











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用 Streamlit 构建机器学习应用
2019年11月09日 由 sunlei 发表
40647
0
Streamlit是一个开放源码的Python库,它可以轻松地为机器学习构建漂亮的应用程序。你可以很容易地通过pip在你的终端上安装它,然后开始用Python编写你的web应用程序。
在本文中,我将展示关于Streamlit的一些有趣特性,构建一个应用程序来检查数据并在其上构建ML模型。为此,我将使用非常基本的Iris数据集并对其执行一些分类。但是,如果您对这个工具的高级功能感兴趣,我建议您阅读本教程。
说到这里,让我们开始构建我们的应用程序。我将在一个名为iris.py的文件中编写所有代码,这样我就可以通过streamlit iris.py从终端运行它。
最后,我的应用程序的完整代码如下:
现在,让我们检查每一段代码。首先,一旦导入了所需的包,我想设置我的应用程序的标题并导入我的数据:
现在我想要第一个选项,允许用户决定是否显示整个数据集。我可以使用以下语法来完成此操作(以及许多其他交互小部件):
尽管很幼稚,但我们已经可以启动baby应用程序,并在localhost:8501上看到结果:
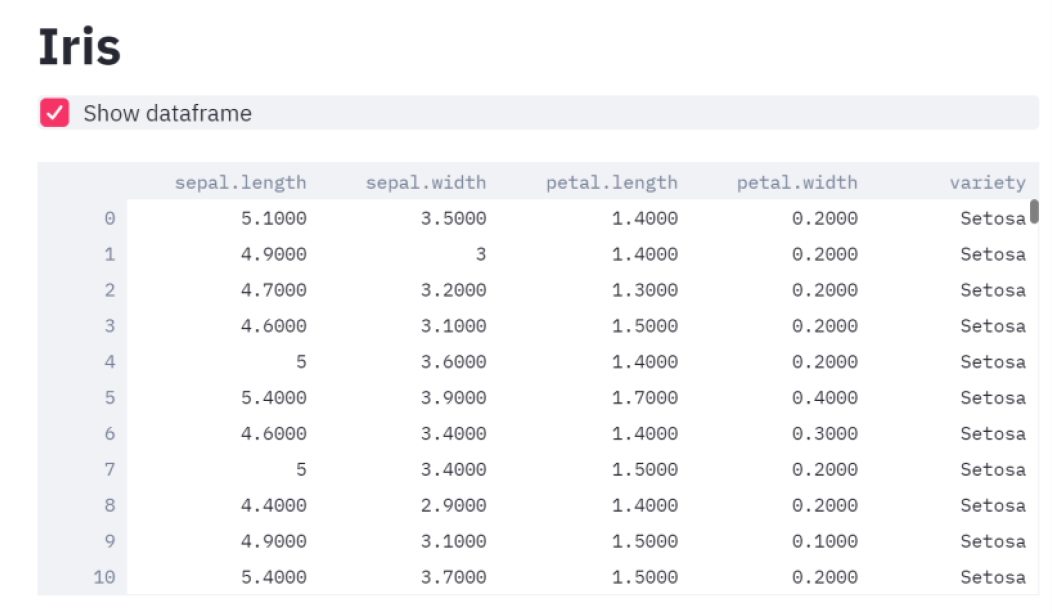
正如您所看到的,我决定显示我的数据集,但是,在任何时候,我都可以通过取消复选框来隐藏它。
现在让我们转向一些可视化工具。假设我想对数据进行散点绘图,可以选择我感兴趣的特性和标签。
正如你所看到的,在这个例子中,我选择了Versicolor和Virginica作为物种,它们的特征是萼片的长度和宽度,但我能够随时更改它们,并实时更新我的所有图表。
现在,我想用同样的逻辑,添加一个直方图来显示任何特性的分布此外,我想有可能绘制每个特征的3个条件分布,相对于之前选择的变化。因此:
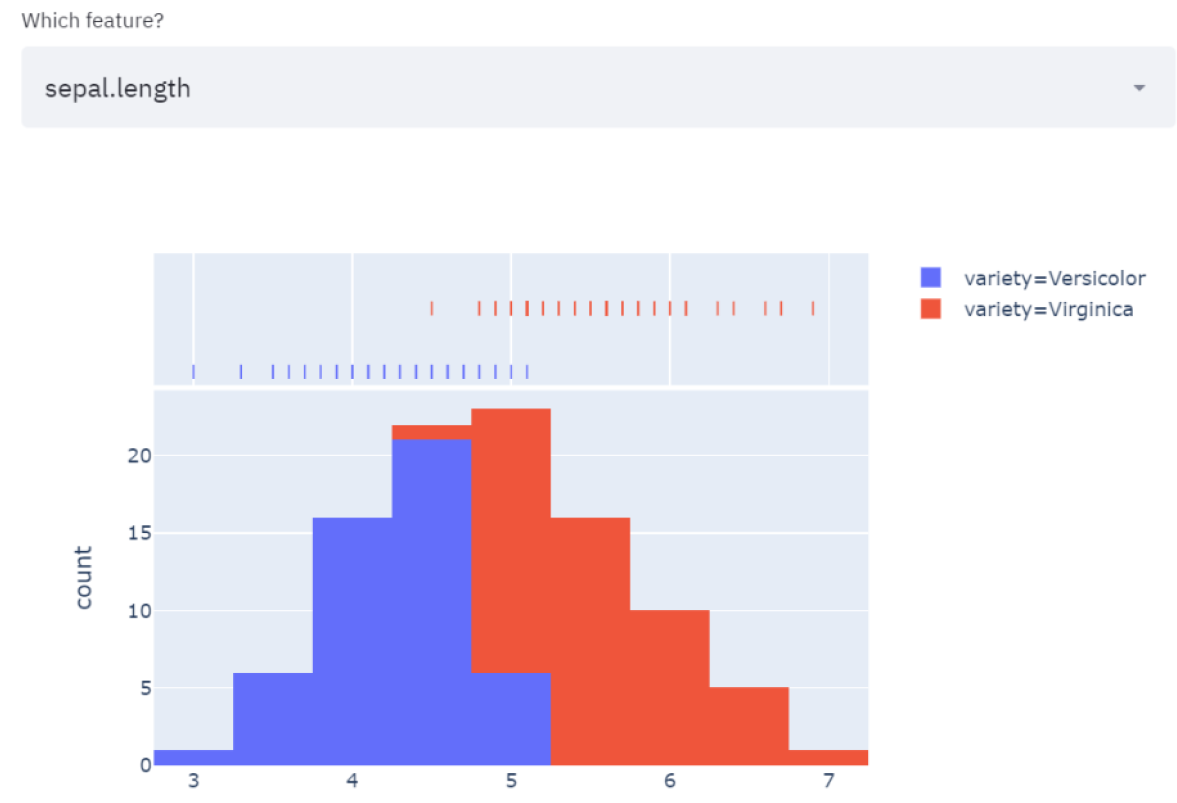 这两个物种和我上面选择的一样,同样,我可以随时改变它们。
这两个物种和我上面选择的一样,同样,我可以随时改变它们。
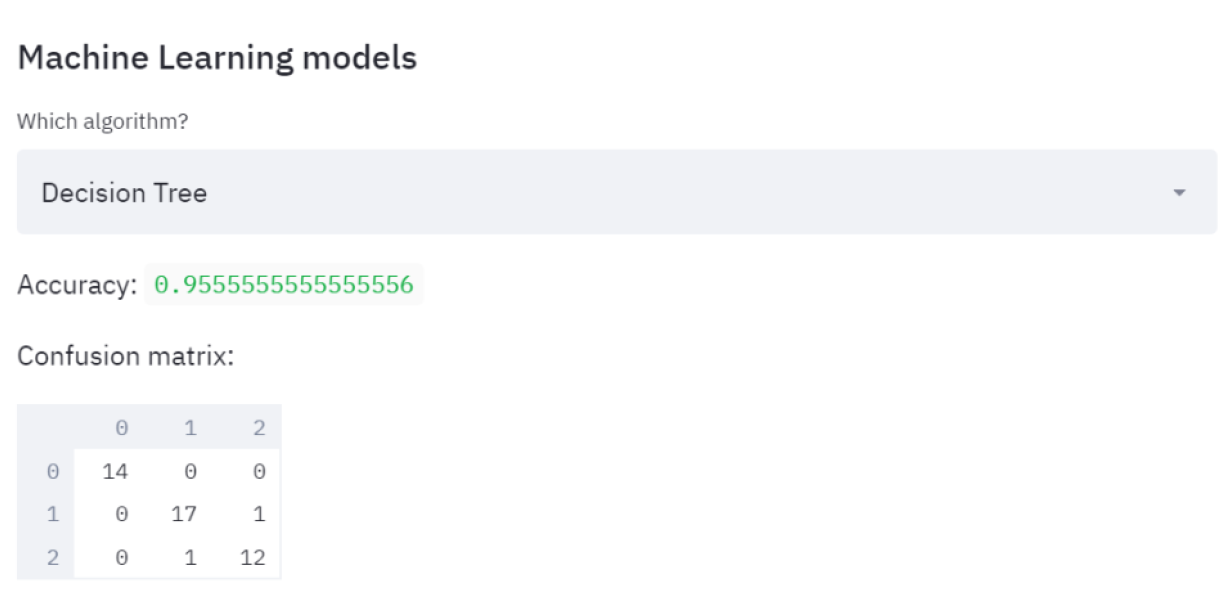
