ALBERT:用于语言表达自我监督学习的Lite BERT
2019年12月23日 由 KING 发表
736492
0
自BERT问世以来,自然语言的研究已经发展到了一个新的模式,充分利用大量现有文本的参数而不需要数据注释。因此,训练用于自然语言处理的机器学习模型(NLP)无需从零开始。但是,为了进一步完善这种用于NLP的新方法,我们必须找到一种对语言理解性能(网络的高度即层数,网络的宽度隐藏层的大小)的确切表示形式。
在ICLR 2020会议上,谷歌介绍了BERT的升级版 ALBERT:用于语言表示的自我监督学习的精简BERT,它能够提高12项NLP任务的最新性能,ALBERT已在TensorFlow之上开源发布,其中包括许多现成的ALBERT预训练语言表示模型。
什么对NLP性能有贡献?
确定NLP性能的主要驱动因素很复杂,有些设置比其他设置更重要,而且,一次简单地一次尝试不会产生正确的答案。 ALBERT的设计中捕捉到的优化性能的关键是更有效地分配模型的容量。输入级别的嵌入(单词,子标记等)需要学习与上下文无关的内容表示形式。相反,隐藏层嵌入需要将其完善为上下文相关的表示形式。 这是通过对嵌入参数化进行因子分解来实现的,嵌入矩阵在尺寸相对较小(例如128)的输入级嵌入之间进行划分,而隐藏层嵌入则使用较高的维度(如BERT情况下为768,或者更多)。仅凭这一步骤,ALBERT即可将投影块的参数减少80%,而仅以很小的性能下降为代价。
这是通过对嵌入参数化进行因子分解来实现的,嵌入矩阵在尺寸相对较小(例如128)的输入级嵌入之间进行划分,而隐藏层嵌入则使用较高的维度(如BERT情况下为768,或者更多)。仅凭这一步骤,ALBERT即可将投影块的参数减少80%,而仅以很小的性能下降为代价。
ALBERT的另一个关键设计决策源于检查冗余的不同观察。神经网络架构(例如BERT, XLNet和RoBERTa)依赖彼此堆叠的独立层。但是,我们观察到,它们经常学会使用不同参数在各个层执行相似的操作。通过在各层之间进行参数共享,可以消除ALBERT中这种可能的冗余,即同一层相互叠加。这种方法会稍微降低精度,但是更紧凑的尺寸非常值得权衡。通过参数共享,注意力前馈模块的参数减少了90%(总体减少了70%)。
一起实现这两个设计更改,将产生一个基于ALBERT的模型,该模型只有1200万个参数,与基于BERT的模型相比,参数减少了89%,但在所考虑的基准测试中仍可达到可观的性能。但是,此参数大小的减少提供了再次扩大模型的机会。假设内存大小允许,则可以将隐藏层嵌入的大小扩大10到20倍。与BERT大型模型相比,ALBERT-xxlarge配置的隐藏大小为4096,可实现整体参数减少30%,并且更重要的是,可显着提高性能。
这些结果表明准确的语言理解取决于开发健康的、高容量的上下文表示。在隐藏层嵌入中建模的上下文捕获了单词的含义,这反过来又推动了整体理解,这直接由标准基准上的模型性能来衡量。
使用RACE数据集优化模型性能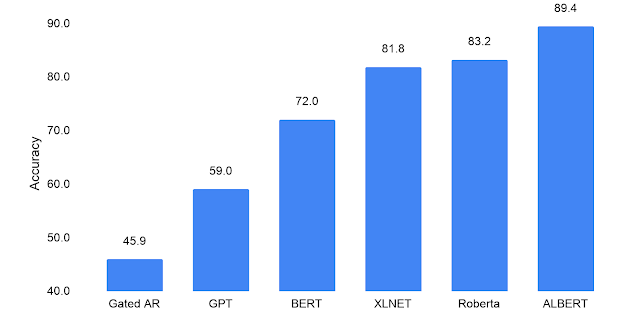
要评估模型的语言理解能力,可以进行阅读理解测试(例如,类似于SAT阅读测试)。这可以通过RACE数据集完成(2017),这是为此目的提供的最大的公开资源。在阅读理解挑战方面的计算机性能很好地反映了过去几年中语言建模的进步:仅通过与上下文无关的单词表示进行预训练的模型在该测试中的评分很低(45.9;最左边的小节),而带有上下文的BERT依赖的语言知识,相对得分为72.0。完善的BERT模型,例如XLNet和RoBERTa,在82-83的分数范围内,将标准设定得更高。当在基础BERT数据集(维基百科和书籍)上进行训练时,上述ALBERT-xxlarge配置产生的RACE得分在相同范围内(82.3)。但是,当在与XLNet和RoBERTa相同的较大数据集上进行训练时,它显着优于迄今所有其他方法,并在89.4时建立了新的最新评分。
ALBERT的成功证明了识别模型的各个方面的重要性,这些模型会产生强大的上下文表示。通过将改进工作集中在模型体系结构的这些方面,可以极大地提高各种NLP任务的模型效率和性能。





























