











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






基础术语大词典:强化学习相关术语速查
2019年03月09日 由 深深深海 发表
817777
0
 每当开始学习一个不熟悉的主题时,最难应对的是它的新术语。每个领域都有许多术语和定义,这些术语和定义对于非专业人士来说是完全模糊的,并且可能使入门非常困难,而这就是这个词典的来由。
每当开始学习一个不熟悉的主题时,最难应对的是它的新术语。每个领域都有许多术语和定义,这些术语和定义对于非专业人士来说是完全模糊的,并且可能使入门非常困难,而这就是这个词典的来由。A
Action-Value Function(动作值函数):参见Q-Value。
Actions:行为使智能体与环境交互并改变其环境,从而在状态之间进行迁移。智能体执行的每个行为都会从环境中获得奖励。决定采取哪种行为是由策略决定的。
Actor-Critic:当试图解决强化学习问题时,有两种主要方法可供选择:计算每个状态的值函数或Q值并根据这些值选择行为,或者直接计算一个策略,该策略定义了根据当前状态应该采取的每个操作的概率,并根据该策略进行操作。Actor-Critic算法结合了这两种方法,是更具鲁棒性的方法。
Advantage Function(优势函数):通常表示为A(s,a),它衡量的是在给定某种状态下某个行为是好是坏,或者更简单地说,从某种状态中选择某个行为的优势是什么。它的数学定义是:
其中r(s,a)是来自状态s的动作a的预期奖励,r(s)是在选择动作之前整个状态s的预期奖励。它也可以被视为:
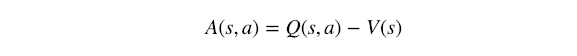
其中Q(s,a)是Q值,V(s)是Value函数。
Agent(智能体):强化学习问题的学习和行为部分,试图最大化环境给予的奖励。简单来说,智能体就是你尝试设计的模型。
B
Bandits:k-Armed Bandits,被认为是最简单的强化学习任务。Bandits没有不同的状态,只有一个,而且所考虑的报酬只是眼前的。因此,Bandits可以被认为是单一状态事件。每个k臂被认为是一个动作,目的是学习在每个动作(或手臂拉动)后最大化预期奖励的策略。
Contextual Bandits是一个稍微复杂的任务,每个状态可能不同并影响行为的结果,因此每次上下文都不同。尽管如此,任务仍然是一个单一状态的事件性任务,一个上下文不会对其他产生影响。
Bellman Equation(贝尔曼方程):贝尔曼方程定义了给定状态(或状态-行为对)与其后继者之间的关系。虽然存在许多形式,但在强化学习任务中通常遇到的最常见的是最佳Q值的贝尔曼方程:
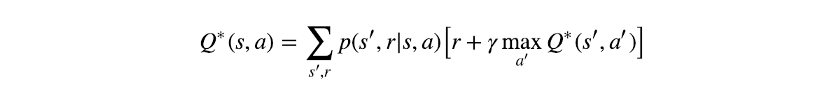
或者当不存在不确定性时(即概率为1或0):
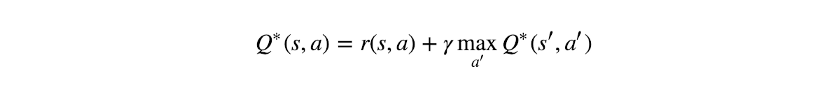
星号表示最佳值。一些算法,例如Q-Learning,是基于它的学习过程。
C
Continuous Tasks(连续任务):强化学习任务不是由系列组成,而是永远连续的。此任务没有终止状态。为简单起见,通常假设它们是由一个永无止境的系列组成。
D
Deep Q-Networks(DQN):请参阅Q-Learning
Deep Reinforcement Learning(深度强化学习):使用强化学习算法和深度神经网络作为学习部分的近似值。这样做通常是为了处理可能的状态和动作的数量迅速增加,而精确的解决方案不再可行的问题。