现在让我们进入最后一部分,即训练实时ML算法并让用户决定应用哪个算法。为此,我将在支持向量机和决策树这两种分类算法之间进行选择。对于每一个,我都会要求我的app打印准确率(正确分类的数量/观察总数)和混淆矩阵:
那么,如果我选择SVM:
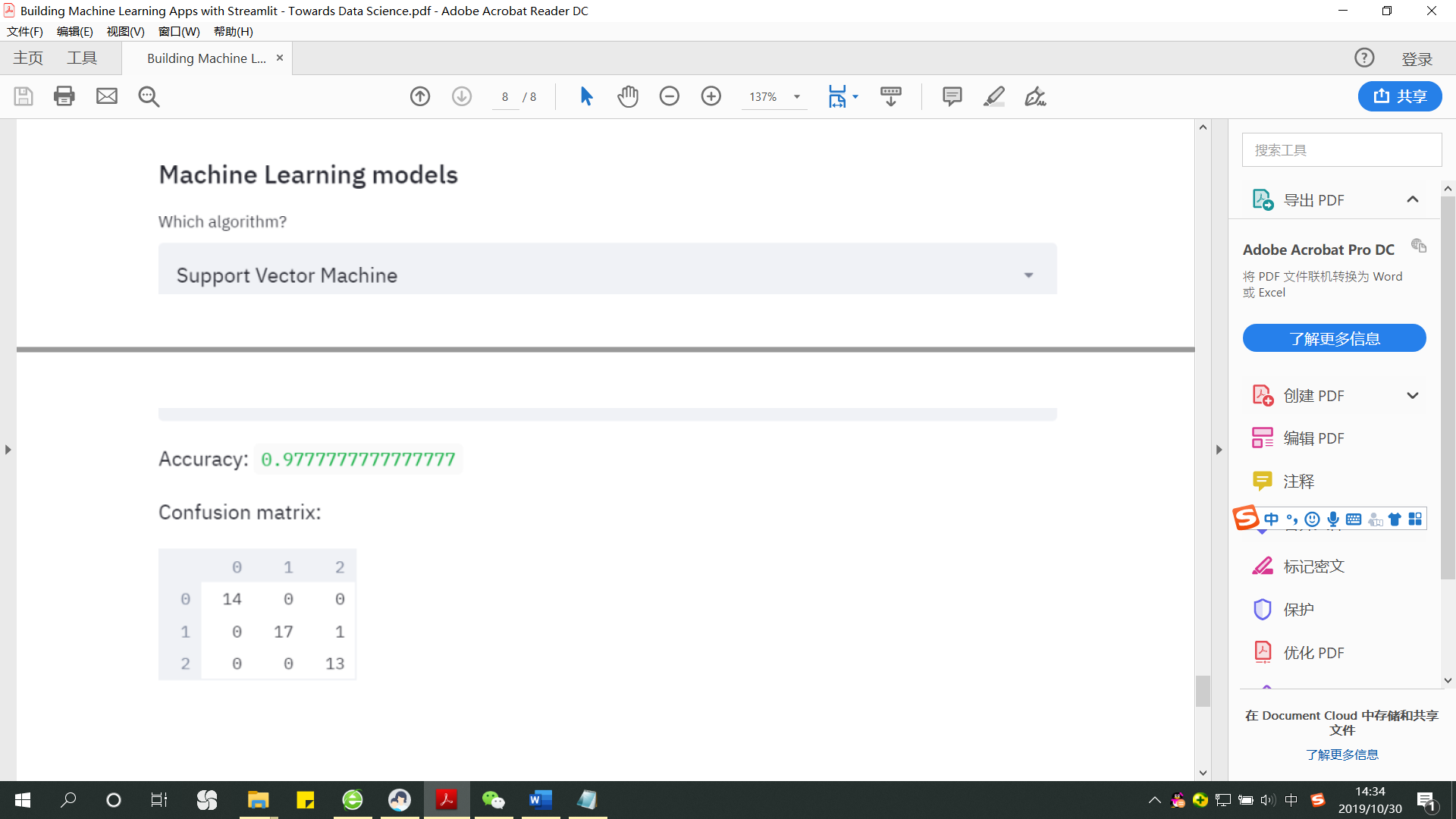
所以我们能够立即比较两个分类器的性能,以一种非常友好的方式。
Streamlit是一个非常强大的工具,尤其是当您希望提供一种交互式方式来理解您的分析结果时更是如此:它允许对数据进行实时可视化,并允许对数据进行过滤,还允许有意义的表示。
在这里,我向您展示了您可以使用Streamlit实现的非常基本的实现,因此,如果您想更深入地研究这个工具,我建议您阅读参考资料中的进一步阅读资料。
参考文献:
https://streamlit.io/docs/
https://streamlit.io/docs/tutorial/index.html
原文链接:https://towardsdatascience.com/building-machine-learning-apps-with-streamlit-667cef3ff509
在本文中,我将展示关于Streamlit的一些有趣特性,构建一个应用程序来检查数据并在其上构建ML模型。为此,我将使用非常基本的Iris数据集并对其执行一些分类。但是,如果您对这个工具的高级功能感兴趣,我建议您阅读本教程。
说到这里,让我们开始构建我们的应用程序。我将在一个名为iris.py的文件中编写所有代码,这样我就可以通过streamlit iris.py从终端运行它。
最后,我的应用程序的完整代码如下:
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.graph_objects as gost.title('Iris')df = pd.read_csv("iris.csv")if st.checkbox('Show dataframe'):
st.write(df)st.subheader('Scatter plot')species = st.multiselect('Show iris per variety?', df['variety'].unique())
col1 = st.selectbox('Which feature on x?', df.columns[0:4])
