











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






SigOpt:具有竞争目标的深度学习超参数优化,比传统方法快十倍
2017年08月03日 由 荟荟 发表
941666
0
在这篇文章中,我们将展示如何使用 SigOpt的贝叶斯优化平台来共同优化NVIDIA GPU上深度学习流水线中的竞争目标,比传统方法(如随机搜索)快十倍。
[caption id="attachment_29271" align="aligncenter" width="3128"]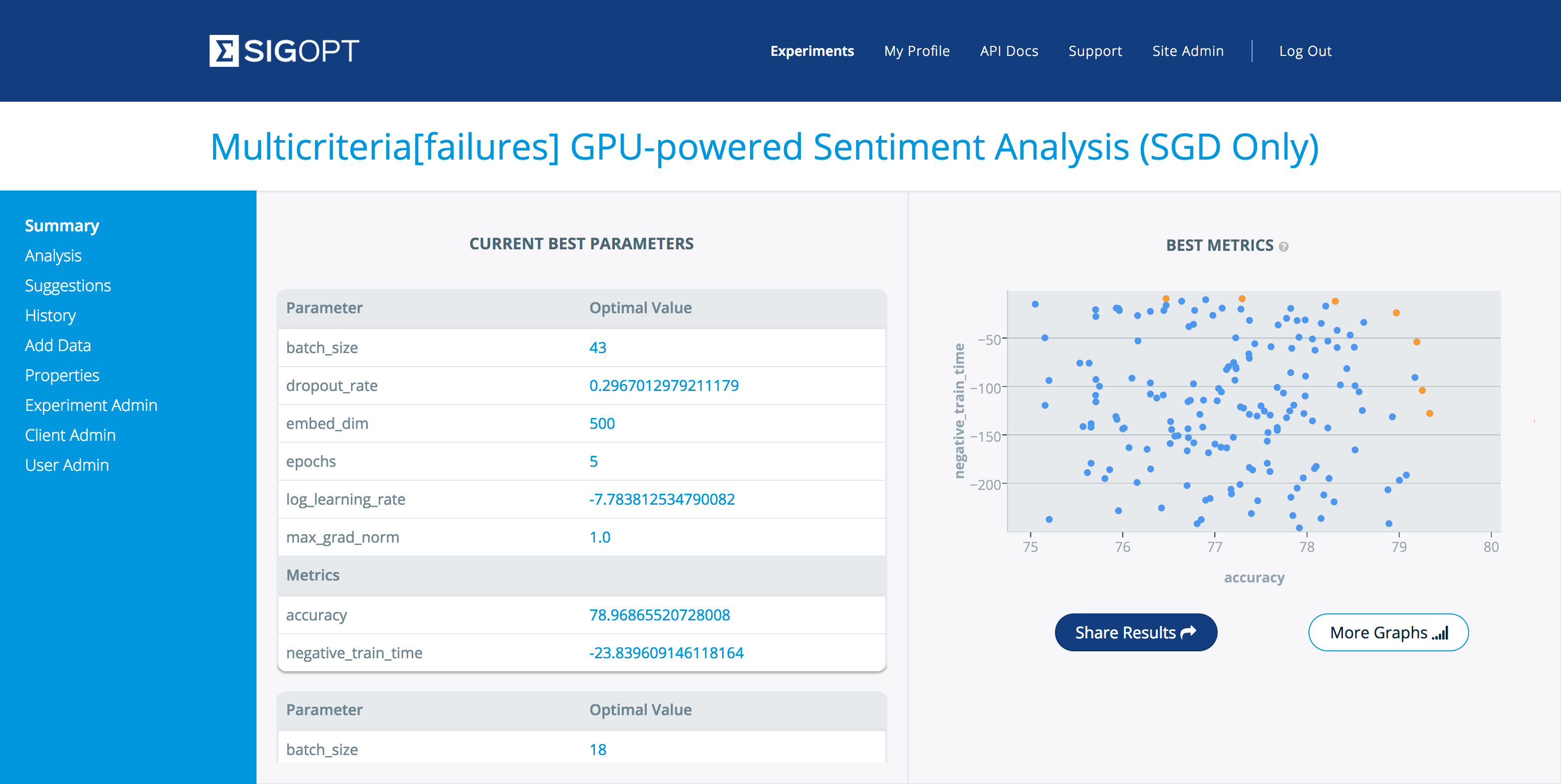 SigOpt Web仪表板的屏幕截图,用户可在其中跟踪机器学习模型优化的进度。[/caption]
SigOpt Web仪表板的屏幕截图,用户可在其中跟踪机器学习模型优化的进度。[/caption]
测量模型的执行情况可能不会归结为单一因素。通常有多种(有时是竞争的)方法来衡量模型性能。例如,在算法交易中,有效的交易策略是具有高投资组合回报和低亏损的策略。在信用卡行业中,有效的欺诈检测系统需要及时准确地识别欺诈交易(例如,小于50毫秒)。在广告领域,最佳广告系列应同时提高点击率和转化率。
针对多个度量的优化被称为多准则或多度量优化。与传统的单一度量标准优化相比,多重度优化更加昂贵且耗时, 因为它需要对底层系统进行更多评估以优化竞争指标。
SigOpt超参数优化工作流程
在使用神经网络和机器学习管道时,在安装模型之前需要配置许多免费配置参数(超参数)。超参数的选择可以在差的和优越的预测性能之间产生差异。在这篇文章中,我们证明了传统的超参数优化技术,如网格搜索,随机搜索和手动调整都无法在神经网络和机器学习管道面前很好地扩展。SigOpt使用通过REST API访问的贝叶斯优化策略集合提供优化即服务,允许从业者比这些标准方法更快,更便宜地有效优化深度学习应用程序。
我们探索了两个分类用例,一个使用生物序列数据,另一个使用自然语言处理(NLP)来自 AWS AI博客上的先前博客文章。
在这两个例子中,我们使用MXNet和Tensorflow(此处提供的代码)调整深度神经网络,暴露随机梯度下降(SGD)超参数以及神经网络的架构参数。我们比较SigOpt和随机搜索的时间和计算成本,以进行搜索以及生成的模型的质量。
深度学习中的竞争指标:
准确性与推理时间
在深度学习中,通常的权衡是在模型准确性和进行预测的速度之间。更复杂的网络可能能够实现更高的准确性,但是由于与更大,更深的网络相关联的更大的计算负担而以更慢的推理时间为代价(参见图1)。例如,增加特定卷积层的滤波器数量,或增加更多卷积层,将增加进行推理所需的计算次数,从而增加完成所需的时间。不幸的是,理论上确定特定体系结构的推理时间很快变得棘手。每个神经网络库都有不同的低级实现,因此必须凭经验观察性能。
