DeepMind的机器学习模型MuZero是如何学会下棋的
2019年11月22日 由 KING 发表
679595
0
DeepMind在去年年底发表在《科学》杂志上的一篇论文中,详细介绍了AlphaZero,这是一种人工智能系统,可以自学如何掌握国际象棋、日本象棋“将棋”的变体以及中国的围棋。在这些棋种的竞赛中,AlphaZero都成功击败了世界冠军。
但是AlphaZero获胜的前提是它要知道所玩游戏的规则。在追求可控的高性能机器学习模型本身的规则时,DeepMind的研究人员设计了MUZERO,它是一种学习模型,能够预测与游戏决策最相关的数量,从而使其在57种不同的Atari游戏中达到行业领先的性能,并与Go,象棋和将棋中的AlphaZero的性能相匹配。
基于模型的强化学习
从根本上说,MuZero会接收观察结果并将其转换为隐藏状态。该隐藏状态通过接收先前状态和假设的下一个动作的过程进行迭代更新。正如DeepMind研究人员所解释的那样,MuZero是强化学习的一种形式,它是AlphaZero的核心技术,其中的奖励将AI代理带向目标。该表单使用预测下一步的状态转换模型和预测奖励的奖励模型,将给定环境建模为中间步骤。
通常,基于模型的强化学习侧重于直接在像素级别对观察流进行建模,但是这种粒度级别在大规模环境中计算非常昂贵。实际上,没有一种现有的方法可以构建一个模型来促进在Atari等视觉复杂领域中的计划。
训练与实验
DeepMind团队将MuZero应用于经典棋盘游戏Go,国际象棋和将棋作为挑战性计划问题的基准,并应用开源Atari学习环境中的所有57款游戏来作为视觉上复杂的强化学习领域的基准。他们对系统进行了五个假设步骤的训练,并在棋盘游戏中使用了100万个小批训练数据。
关于Go,尽管使用了较少的整体计算,MuZero的性能还是略超过AlphaZero的性能,研究人员说,这证明它可能已经对其位置有了更深入的了解。至于Atari,MuZero在57场比赛中的均值和中位数归一化得分均达到了新的水平,在57场比赛中的42场中表现优于先前的最新方法(R2D2),并且表现优于先前的最佳模型所有游戏中基于方法的方法。
接下来,研究人员评估了MuZero的一个版本-MuZero Reanalyze,该版本已进行了优化,可提高采样效率,并将其应用于75场Atari游戏中,每场游戏总共拥有2亿帧经验。他们报告说,它管理的标准化分数中位数为731%,而之前的最新无模型方法IMPALA,Rainbow和LASER分别为192%,231%和431%,同时所需的培训时间大大减少。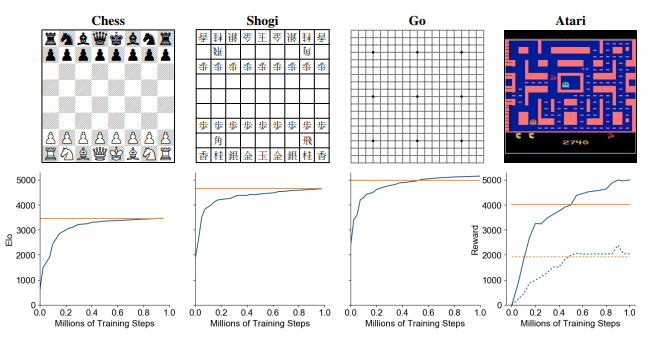 最后,为了更好地了解该模型在MuZero中扮演的角色,团队将重点放在Go和Pac-Man身上。他们将使用完美模型的AlphaZero搜索与使用学习模型的MuZero的搜索性能进行了比较,他们发现MuZero甚至在进行比经过训练的搜索更大的搜索时,也可以匹配完美模型的性能。实际上,每步仅进行6次模拟,少于每次执行的模拟次数,不足以覆盖Pac-Man的所有8种可能的行动。
最后,为了更好地了解该模型在MuZero中扮演的角色,团队将重点放在Go和Pac-Man身上。他们将使用完美模型的AlphaZero搜索与使用学习模型的MuZero的搜索性能进行了比较,他们发现MuZero甚至在进行比经过训练的搜索更大的搜索时,也可以匹配完美模型的性能。实际上,每步仅进行6次模拟,少于每次执行的模拟次数,不足以覆盖Pac-Man的所有8种可能的行动。
研究人员说,MuZero为许多实际领域中的学习方法铺平了道路,尤其是那些缺乏交流规则或环境动态性模拟器的领域。





