col2 = st.selectbox('Which feature on y?', df.columns[0:4])new_df = df[(df['variety'].isin(species))]
st.write(new_df)
# create figure using plotly express
fig = px.scatter(new_df, x =col1,y=col2, color='variety')
# Plot!st.plotly_chart(fig)st.subheader('Histogram')feature = st.selectbox('Which feature?', df.columns[0:4])
# Filter dataframe
new_df2 = df[(df['variety'].isin(species))][feature]
fig2 = px.histogram(new_df, x=feature, color="variety", marginal="rug")
st.plotly_chart(fig2)st.subheader('Machine Learning models')from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
from sklearn.svm import SVCfeatures= df[['sepal.length', 'sepal.width', 'petal.length', 'petal.width']].values
labels = df['variety'].valuesX_train,X_test, y_train, y_test = train_test_split(features, labels, train_size=0.7, random_state=1)alg = ['Decision Tree', 'Support Vector Machine']
classifier = st.selectbox('Which algorithm?', alg)
if classifier=='Decision Tree':
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
acc = dtc.score(X_test, y_test)
st.write('Accuracy: ', acc)
pred_dtc = dtc.predict(X_test)
cm_dtc=confusion_matrix(y_test,pred_dtc)
st.write('Confusion matrix: ', cm_dtc)elif classifier == 'Support Vector Machine':
svm=SVC()
svm.fit(X_train, y_train)
acc = svm.score(X_test, y_test)
st.write('Accuracy: ', acc)
pred_svm = svm.predict(X_test)
cm=confusion_matrix(y_test,pred_svm)
st.write('Confusion matrix: ', cm)
现在,让我们检查每一段代码。首先,一旦导入了所需的包,我想设置我的应用程序的标题并导入我的数据:
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.graph_objects as go
st.title('Iris')
df = pd.read_csv("iris.csv")
现在我想要第一个选项,允许用户决定是否显示整个数据集。我可以使用以下语法来完成此操作(以及许多其他交互小部件):
if st.checkbox('Show dataframe'):
st.write(df)尽管很幼稚,但我们已经可以启动baby应用程序,并在localhost:8501上看到结果:
正如您所看到的,我决定显示我的数据集,但是,在任何时候,我都可以通过取消复选框来隐藏它。
现在让我们转向一些可视化工具。假设我想对数据进行散点绘图,可以选择我感兴趣的特性和标签。
species = st.multiselect('Show iris per variety?',
df['variety'].unique())
col1 = st.selectbox('Which feature on x?', df.columns[0:4])
col2 = st.selectbox('Which feature on y?', df.columns[0:4])
