











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Facebook AI推出新模型RoBERTa,改进BERT的预训练方法
2019年07月30日 由 Aaron 发表
914738
0
 Facebook AI和华盛顿大学的研究人员设计了一些方法来增强谷歌的BERT语言模型,并在GLUE,SQuAD和RACE基准数据集中实现最先进的性能。BERT超过Google Brain的XLNet,又一次成为最强的NLP预训练模型。
Facebook AI和华盛顿大学的研究人员设计了一些方法来增强谷歌的BERT语言模型,并在GLUE,SQuAD和RACE基准数据集中实现最先进的性能。BERT超过Google Brain的XLNet,又一次成为最强的NLP预训练模型。该模型被命名为RoBERTa,用于“Robustly Optimized BERT”方法,采用了许多来自transformer (BERT)的双向编码器表示所使用的技术。
RoBERTa的不同之处在于,它依赖于训练前的大量数据和训练数据掩蔽模式的改变。
在训练前,原始的BERT使用了掩蔽语言建模和下一句话预测,但是RoBERTa放弃了下一句话预测的方法。
总的来说,RoBERTa在9个GLUE基准任务中的4个实现了最先进的结果,并且拥有与XLNet相当的整体GLUE任务性能。
团队表示,“我们发现BERT明显缺乏训练,其表现可以与之后发布的每一个模型媲美,甚至超过后者。我们的训练改进表明,在正确的设计选择下,掩蔽语言模型预培训与所有其他最近发布的方法具有竞争力。”
为了制作RoBERTa,研究人员用1024个Nvidia V100 GPU训练大约一天。
最初的BERT使用16GB BookCorpus数据集和英语维基百科进行训练,但RoBERTa使用了 CommonCrawl (CC)-News,这是一个76GB的数据集,包含了在2016年9月到2019年2月期间获得的6300万篇英文新闻文章。
最后,团队对RoBERTa进行了较长时间的预训练,将预训练步骤从10万步增加到30万步,然后进一步增加到50万步。
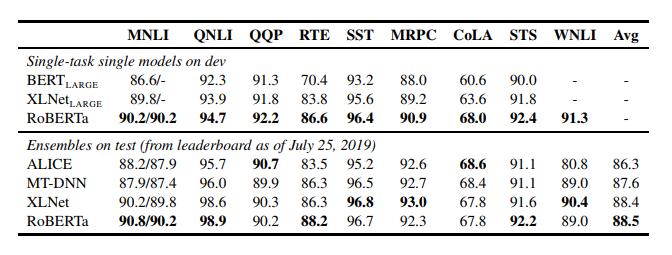 报告称,下游任务性能显著提高,300K和500K 步模型在大多数任务中都优于XLNet。
报告称,下游任务性能显著提高,300K和500K 步模型在大多数任务中都优于XLNet。RoBERTa的推出延续了大规模语言理解人工智能系统OpenAI的GPT-2,Google Brain的XLNet和微软的MT-DNN,它们在基准性能结果上都超过了BERT。不过,训练此类模型的成本可能非常昂贵,并且会产生相当大的碳足迹。
论文:
arxiv.org/abs/1907.11692

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消