Discount Factor (γ):贴现因子,通常表示为γ,是乘以未来预期奖励的因子,并且在[0,1]的范围内变化。它控制着未来奖励与直接奖励的重要性。贴现因子越低,未来奖励越不重要,智能体将倾向于专注于仅产生即时奖励的行动。
E
Environment(环境):除去智能体的一切;智能体可以与之直接或间接交互的所有内容。智能体执行操作时环境会发生变化;每一次这样的改变都被认为是一种状态转变。智能体执行的每个行为都会产生由智能体收到的奖励。
Episode(片段):介于起始状态和终止状态之间的所有状态,例如,一场国际象棋比赛。智能体的目标是使它在某一集中获得的总报酬最大化。在没有终结状态的情况下,我们考虑无限片段。重要的是要记住不同的片段是完全独立的。
Episodic Tasks(片段任务):强化学习任务由不同片段组成(每个片段都有一个终止状态)。
Expected Return(预期回报):有时被称为“总体奖励”,偶尔也表示为G,是整个片段的预期回报。
Experience Replay(经验回放):由于强化学习任务没有可以从中学习的预先生成的训练集,因此智能体必须保存它遇到的所有状态转换的记录,以便以后可以从中学习。用于存储此数据的内存缓冲区通常称为经验回放。这些内存缓冲区有几种类型和体系结构,但是一些非常常见的是循环内存缓冲区(这可以确保代理继续对其新行为进行训练而不是那些可能不再相关的内容),以及库存采样基于内存的缓冲区(保证记录的每个状态转换具有偶数概率插入缓冲区)。
Exploitation & Exploration(利用与探索):强化学习任务没有预先生成的训练集,它们可以从中学习,创造自己的经验并“即时”学习。为了能够这样做,智能体需要在许多不同的状态下尝试许多不同的行为,以尝试和学习所有可能性并找到最大化其总体奖励的路径,这被称为探索,因为智能体探索环境。
另一方面,如果所有的智能体都会进行探索,那么它永远不会最大化整体奖励,它还必须利用它所学到的信息来做到这一点。这被称为利用,因为智能体利用其知识来最大化其收到的奖励。
两者之间的权衡是强化学习问题的最大挑战之一,因为两者必须平衡,以便让智能体既能充分探索环境,又能利用它学到的东西,重复最有价值的途径。
Greedy Policy, ε-Greedy Policy(贪婪策略):贪婪策略意味着智能体不断执行被认为会产生最高预期回报的行为。显然,这样的策略将不允许智能体进行探索。为了仍然允许一些探索,通常使用ε-Greedy Policy:选择[0,1]范围内的数字(命名为ε),并在选择行为之前,一个随机数在[0,1]被选中。如果该数字大于ε,则选择贪婪行为,但如果小于ε,则选择随机行为。注意,如果ε= 0,策略变为贪婪策略,如果ε = 1,则始终探索。
K
k-Armed Bandits:见Bandits。
M
Markov Decision Process;MDP(马尔可夫决策过程):马尔可夫属性意味着每个状态仅依赖于其先前的状态,从该状态采取的选定行为,以及在该行为执行后立即收到的奖励。在数学上,它意味着:s'= s'(s,a,r),其中s'是未来状态,s是其先前状态,a和r是行为和奖励。马尔可夫决策过程是基于这些假设的决策过程。不需要事先知道在s之前发生了什么,马尔可夫属性假设s包含所有相关的信息。马尔可夫决策过程就是基于这些假设的决策过程。
Model-Based & Model-Free:这是智能体在尝试优化其策略时可以选择的两种不同方法。用一个例子来解释:假设你正在尝试学习如何玩二十一点。你可以用两种方式做到这一点:一,你在游戏开始之前提前计算,所有状态的获胜概率以及给定所有可能行为的所有状态转移概率,然后根据你的计算行事。二,在没有任何先验知识的情况下简单地进行游戏,并使用“反复试验”获取信息。请注意,使用第一种方法,你基本上是在建模环境,而第二种方法不需要有关环境的信息,这正是它们之间的区别。
