











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源PlaNet,一个通过图像了解世界的强化学习技术
2019年02月18日 由 浅浅 发表
164334
0
 通过强化学习,研究AI如何随着时间的推移提高决策能力的研究进展迅速。对于这种技术,智能体在选择动作(如运动命令)时观察一系列感官输入(如相机图像),有时会因为达到指定目标而获得奖励。
通过强化学习,研究AI如何随着时间的推移提高决策能力的研究进展迅速。对于这种技术,智能体在选择动作(如运动命令)时观察一系列感官输入(如相机图像),有时会因为达到指定目标而获得奖励。强化学习的无模型方法旨在直接从感官观察中预测良好的行为,使DeepMind的DQN能够通过Atari和其他智能体来控制机器人。然而,这种黑盒方法通常需要经过数周的模拟交互才能通过反复试验来学习,这限制了它在实践中的有效性。
相反,基于模型的强化学习试图让智能体了解世界的一般行为。这不是直接将观察映射到行动,而是允许智能体明确地提前计划,通过“想象”长期结果来更仔细地选择行动。
基于模型的方法已经取得了实质性的成功,包括AlphaGo,它想象用已知的游戏规则在虚拟板上进行移动序列。但是,要利用未知的计划环境(例如控制仅给出像素作为输入的机器人),智能体必须从经验中学习规则或动态。因为这种动态模型原则上允许更高的效率和自然的多任务学习,所以创建足够准确的模型以成功规划是强化学习的长期目标。
为了促进这项研究挑战的进展并与DeepMind合作,团队提出了深度规划网络(PlaNet)智能体,仅从图像输入中学习世界模型,并成功利用它进行规划。PlaNet解决了各种基于图像的控制任务,在最终性能方面与先进的无模型智能体竞争,平均数据效率提高了5000%。团队还发布了源代码以供社区使用。
PlaNet的工作原理
简而言之,PlaNet学习了给定图像输入的动力学模型,并有效地利用该模型进行规划,以收集新的经验。与以前的图像规划方法不同,我们依赖于隐藏或潜在状态的紧凑序列。这被称为潜伏期动力学模型:不是直接从一个图像到下一个图像预测,而是预测未来的潜伏期状态。然后从相应的潜在状态生成每一步的图像和奖励。
通过这种方式压缩图像,智能体可以自动学习更抽象的表征,比如物体的位置和速度,这样就可以更容易地向前预测,而不需要在过程中生成图像。
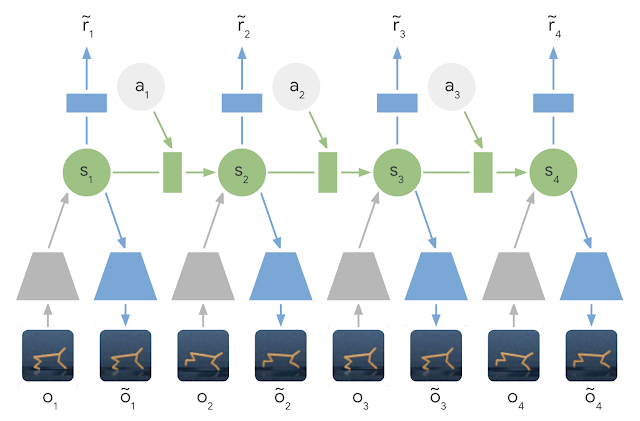
学习潜在动力学模型:在潜在动力学模型中,使用编码器网络(灰色梯形)将输入图像的信息集成到隐藏状态(绿色)中。然后向前投射隐藏状态以预测未来图像(蓝色梯形)和奖励(蓝色矩形)。
为了学习准确的潜在动力学模型,团队引入了:
- 循环状态空间模型:具有确定性和随机性成分的潜在动力学模型,允许根据稳健的计划预测各种可能的未来,同时记住多个时间步骤的信息。实验表明,这两个组件对于高规划性能至关重要。
- 潜在的超调目标:将潜动力模型的标准训练目标推广到训练多步预测,通过在潜空间中加强一步预测和多步预测的一致性。这产生了一个快速和有效的目标,提高了长期预测,并与任何潜在序列模型兼容。
虽然预测未来图像允许教授模型,但编码和解码图像(上图中的梯形)需要大量计算,这会减慢计划。然而,在紧凑的潜在状态空间中的规划是快速的,因为我们仅需要预测未来的奖励而不是图像来评估动作序列。
例如,智能体可以想象球的位置及其与目标的距离将如何针对某些动作而改变,而不必使场景可视化。这允许我们在每次智能体选择动作时比较1万个想象的动作序列和大批量大小。然后,执行找到的最佳序列的第一个动作,并在下一步重新计划。
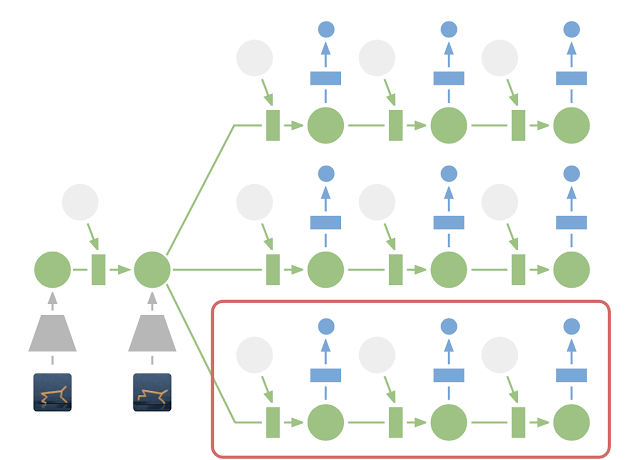
在潜在空间中进行规划:为了进行规划,将过去的图像(灰色梯形)编码为当前隐藏状态(绿色)。从那里,我们可以有效地预测多个动作序列的未来回报。请注意,上图中图像解码器(蓝色梯形)是如何消失的。然后执行找到的最佳序列的第一个操作(红色框)。
与之前的工作相比,PlaNet在没有策略网络的情况下工作,它纯粹通过计划选择行动,因此它可以从现场的模型改进中受益。
PlaNet与无模型方法
团队在连续控制任务上评估PlaNet。智能体仅获得图像观察和奖励。我们认为会带来各种不同挑战的任务:
- 一个推车摆动任务,带有固定的摄像头,cart可以移出视线。因此,智能体必须吸收并记住多个帧的信息。
- 手指旋转任务,需要预测两个单独的对象,以及它们之间的交互。
- 猎豹奔跑任务,包括难以准确预测的地面接触,要求可以预测多种可能未来的模型。
- 杯子任务,一旦球被抓住,它只提供稀疏的奖励信号。这需要在未来很准确的预测,以规划精确的行动序列。
- 走路任务,模拟机器人从躺在地上开始,必须先学会站起来然后才能走路。