[caption id="attachment_29272" align="aligncenter" width="490"]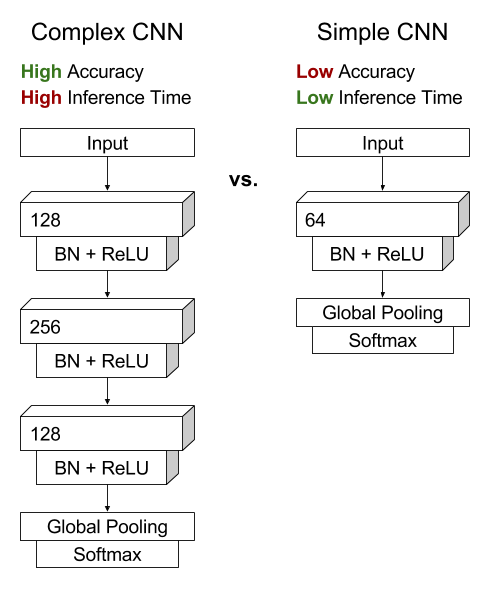 图1:完全卷积网络的示例体系结构,其中我们将三个层中的每个层的内核大小和内核数量公开为超参数。层数和过滤器数量增加了网络的复杂性,这可以提高准确性,通常以增加培训时间为代价。NVIDIA GPU允许跨过滤器进行并行计算,但跨层计算是一个固有的顺序过程。图像的动机由[Wang et。人。2016年]。[/caption]
图1:完全卷积网络的示例体系结构,其中我们将三个层中的每个层的内核大小和内核数量公开为超参数。层数和过滤器数量增加了网络的复杂性,这可以提高准确性,通常以增加培训时间为代价。NVIDIA GPU允许跨过滤器进行并行计算,但跨层计算是一个固有的顺序过程。图像的动机由[Wang et。人。2016年]。[/caption]
在多重度优化中确定模型性能是一个难题。例如,在欺诈检测模型中:可能是配置A导致0.96 F分数但是花费3秒来对给定事务进行分类,而配置B导致0.955 F分数但是仅需要20毫秒分类。配置A具有比配置B更高的F分数,但是对每个事务进行分类也需要更长的时间。根据正在进行的相对业务权衡,这些配置中的每一个在不同的设置中可以是最佳的。另一方面,我们不需要考虑配置C(.95 F-score,200 ms),因为它在两个指标中严格比配置B差。
在进行多重优化时,被认为是最好 的解决方案是没有其他解决方案严格更好的解决方案。很难比较其余的解决方案,因为它们在两个指标中都有优点和缺点(例如上面的配置A和B)。这些配置称为有效前沿 (或帕累托前沿),并且在优化后可以考虑显式权衡时进行评估。
使用定义的超参数空间,我们有以下试错工作流程:
让我们深入研究并通过SigOpt将贝叶斯优化与 两个分类任务的随机搜索的常见超参数优化技术进行比较。
[caption id="attachment_29274" align="aligncenter" width="600"] 图2:基于从黄石国家公园收集的土壤样本的硅藻群的扫描电子显微照片,由James Meadow提供。[/caption]
图2:基于从黄石国家公园收集的土壤样本的硅藻群的扫描电子显微照片,由James Meadow提供。[/caption]
该分析涉及硅藻,一种以二氧化硅制成的细胞壁为特征的藻类。硅藻的分布随气候和生态系统条件而变化,因此对这些分布进行分类和分析可以洞察过去,现在和未来的环境条件。硅藻分类也适用于水质监测和法医分析。