new_df = df[(df['variety'].isin(species))]
st.write(new_df)
fig = px.scatter(new_df, x =col1,y=col2, color='variety')
st.plotly_chart(fig)
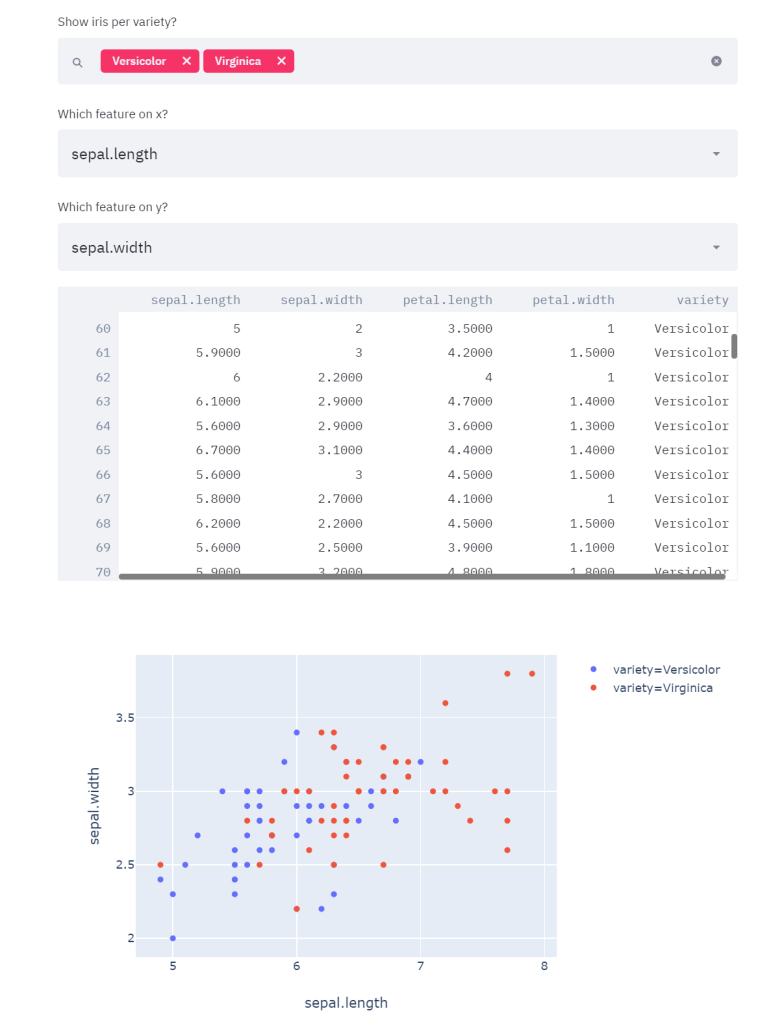
正如你所看到的,在这个例子中,我选择了Versicolor和Virginica作为物种,它们的特征是萼片的长度和宽度,但我能够随时更改它们,并实时更新我的所有图表。
现在,我想用同样的逻辑,添加一个直方图来显示任何特性的分布此外,我想有可能绘制每个特征的3个条件分布,相对于之前选择的变化。因此:
feature = st.selectbox('Which feature?', df.columns[0:4])
# Filter dataframe
new_df2 = df[(df['variety'].isin(species))][feature]
fig2 = px.histogram(new_df, x=feature, color="variety",
marginal="rug")
st.plotly_chart(fig2)这两个物种和我上面选择的一样,同样,我可以随时改变它们。现在让我们进入最后一部分,即训练实时ML算法并让用户决定应用哪个算法。为此,我将在支持向量机和决策树这两种分类算法之间进行选择。对于每一个,我都会要求我的app打印准确率(正确分类的数量/观察总数)和混淆矩阵:
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
from sklearn.svm import SVCfeatures= df[['sepal.length', 'sepal.width', 'petal.length', 'petal.width']].values
labels = df['variety'].valuesX_train,X_test, y_train, y_test = train_test_split(features, labels, train_size=0.7, random_state=1)alg = ['Decision Tree', 'Support Vector Machine']
