











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






NVIDIA AI推理性能里程碑:高吞吐量,高效率,低延迟
2018年11月14日 由 浅浅 发表
129412
0
 推理是基于AI的应用程序真正发挥作用的地方。AI使越来越多的应用程序变得更加智能化,对象识别、图像分类、自然语言处理和推荐引擎只是其中的一小部分。
推理是基于AI的应用程序真正发挥作用的地方。AI使越来越多的应用程序变得更加智能化,对象识别、图像分类、自然语言处理和推荐引擎只是其中的一小部分。最近,TensorRT 5成为NVIDIA推理优化器和运行时的最新版本。该版本带来了新功能,包括支持最新的加速器NVIDIA T4,因此它充分利用了T4的新Turing Tensor核心,这使得INT8的精度比上一代低功耗产品快2倍。TensorRT推理服务器也是新产品,这是一种容器化推理微服务,可最大限度地提高NVIDIA GPU的利用率,并与Docker和Kubernetes无缝集成到DevOps部署中。
任何推理平台最终都是根据它为市场带来的性能和多功能性来衡量的,NVIDIA V100和T4加速器可以支持各个方面。
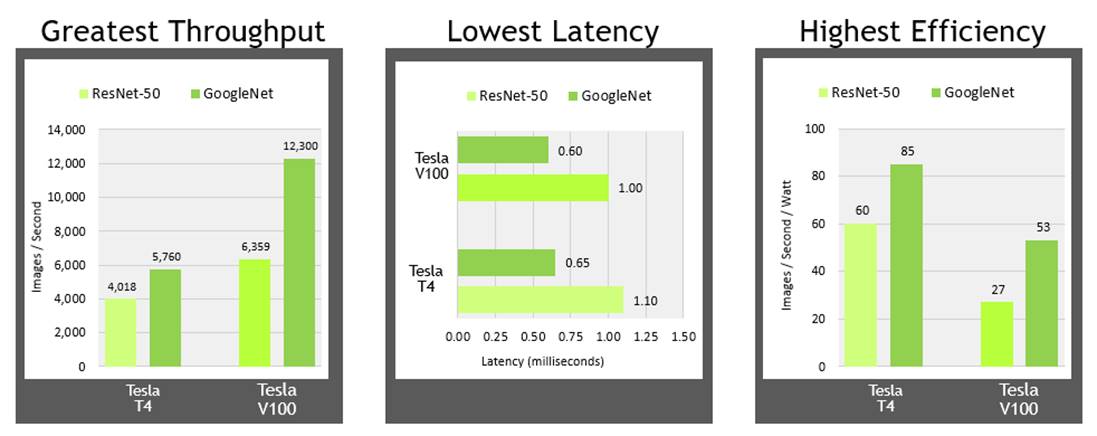 注意:此处使用TensorRT在ResNet-50上收集所有数据。吞吐量和效率测试以批量大小128运行;系统配置:双插座Xeon Gold 6140,配备384GB系统内存和一个Tesla V100或Tesla T4
注意:此处使用TensorRT在ResNet-50上收集所有数据。吞吐量和效率测试以批量大小128运行;系统配置:双插座Xeon Gold 6140,配备384GB系统内存和一个Tesla V100或Tesla T4吞吐量:NVIDIA T4和V100都提供了吞吐量水平,使各种经过训练的网络能够以最佳状态运行,甚至可以运行多个网络以在单个GPU上运行。此处显示的数据适用于高容量吞吐量,通常以批量大小128运行,其中低延迟不一定是问题,因为高容量吞吐量是最重要的。
延迟:对于越来越多的AI驱动的实时服务,低延迟是一个关键因素,NVIDIA V100和T4都可以提供大约1ms的延迟,使实时服务可以轻松扩展。
效率:最大化数据中心生产力的另一个关键考虑因素是在尽可能小的能源占用空间内提供卓越的性能。虽然V100提供更高的整体吞吐量,但T4确实可以提高效率,最高可达85张图像每秒/每瓦特。
速度只是个开始
我们最近讨论了一个名为PLASTER的框架,它表达了推理性能的七个关键要素。

NVIDIA数据中心平台提供了所有这七个因素,加速了对使用任何深度学习框架构建的所有类型网络的推断。今天的V100和T4都提供了出色的性能,可编程性和多功能性,但每个都是针对不同的数据中心基础设施而设计的。
V100专为扩展部署而设计,其中专用服务器将分别配备四个GPU,以处理重型工作负载,如AI训练和HPC。它们还可以提供大量的推理性能,并可以根据需要重新调整以承担任何这些工作负载。
就其本身而言,T4是专为横向扩展服务器设计而构建的,其中每个服务器可能每个都有一到两个GPU。T4的低配置PCIe外形尺寸和70W功率占用空间意味着它可以安装到现有的服务器部署中,从而显著延长这些服务器的使用寿命,并带来显着的性能提升。这种类型的服务器部署可以很好地处理高批量和实时推理,视频转码甚至分布式训练工作负载。
随着AI服务的数量和复杂程度不断提高,驱动他们的明显趋势是加速推理。过去依赖空余的备用CPU周期可能已足够,但随着网络规模和复杂性的增加,为智能AI驱动的产品和服务提供动力,这些趋势压倒了过去的CPU专用实践。最新的服务已经采用了最先进的AI,并将在不同类型的网络上执行多个推理,以便为单个用户请求提供服务。例如,向你的数字助理询问建议可能涉及:
- 自动语音识别(将请求从语音转换为文本)
- 自然语言处理(理解问题)
- 推荐系统(回答被问到的问题)
- 自然语言处理(将回答转换为会话语言)
- 语音合成(将文本转换为听起来很自然的语音)
对于一个请求,需要五个不同的推理操作,所有这些操作都必须在一秒钟内完成。这些趋势强调了加速推理的必要性,不仅要启用上述示例等服务,还要加快推向市场的步伐。NVIDIA V100和T4 GPU具有性能和可编程性,可以成为加速推向市场的各种推理驱动服务的单一平台。
因此,无论是扩展还是横向扩展,加速使用任何框架构建的任何类型的网络,NVIDIA V100和T4都已准备好迎接挑战,提供制作这些服务所需的高吞吐量,低延迟和高效率,使这些服务和产品成为现实。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消