我们使用SigOpt调整神经网络的超参数,以准确 和快速地 通过构建一个multimetric优化问题,同时分类硅藻最大限度地提高精度 和减少推理 上验证数据集时(模型训练期间没有看到一个数据集)。该顺序数据集包含大约800个长度为176和37个硅藻类的样本。
定义超参数空间
除了网络本身的架构之外,我们还需要调整标准SGD(随机梯度下降)超参数,例如学习速率,学习速率衰减,批量大小等。由于模型体系结构和SGD参数的最佳配置取决于特定数据集,因此模型调整成为频繁更改数据的关键步骤。
对于此示例,组合神经网络架构和SGD配置空间由十几个超参数组成(表1):七个整数值和五个实值。仅整数值超参数具有超过450,000个潜在配置。我们训练了500个时代的模型,尽管这也可以是超
[caption id="attachment_29276" align="aligncenter" width="500"]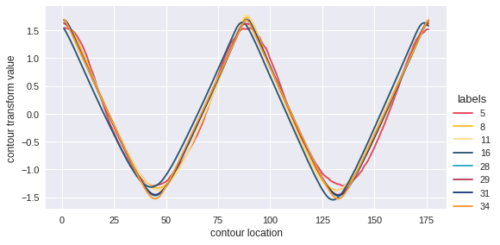 图3.从硅藻轮廓分析中提取的序列数据的可视化。这些图表代表了几个类来说明它们之间细微差别。[/caption]
图3.从硅藻轮廓分析中提取的序列数据的可视化。这些图表代表了几个类来说明它们之间细微差别。[/caption]
该分析涉及硅藻,一种以二氧化硅制成的细胞壁为特征的藻类。硅藻的分布随气候和生态系统条件而变化,因此对这些分布进行分类和分析可以洞察过去,现在和未来的环境条件。硅藻分类也适用于水质监测和法医分析。
我们使用SigOpt调整神经网络的超参数,以准确 和快速地 通过构建一个multimetric优化问题,同时分类硅藻最大限度地提高精度 和减少推理 上验证数据集时(模型训练期间没有看到一个数据集)。该顺序数据集包含大约800个长度为176和37个硅藻类的样本。
定义超参数空间
除了网络本身的架构之外,我们还需要调整标准SGD(随机梯度下降)超参数,例如学习速率,学习速率衰减,批量大小等。由于模型体系结构和SGD参数的最佳配置取决于特定数据集,因此模型调整成为频繁更改数据的关键步骤。
对于此示例,组合神经网络架构和SGD配置空间由十几个超参数组成(表1):七个整数值和五个实值。仅整数值超参数具有超过450,000个潜在配置。我们训练了500个时代的模型,尽管这也可以是超参数。
[caption id="attachment_29278" align="aligncenter" width="1135"]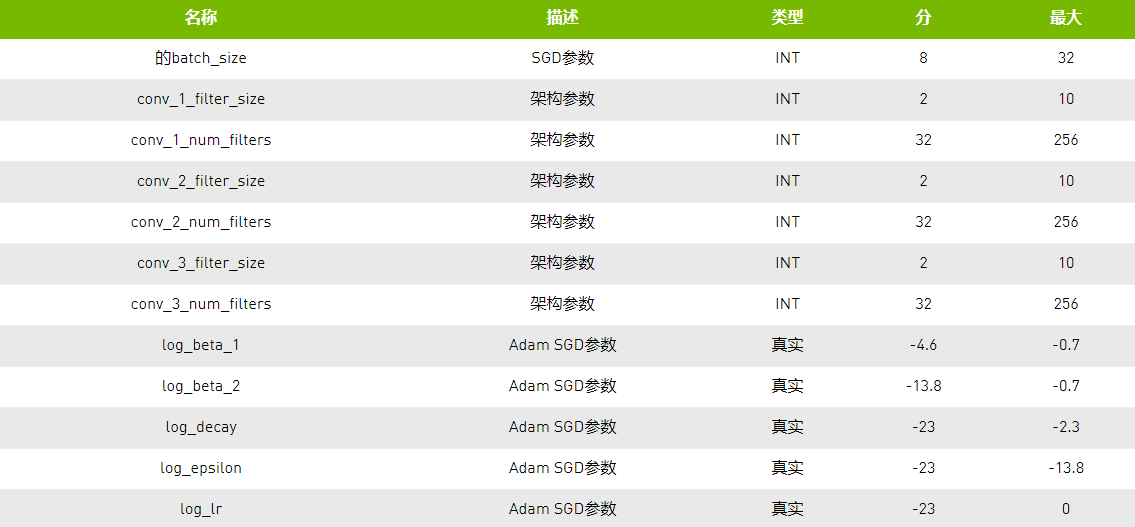 表1:此表总结了此时间序列示例的公开超参数配置。有关Adam SGD参数的更多信息,请参阅[Kingma et al。2015年]。[/caption]
