











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源地标识别数据集,含500万张图片和20万个地标
2019年05月05日 由 马什么梅 发表
365674
0
 去年,谷歌开源了Google-Landmarks,这是当时世界上最大的地标数据集,并举办了两场挑战赛,有500多名机器学习研究人员参加。
去年,谷歌开源了Google-Landmarks,这是当时世界上最大的地标数据集,并举办了两场挑战赛,有500多名机器学习研究人员参加。对于谷歌AI研究部门来说,一直希望能够设计这样的AI系统:能够进行精确实例级地标识别,如将尼亚加拉大瀑布与其他瀑布区分开来,以及能够检索图像,即将图像中的对象与目录中该对象的其他实例匹配。
今天,谷歌开源的Google-Landmarks-v2,一个新的、更大的地标识别数据集,比原来多出两倍的照片和七倍的地标,这意味着谷歌朝着更复杂的地标检测计算机视觉模型迈出了重要的一步。
此外,它还在其机器学习社区Kaggle上推出了两项新的挑战赛(Landmark Recognition 2019和Landmark Retrieval 2019),并发布了Detect-to-Retrieve的源代码和模型,一个区域图像检索框架。
谷歌AI软件工程师Bingyi Cao和Tobias Weyand写道:“实例识别和图像检索方法都需要更大的数据集,包括图像数量和各种标志,以便训练更好,更强大的系统。我们希望这个数据集能够帮助推进实例识别和图像检索方面的最新技术。”
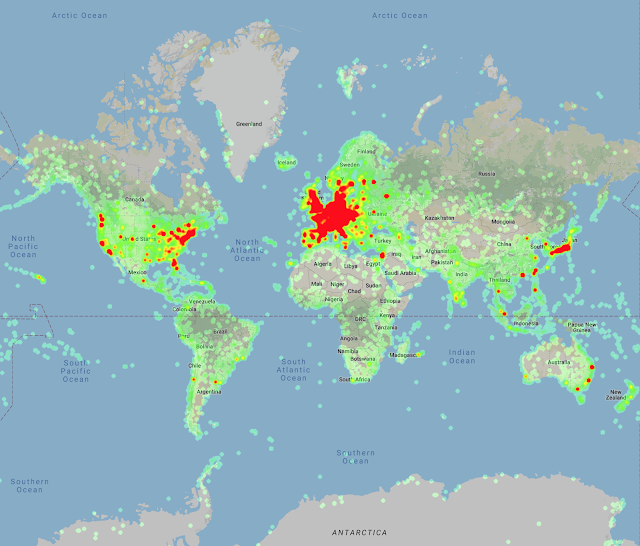
Google-Landmarks-v2包含了超过500万张来自世界各地摄影师收集的20多万个不同地标的图像。包括新天鹅堡,金门大桥,清水寺,哈利法塔,吉萨大狮身人面像,马丘比丘和其他著名景点,他们标记并提交了它们。
之后,谷歌研究人员用Wikimedia Commons的免费图像,声音和其他媒体的在线存储库进行了补充。
模型由原始地标数据集中的80000个子集进行训练,利用来自物体检测模型的边界框为感兴趣的项目的图像区域提供额外的权重,显著提高了准确性。
关于挑战赛,2019年的地标识别竞赛是让参赛者设计地标探测人工智能模型,而2019年的地标检索竞赛是让竞争者使用人工智能系统来寻找显示目标地标的图像,两个比赛都包括总额为50000美元的现金奖励。
数据集:
github.com/cvdfoundation/google-landmark
挑战赛:
www.kaggle.com/c/landmark-retrieval-2019
www.kaggle.com/c/landmark-recognition-2019

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消