度下降
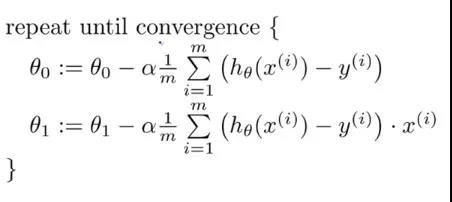
权重向量存在于 x-y 平面中,将对应每个权重的损失函数的梯度与学习率相乘,然后用向量减去二者的乘积。
二、涉及到的一些数学概念
1、偏导数
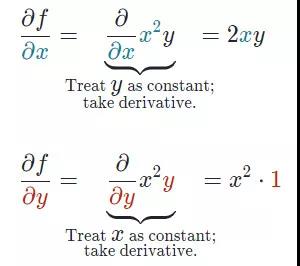
2、梯度
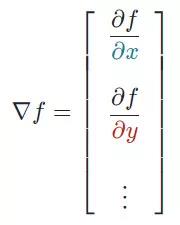
想象自己站在函数 f 以一定间隔排列的点(x0,y0…)之中。向量∇f(x0,y0…)将识别出使 f函数值增加的最快行进方向。有趣的是,梯度矢量∇f(x0,yo…)也垂直于函数 f 的轮廓线!
3、学习率
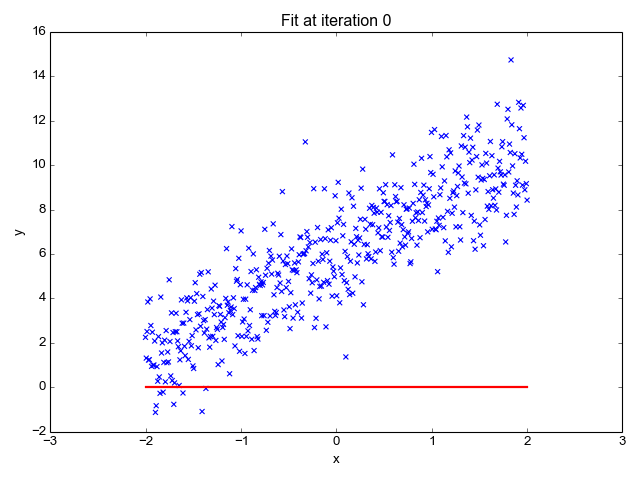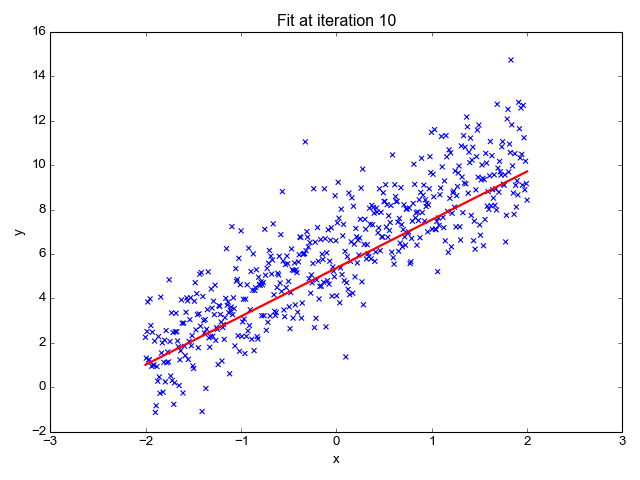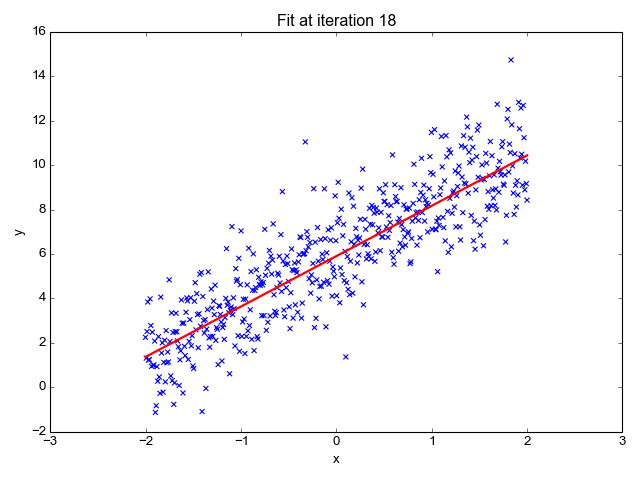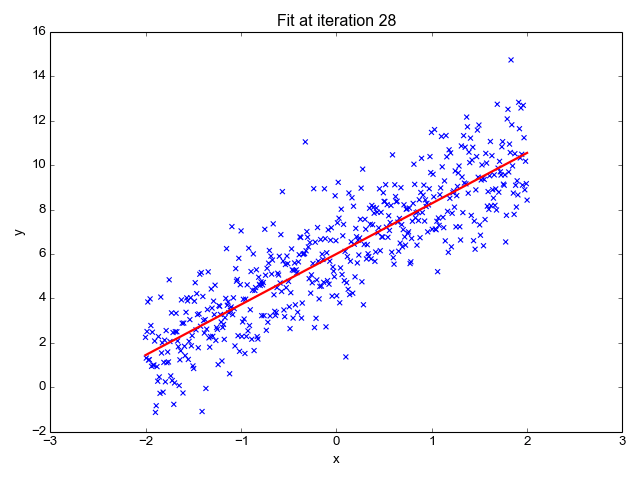

4、成本函数

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
2020必备的五项数据科学技能








广告


写评论取消
回复取消