表1:此表总结了此时间序列示例的公开超参数配置。有关Adam SGD参数的更多信息,请参阅[Kingma et al。2015年]。[/caption]
实验设置
在这个实验中,我们使用了[Wang等人描述的卷积神经网络的Keras的TensorFlow实现。2016]用于序列数据的分类。代码和说明这个实验的复制是可以在github 这里。
我们使用SigOpt和随机搜索来共同优化准确度和推理时间的度量。SigOpt对480个超参数配置进行了采样,随机搜索了4800个超参数配置。使用以下AMI (ami-193e860f ),使用单个NVIDIA K80 GPU在AWS P2实例上执行所有培训和推断。
结果概述
与随机搜索相比,图3中的图表分别提供了SigOpt的透视图。散点图上的每个点都是根据表1中的约束训练具有特定超参数配置的模型的结果。图表显示随机搜索训练4800个不同的超参数配置,而SigOpt建议480个配置。
[caption id="attachment_29279" align="aligncenter" width="1036"]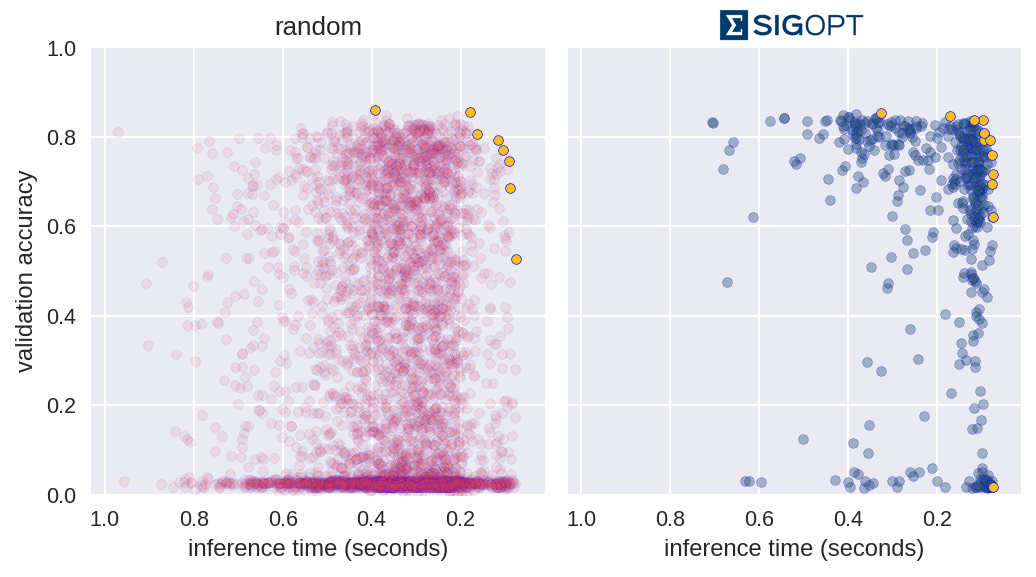 图4:随机与SigOpt结果的比较。每个方法图上的黄点集合称为帕累托边界。[/caption]
图4:随机与SigOpt结果的比较。每个方法图上的黄点集合称为帕累托边界。[/caption]
图4中的黄点值得关注,因为在这两个指标中没有其他模型配置更好。在学术界,黄点和它们各自的超参数配置被称为帕累托有效。每个方法的帕累托效率点的集合是它的帕累托前沿。在实践中,决策者在计算多个客观指标的帕累托前沿时允许存在一些误差,因为在处理随机模型验证技术时这些指标往往会产生噪声。
SigOpt能够找到比随机搜索更好的帕累托边界,评估次数减少十倍。实际上,当你采用两种方法输出的结合并检查其帕累托有效边界时,SigOpt的结果占合并边界的85.7%,尽管它需要减少90%的模型训练。
优化预算:
与SigOpt密集的帕累托边界相比,它通过随机搜索得到的相当稀疏的前沿需要10倍的评估和10倍的计算成本。然而,在实践中,可能存在时间和基础设施限制。
为了理解如果我们将相同的计算预算分配给随机搜索会发生什么,就像我们对SigOpt所做的那样,我们模拟了 与该问题的随机搜索相关的Pareto边界的置信区域。我们从随机搜索中对480个点进行二次抽样,计算出Pareto前沿,重复此过程800次,并绘制出图5中Pareto效率置信区域的近似值。红色强度较高的区域意味着在随机Pareto前沿上的可能性更高。