Monte Carlo;MC:该方法是使用重复随机采样以获得结果的算法。它们经常在强化学习算法中使用以获得预期值,例如通过一遍又一遍地返回相同的状态来计算状态值函数,并对每次接收的实际累积奖励求平均值。
O
On-Policy和Off-Policy:每个强化学习算法必须遵循一些策略,以决定在每个状态执行哪些操作。尽管如此,算法的学习过程在学习时并不需要考虑该策略。关注产生过去状态行为决策的策略的算法称为on-policy算法,而忽略它的算法称为off-policy算法。众所周知的off-policy算法是Q-Learning,因为其更新规则使用将产生最高Q值的行为,虽然使用的实际策略可能会限制该行为或选择另一个。Q-Learning的On-Policy的变体为Sarsa,更新规则使用后续策略选择的行为。
One-Armed Bandits:见Bandits。
One-Step TD:见Temporal Difference。
P
Policy (π):该策略表示为π(或有时π(A | S)),是某个状态s到给定状态下选择每个可能动作的概率的映射。例如,Greedy策略为每个状态输出期望q值最高的动作。
Q
Q-Learning: Q-Learning是一种非策略强化学习算法,被认为是最基本的算法之一。在其最简化的形式中,它使用表来存储所有可能的状态-行为对的所有Q值。它使用贝尔曼方程更新此表,而行为选择通常使用ε-贪婪策略。最简单的形式(状态转换和预期奖励没有不确定性),Q-Learning的更新规则是:
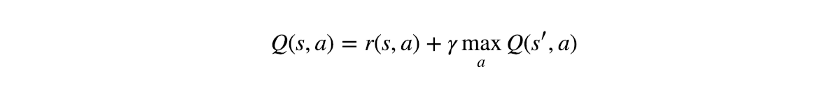
其更受欢迎且更复杂的版本,是深度Q网络变体(有时简称为深度Q学习或仅为Q-Learning)。此变体将状态-行为表替换为神经网络,以便处理大规模任务,其中可能的状态-行为对的数量可能是巨大的。
Q Value(Q Function)Q值(Q函数):通常表示为Q(s,a)(有时在深度RL中具有π下标,有时为Q(s,a;θ)),Q值是衡量总体期望的奖励假设智能体状态和执行行为,然后继续玩到最后带来一些策略π。它的名字是质量这个词的缩写,它的数学定义是:
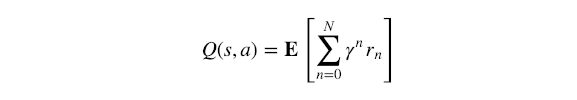
其中N是从状态s到终止状态的状态数,γ是折扣因子,r⁰是在状态s中执行行为a后得到的直接奖励。
R
REINFORCE算法:REINFORCE算法是一系列强化学习算法,它根据策略参数相对于策略参数的梯度来更新策略参数。名称通常只使用大写字母,因为它最初是原始算法组设计的首字母缩写:奖励增量=非负因子x抵消强化x特征资格。
Reinforcement Learning(强化学习):强化学习,如监督学习和无监督学习,是机器学习和人工智能的主要领域之一。它关注的是一个任意存在的学习过程,正式名称为智能体,在它周围的世界是环境。智能体寻求从环境中获得的奖励最大化,并执行不同的操作以了解环境如何响应并获得更多奖励。强化学习任务的最大挑战之一是将行动与推迟的奖励相关联,在产生奖励行为之后很久才会给智能体。因此,它被用于解决各种类型的游戏,从Tic-Tac-Toe,Chess,Atari 2600,Go和星际争霸。
