











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Uber开源Manifold,用于调试AI模型的可视工具
2020年01月08日 由 KING 发表
699739
0

- 与模型无关的通用二进制分类和回归模型调试支持。
- 对表格化要素输入的可视化支持,包括数字,分类和地理空间要素类型。
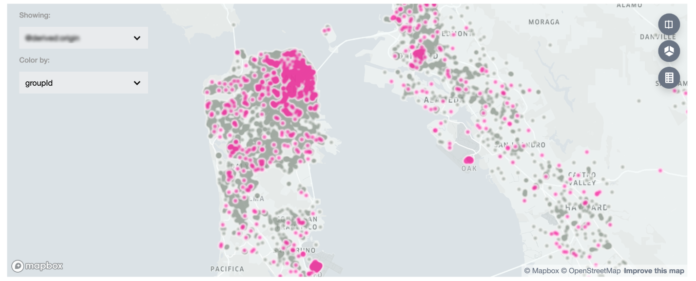
集成块的新升级包括对地理空间特征的可视化支持。
- 与Jupyter Notebook集成。
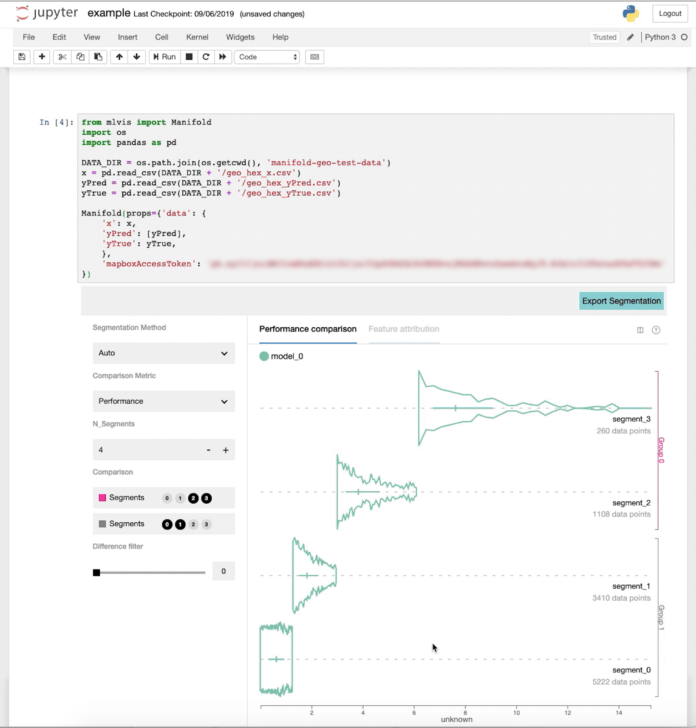
Manifold的Jupyter Notebook集成接受数据输入作为Pandas DataFrame对象,并在Jupyter Notebook UI中呈现可视化效果。
- 基于每个实例的预测损失和其他特征值的交互式数据切片和性能比较。
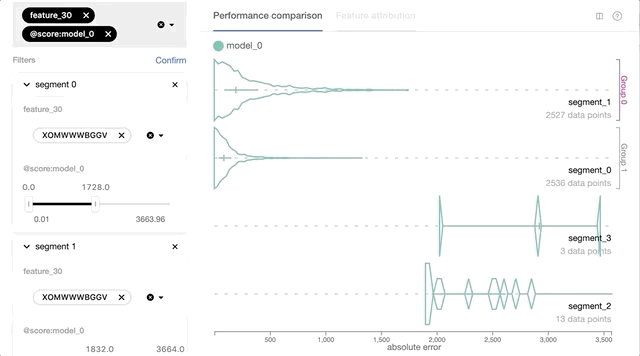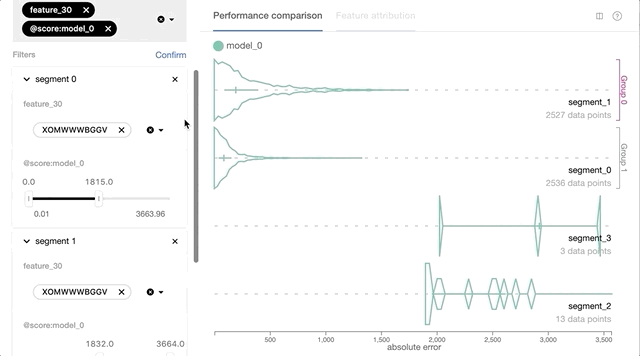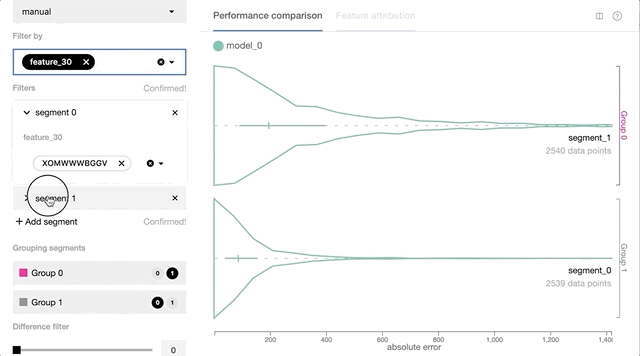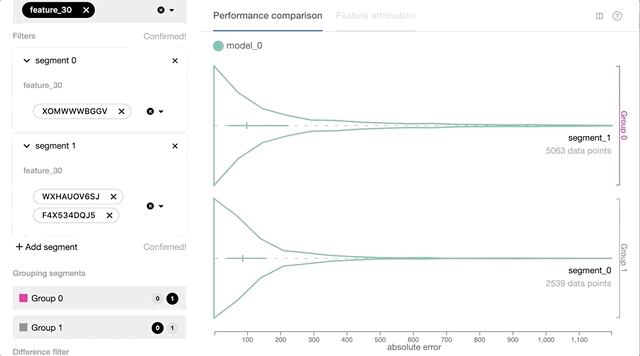
基于每个实例的预测损失和特征值的交互式数据切片使Manifold练习者可以更好地理解ML模型性能问题。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消