与随机搜索相比,SigOpt在两个指标上可靠地产生更好的结果。例如,随机搜索仅产生一个点,其验证准确度高于0.77,推理时间低于0.125秒。SigOpt的Pareto边界在该区域有6个点,它们都严格控制随机搜索点(两个指标都好或更好)。基于该图,具有随机搜索发生的最高可能性的点产生的精度低于SigOpt的帕累托边界的许多点。此外,SigOpt包含许多模型配置,其推理时间是最高似然随机搜索点的一半。
[caption id="attachment_29280" align="aligncenter" width="1600"]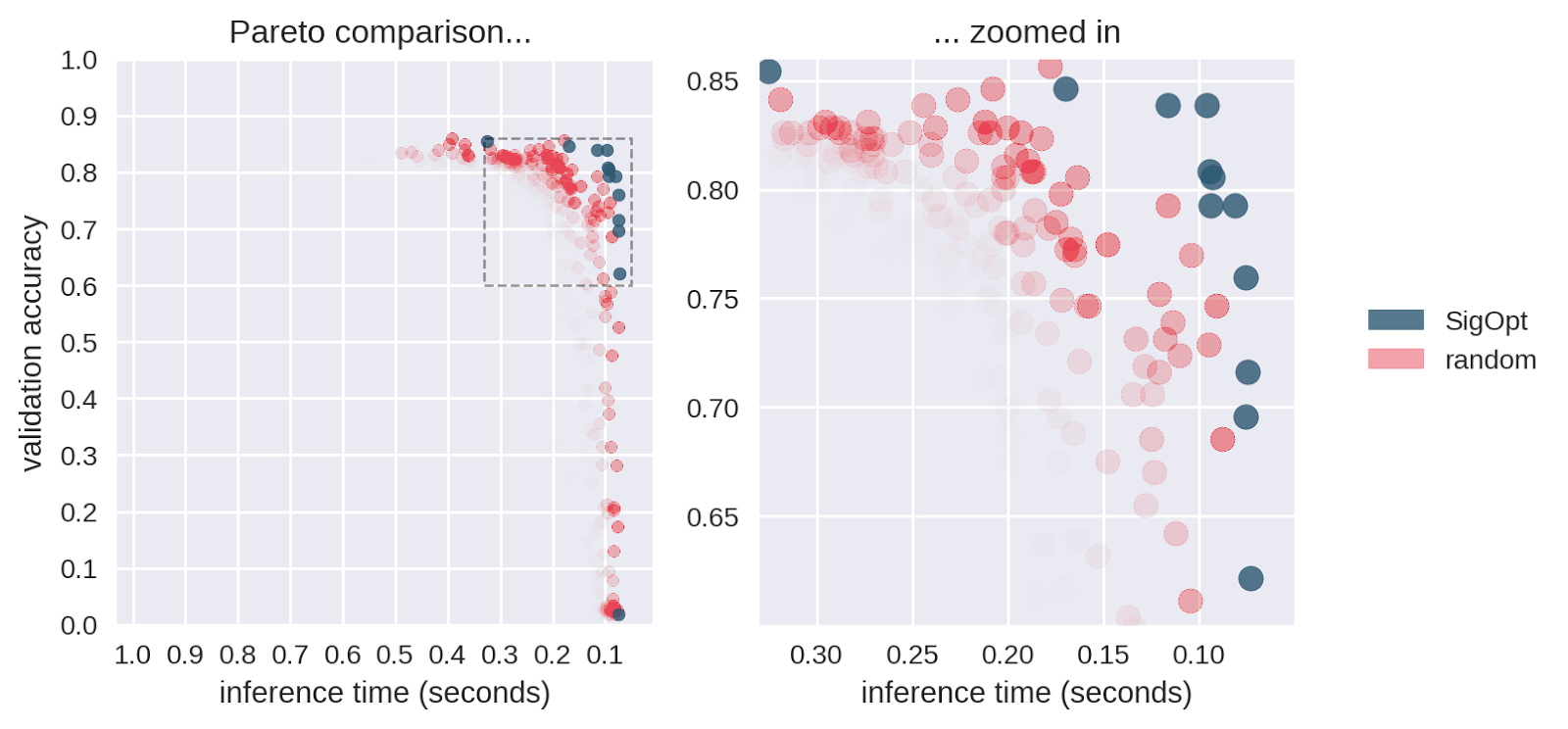 图5:与SigOpt结果(蓝色)相比,随机搜索的Pareto效率置信区域(红色),证明了SigOpt在相同的计算预算下产生更多的Pareto效率。[/caption]
图5:与SigOpt结果(蓝色)相比,随机搜索的Pareto效率置信区域(红色),证明了SigOpt在相同的计算预算下产生更多的Pareto效率。[/caption]
为什么智能超参数调整很重要?图5中的动画显示SigOpt学习了比随机采样10倍更多有效超参数配置,并且智能地学习如何在12维超参数空间周围进行操纵。
[caption id="attachment_29281" align="aligncenter" width="595"]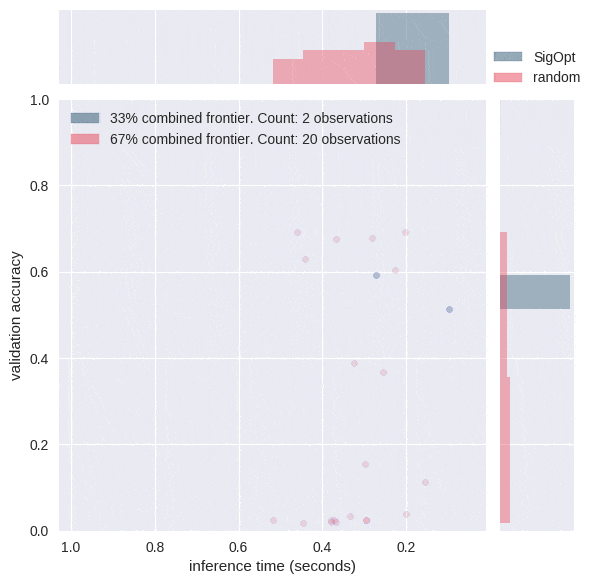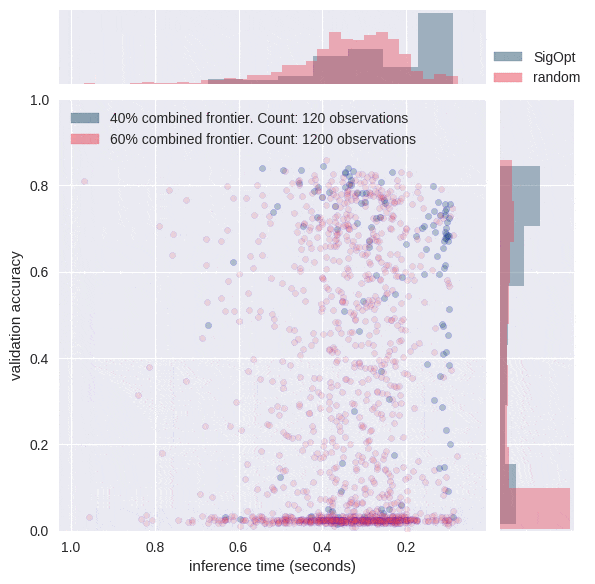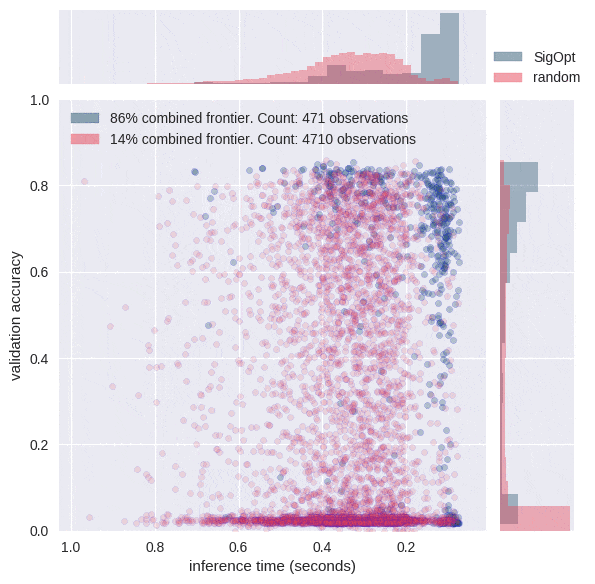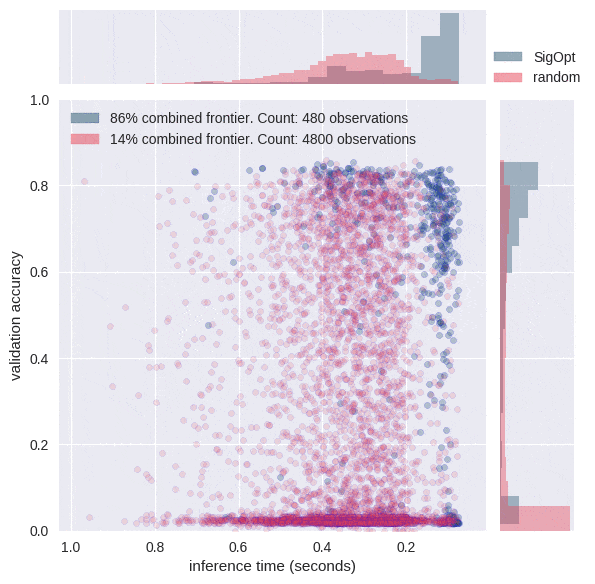 图6:请注意,大多数情况下,随机搜索会提供精度较差且推理时间范围更广的配置。SigOpt为两个指标找到了良好的值,其评估次数比随机搜索少十倍。[/caption]
图6:请注意,大多数情况下,随机搜索会提供精度较差且推理时间范围更广的配置。SigOpt为两个指标找到了良好的值,其评估次数比随机搜索少十倍。[/caption]
用例2:烂番茄情绪分析
作为另一个例子,我们 从AWS AI博客扩展了以前的帖子。该示例比较了CNN的超参数优化策略,以最大化自然语言处理(NLP)任务上的模型分类准确性。鉴于来自烂番茄的10,000多个电影评论,目标是创建一个神经网络模型,准确地将电影评论分类为正面或负面。
度量标准和设置
在这个实验中,我们使用了[Yoon Kim等人描述的卷积神经网络的MXNet实现。2015]用于NLP数据的分类。代码和说明这个实验的复制是可以在github 这里。