Reward(奖励):智能体从环境接收的数值,作为对智能体操作的直接响应。智能体的目标是最大化其在剧集中收到的总体奖励,因此奖励是智能体为了按照期望的行为行事所需的动机。所有行为都会产生奖励,大致可以分为三种类型:强调所需行为的积极奖励,强调智能体应该离开的行动的负奖励,以及零奖励,这意味着智能体没有做任何特别或独特的事情。
S
Sarsa:Sarsa算法差不多就是Q-Learning算法,只是为了使它成为一种on-policy算法而做了一些修改。Q-Learning更新规则基于最佳Q值的贝尔曼方程,因此在状态转换和预期奖励没有不确定性的情况下,Q-Learning更新规则是:
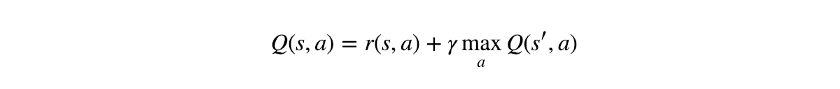
为了将其转换为on-policy算法,修改了最后一个术语:
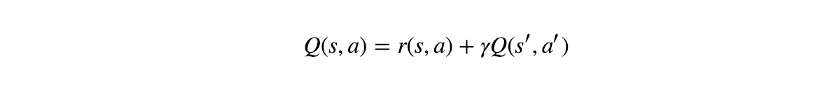
此时,行为a和a'都是由同一策略选择的。算法的名称源自其更新规则,该规则基于(s,a,r,s',a'),所有这些都来自同一策略。
State(状态):智能体在环境中遇到的每个场景都被正式称为状态。智能体通过执行操作在不同状态之间转换。值得一提的是终止状态,标志着片段的结束。在达到终止状态后,从新的片段开始。通常,终止状态表示为特殊状态,其中所有行为都转换到具有零奖励的终止状态。
State-Value Function(状态值函数):参见Value Function。
T
Temporal-Difference(时序差分算法):时序差分算法是一种结合动态规划和蒙特卡罗原理的学习方法;它与蒙特卡洛类似地进行“学习”,但像动态规划一样更新其估计值。一个最简单的时间差分算法,它被称为一步TD或TD(0)。它根据以下更新规则更新值函数:
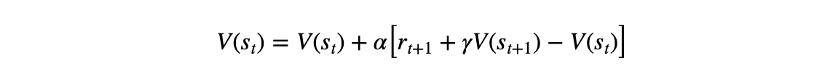
其中V是值函数,s是状态,r是奖励,γ是折扣因子,α是学习率,t是时间步长,'='符号用作更新算子而不是等式。方括号中的术语称为时间差分误差。
Terminal State(终止状态):见State。
U
Upper Confident Bound(UCB): UCB是一种探索方法,它试图确保每个动作都得到很好的探索。考虑一个完全随机的探索策略,这意味着每个可能的行动都有被选中的机会。某些行动有可能比其他行动更多地被探索。选择的行动越少,智能体对其预期奖励的信心就越小,其利用阶段可能会受到损害。UCB的探索考虑了每个动作被选中的次数,并为那些探索较少的动作提供额外的权重。通过数学方式对其进行形式化,选择的操作可以通过以下方式选择:
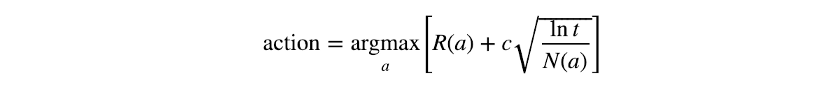
其中R(a)是行为a的预期总体奖励,t是所采取的步数(总共选择了多少动作),N(a)是行为a被选择的次数,c是可配置的超参数。这种方法有时也被称为“乐观探索”,因为它为较少探索的行为提供了更高的价值,鼓励模型选择它们。
V
Value Function(值函数):通常表示为V(s)(有时带有π下标),值函数是假设代理处于状态 s然后继续播放直到事件结束后某个策略π的整体预期奖励的度量。它在数学上定义为:
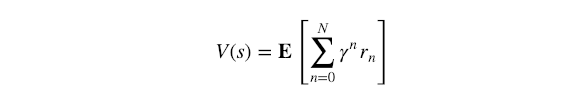
虽然它确实看起来与Q值的定义相似,但存在一个隐含的但很重要的区别:对于n = 0,V(s)的奖励r⁰是来自状态s的预期奖励,在任何行动之前在Q值中,r⁰是在某个行为后的预期奖励。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
K近邻算法KNN的简述
下一篇
logistic回归的详细概述








广告


写评论取消
回复取消