PlaNet智能体接受过各种基于图像的控制任务的训练。当智能体正在解决任务时,动画显示输入图像。这些任务带来了不同的挑战:部分可观察性,与地面的接触,用于接球的稀疏奖励以及控制具有挑战性的双足机器人。
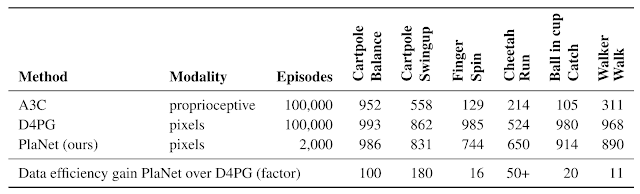
团队的研究构成了第一个例子,其中学习模型的计划优于基于图像的任务的无模型方法。下表将PlaNet与众所周知的A3C智能体和D4PG智能体进行了比较,结合了无模型强化学习的最新进展。这些基线的编号取自DeepMind Control Suite。PlaNet明显优于所有任务的A3C,并达到接近D4PG的最终性能,同时平均与环境的交互减少5000%。
一个智能体程序用于所有任务
此外,训练单个PlaNet代理程序来解决所有六个任务。在不知道任务的情况下将智能体随机放置到不同的环境中,因此需要从其图像观察中推断出任务。在不更改超参数的情况下,多任务智能体实现与各个代理相同的平均性能。虽然在推车任务上学习速度较慢,但在需要探索的具有挑战性的走路任务中,它学得更快,并达到更高的最终性能。
结论
我们的结果展示了建立自主强化学习智能体学习动力学模型的前景。我们提倡进一步研究,重点是学习更高难度任务的精确动力学模型,如3D环境和现实世界的机器人任务。扩大规模的可能因素是TPU的处理能力。我们对基于模型的强化学习开放的可能性感到兴奋,包括对多任务学习,分层规划和使用不确定性估计的主动探索。
开源:
github.com/google-research/planet

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消