暴露与AWS帖子相同的超参数,SigOpt和随机搜索都用于联合优化准确度和培训时间的指标。SigOpt对480个超参数配置进行了采样,随机搜索采样1800个超参数配置。使用以下AMI (ami-193e860f ),使用单个NVIDIA K80 GPU在AWS P2实例上执行所有培训和推理。
在这个例子中,我们利用SigOpt的能力来学习 超参数空间中的失效区域。我们报告的模型配置产生的准确度低于75%,训练时间超过250秒,回到SigOpt作为失败,迫使Pareto前沿在图6所示的重点区域得到解决。这种方法可能有用,例如,欺诈检测管道,您可能不希望考虑快速生成F分数低于业务应用程序确定的阈值的结果的配置。
表2显示了用于该模型的六个超参数。
[caption id="attachment_29282" align="aligncenter" width="1138"]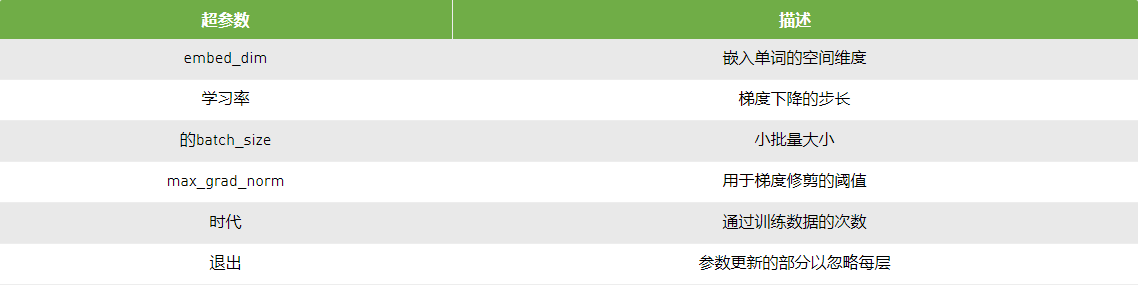 表2.此表总结了此自然语言处理示例的公开超参数配置。有关更详细的说明,请参阅AWS AI博客。[/caption]
表2.此表总结了此自然语言处理示例的公开超参数配置。有关更详细的说明,请参阅AWS AI博客。[/caption]
和以前一样,我们模拟了随机搜索的Pareto前沿的置信区域,好像预算是相同的,我们看到随机搜索严格由SigOpt的边界控制(SigOpt点在两个指标中都是好的或更好的)。对于在不到250秒内训练的模型,SigOpt代表组合边界的100%。采用故障区域有助于提高SigOpt的性能,其中48%的SigOpt配置位于可行配置区域,只有26%的随机配置可行。
[caption id="attachment_29283" align="aligncenter" width="1231"]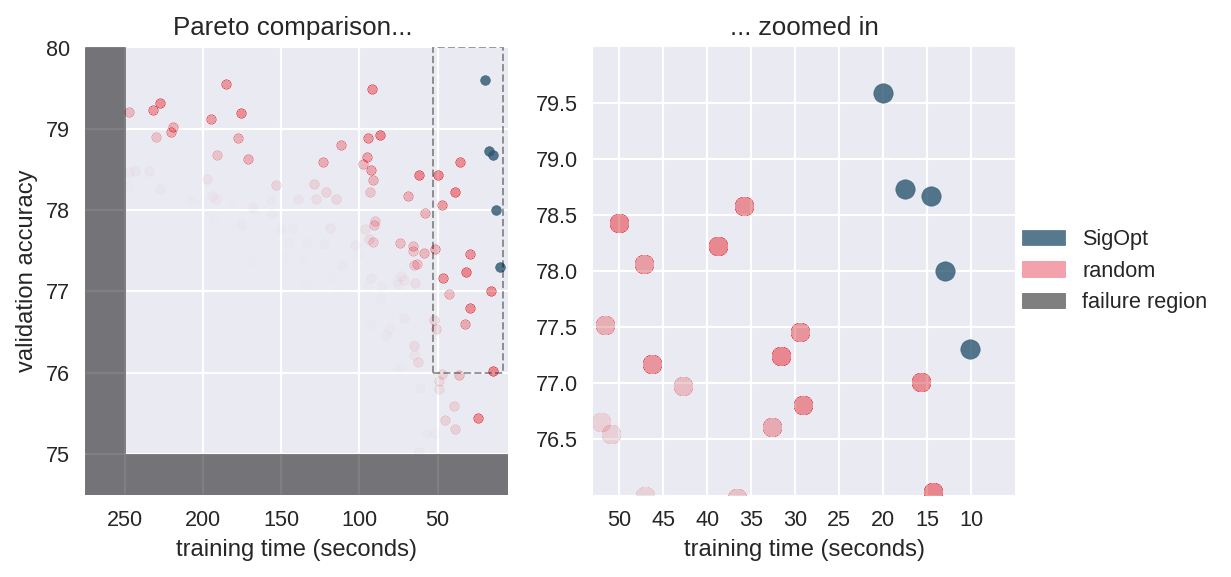 图7:与SigOpt结果相比,随机搜索的Pareto效率置信区域。[/caption]
图7:与SigOpt结果相比,随机搜索的Pareto效率置信区域。[/caption]
使用SigOpt更快地优化ML模型
找到模型的有效前沿使您可以在给定这些有效可行点的情况下选择性能指标之间的最佳权衡。具有更高个体度量值的密集Pareto前沿意味着更多更好的模型配置可供选择。
此外,许多具有优化经验的建模人员都关注 解决方案的稳健性:当稍微改变超参数配置或底层数据时,最重要的是模型的性能不会超出一小部分误差。虽然建模者有责任确定配置的稳健性,但拥有密集的Pareto前沿和更高质量的模型可以提供更多选项,以便找到最佳性能的稳健配置以部署到生产中。
从今天开始!