classifier = st.selectbox('Which algorithm?', alg)
if classifier=='Decision Tree':
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
acc = dtc.score(X_test, y_test)
st.write('Accuracy: ', acc)
pred_dtc = dtc.predict(X_test)
cm_dtc=confusion_matrix(y_test,pred_dtc)
st.write('Confusion matrix: ', cm_dtc)elif classifier == 'Support Vector Machine':
svm=SVC()
svm.fit(X_train, y_train)
acc = svm.score(X_test, y_test)
st.write('Accuracy: ', acc)
pred_svm = svm.predict(X_test)
cm=confusion_matrix(y_test,pred_svm)
st.write('Confusion matrix: ', cm)
那么,如果我选择SVM:
所以我们能够立即比较两个分类器的性能,以一种非常友好的方式。
Streamlit是一个非常强大的工具,尤其是当您希望提供一种交互式方式来理解您的分析结果时更是如此:它允许对数据进行实时可视化,并允许对数据进行过滤,还允许有意义的表示。
在这里,我向您展示了您可以使用Streamlit实现的非常基本的实现,因此,如果您想更深入地研究这个工具,我建议您阅读参考资料中的进一步阅读资料。
参考文献:
https://streamlit.io/docs/
https://streamlit.io/docs/tutorial/index.html
原文链接:https://towardsdatascience.com/building-machine-learning-apps-with-streamlit-667cef3ff509

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消