SigOpt通过提供对超参数空间的有效搜索,使得组织能够从他们的机器学习管道和深度学习模型中获得最大收益,从而比传统方法(如随机搜索,网格搜索和手动调整)获得更好的结果。
要复制硅藻分类问题,请参阅github页面。
要复制Rotten Tomatoes示例,请参阅github页面。
访问SigOpt 了解更多信息。
参考
[康奈尔计算机科学] 电影评论数据
[加州大学河滨分校计算机科学] UCR时间序列分类档案
[Wang et al。2016年] 从深度神经网络划痕的时间序列分类: 具有相关代码的强基线,发布于2017年IJCNN,神经网络国际联合会议,2017年。
[Wang et al。2015] 成像时间序列改善分类和估算
[爱丁堡皇家植物园] 自动硅藻识别和分类
[Buf和Bayer,2002] 关于自动硅藻识别的书籍
[Jalba,2004] 硅藻图像的自动分割用于分类,显微镜研究和技术
[Jalba,2005] 通过形态曲率尺度空间的轮廓分析自动硅藻识别,机器视觉和应用
[Hu et al。2013年] 更现实的假设下的时间序列分类,SIAM 2013,数据挖掘
[Kingma et al。2015] 亚当:随机优化的方法,2015年学习代表国际会议
[caption id="attachment_29271" align="aligncenter" width="3128"]
SigOpt Web仪表板的屏幕截图,用户可在其中跟踪机器学习模型优化的进度。[/caption]测量模型的执行情况可能不会归结为单一因素。通常有多种(有时是竞争的)方法来衡量模型性能。例如,在算法交易中,有效的交易策略是具有高投资组合回报和低亏损的策略。在信用卡行业中,有效的欺诈检测系统需要及时准确地识别欺诈交易(例如,小于50毫秒)。在广告领域,最佳广告系列应同时提高点击率和转化率。
针对多个度量的优化被称为多准则或多度量优化。与传统的单一度量标准优化相比,多重度优化更加昂贵且耗时, 因为它需要对底层系统进行更多评估以优化竞争指标。
SigOpt超参数优化工作流程
在使用神经网络和机器学习管道时,在安装模型之前需要配置许多免费配置参数(超参数)。超参数的选择可以在差的和优越的预测性能之间产生差异。在这篇文章中,我们证明了传统的超参数优化技术,如网格搜索,随机搜索和手动调整都无法在神经网络和机器学习管道面前很好地扩展。SigOpt使用通过REST API访问的贝叶斯优化策略集合提供优化即服务,允许从业者比这些标准方法更快,更便宜地有效优化深度学习应用程序。
我们探索了两个分类用例,一个使用生物序列数据,另一个使用自然语言处理(NLP)来自 AWS AI博客上的先前博客文章。
在这两个例子中,我们使用MXNet和Tensorflow(此处提供的代码)调整深度神经网络,暴露随机梯度下降(SGD)超参数以及神经网络的架构参数。我们比较SigOpt和随机搜索的时间和计算成本,以进行搜索以及生成的模型的质量。
深度学习中的竞争指标:
准确性与推理时间
在深度学习中,通常的权衡是在模型准确性和进行预测的速度之间。更复杂的网络可能能够实现更高的准确性,但是由于与更大,更深的网络相关联的更大的计算负担而以更慢的推理时间为代价(参见图1)。例如,增加特定卷积层的滤波器数量,或增加更多卷积层,将增加进行推理所需的计算次数,从而增加完成所需的时间。不幸的是,理论上确定特定体系结构的推理时间很快变得棘手。每个神经网络库都有不同的低级实现,因此必须凭经验观察性能。
[caption id="attachment_29272" align="aligncenter" width="490"]
图1:完全卷积网络的示例体系结构,其中我们将三个层中的每个层的内核大小和内核数量公开为超参数。层数和过滤器数量增加了网络的复杂性,这可以提高准确性,通常以增加培训时间为代价。NVIDIA GPU允许跨过滤器进行并行计算,但跨层计算是一个固有的顺序过程。图像的动机由[Wang et。人。2016年]。[/caption]多学科设置中的客观评价
在多重度优化中确定模型性能是一个难题。例如,在欺诈检测模型中:可能是配置A导致0.96 F分数但是花费3秒来对给定事务进行分类,而配置B导致0.955 F分数但是仅需要20毫秒分类。配置A具有比配置B更高的F分数,但是对每个事务进行分类也需要更长的时间。根据正在进行的相对业务权衡,这些配置中的每一个在不同的设置中可以是最佳的。另一方面,我们不需要考虑配置C(.95 F-score,200 ms),因为它在两个指标中严格比配置B差。
在进行多重优化时,被认为是最好 的解决方案是没有其他解决方案严格更好的解决方案。很难比较其余的解决方案,因为它们在两个指标中都有优点和缺点(例如上面的配置A和B)。这些配置称为有效前沿 (或帕累托前沿),并且在优化后可以考虑显式权衡时进行评估。
优化循环
使用定义的超参数空间,我们有以下试错工作流程:
- 建议具体的模型架构和SGD参数配置;
- 根据此配置训练模型;
- 观察推理时间和准确度;
- 重复步骤(1)至(4)直到预算用尽;
- 返回一组“高效”配置。
让我们深入研究并通过SigOpt将贝叶斯优化与 两个分类任务的随机搜索的常见超参数优化技术进行比较。
用例1:生物环境中的序列数据
[caption id="attachment_29274" align="aligncenter" width="600"]
图2:基于从黄石国家公园收集的土壤样本的硅藻群的扫描电子显微照片,由James Meadow提供。[/caption]该分析涉及硅藻,一种以二氧化硅制成的细胞壁为特征的藻类。硅藻的分布随气候和生态系统条件而变化,因此对这些分布进行分类和分析可以洞察过去,现在和未来的环境条件。硅藻分类也适用于水质监测和法医分析。
我们使用SigOpt调整神经网络的超参数,以准确 和快速地 通过构建一个multimetric优化问题,同时分类硅藻最大限度地提高精度 和减少推理 上验证数据集时(模型训练期间没有看到一个数据集)。该顺序数据集包含大约800个长度为176和37个硅藻类的样本。
定义超参数空间
除了网络本身的架构之外,我们还需要调整标准SGD(随机梯度下降)超参数,例如学习速率,学习速率衰减,批量大小等。由于模型体系结构和SGD参数的最佳配置取决于特定数据集,因此模型调整成为频繁更改数据的关键步骤。
对于此示例,组合神经网络架构和SGD配置空间由十几个超参数组成(表1):七个整数值和五个实值。仅整数值超参数具有超过450,000个潜在配置。我们训练了500个时代的模型,尽管这也可以是超
[caption id="attachment_29276" align="aligncenter" width="500"]
图3.从硅藻轮廓分析中提取的序列数据的可视化。这些图表代表了几个类来说明它们之间细微差别。[/caption]该分析涉及硅藻,一种以二氧化硅制成的细胞壁为特征的藻类。硅藻的分布随气候和生态系统条件而变化,因此对这些分布进行分类和分析可以洞察过去,现在和未来的环境条件。硅藻分类也适用于水质监测和法医分析。
我们使用SigOpt调整神经网络的超参数,以准确 和快速地 通过构建一个multimetric优化问题,同时分类硅藻最大限度地提高精度 和减少推理 上验证数据集时(模型训练期间没有看到一个数据集)。该顺序数据集包含大约800个长度为176和37个硅藻类的样本。
定义超参数空间
除了网络本身的架构之外,我们还需要调整标准SGD(随机梯度下降)超参数,例如学习速率,学习速率衰减,批量大小等。由于模型体系结构和SGD参数的最佳配置取决于特定数据集,因此模型调整成为频繁更改数据的关键步骤。
对于此示例,组合神经网络架构和SGD配置空间由十几个超参数组成(表1):七个整数值和五个实值。仅整数值超参数具有超过450,000个潜在配置。我们训练了500个时代的模型,尽管这也可以是超参数。
[caption id="attachment_29278" align="aligncenter" width="1135"]
表1:此表总结了此时间序列示例的公开超参数配置。有关Adam SGD参数的更多信息,请参阅[Kingma et al。2015年]。[/caption] 实验设置
在这个实验中,我们使用了[Wang等人描述的卷积神经网络的Keras的TensorFlow实现。2016]用于序列数据的分类。代码和说明这个实验的复制是可以在github 这里。
我们使用SigOpt和随机搜索来共同优化准确度和推理时间的度量。SigOpt对480个超参数配置进行了采样,随机搜索了4800个超参数配置。使用以下AMI (ami-193e860f ),使用单个NVIDIA K80 GPU在AWS P2实例上执行所有培训和推断。
结果概述
与随机搜索相比,图3中的图表分别提供了SigOpt的透视图。散点图上的每个点都是根据表1中的约束训练具有特定超参数配置的模型的结果。图表显示随机搜索训练4800个不同的超参数配置,而SigOpt建议480个配置。
[caption id="attachment_29279" align="aligncenter" width="1036"]
图4:随机与SigOpt结果的比较。每个方法图上的黄点集合称为帕累托边界。[/caption]图4中的黄点值得关注,因为在这两个指标中没有其他模型配置更好。在学术界,黄点和它们各自的超参数配置被称为帕累托有效。每个方法的帕累托效率点的集合是它的帕累托前沿。在实践中,决策者在计算多个客观指标的帕累托前沿时允许存在一些误差,因为在处理随机模型验证技术时这些指标往往会产生噪声。
SigOpt能够找到比随机搜索更好的帕累托边界,评估次数减少十倍。实际上,当你采用两种方法输出的结合并检查其帕累托有效边界时,SigOpt的结果占合并边界的85.7%,尽管它需要减少90%的模型训练。
优化预算:
帕累托有效置信区域
与SigOpt密集的帕累托边界相比,它通过随机搜索得到的相当稀疏的前沿需要10倍的评估和10倍的计算成本。然而,在实践中,可能存在时间和基础设施限制。
为了理解如果我们将相同的计算预算分配给随机搜索会发生什么,就像我们对SigOpt所做的那样,我们模拟了 与该问题的随机搜索相关的Pareto边界的置信区域。我们从随机搜索中对480个点进行二次抽样,计算出Pareto前沿,重复此过程800次,并绘制出图5中Pareto效率置信区域的近似值。红色强度较高的区域意味着在随机Pareto前沿上的可能性更高。
与随机搜索相比,SigOpt在两个指标上可靠地产生更好的结果。例如,随机搜索仅产生一个点,其验证准确度高于0.77,推理时间低于0.125秒。SigOpt的Pareto边界在该区域有6个点,它们都严格控制随机搜索点(两个指标都好或更好)。基于该图,具有随机搜索发生的最高可能性的点产生的精度低于SigOpt的帕累托边界的许多点。此外,SigOpt包含许多模型配置,其推理时间是最高似然随机搜索点的一半。
[caption id="attachment_29280" align="aligncenter" width="1600"]
图5:与SigOpt结果(蓝色)相比,随机搜索的Pareto效率置信区域(红色),证明了SigOpt在相同的计算预算下产生更多的Pareto效率。[/caption]可视化:智能超参数调整
为什么智能超参数调整很重要?图5中的动画显示SigOpt学习了比随机采样10倍更多有效超参数配置,并且智能地学习如何在12维超参数空间周围进行操纵。
[caption id="attachment_29281" align="aligncenter" width="595"]
图6:请注意,大多数情况下,随机搜索会提供精度较差且推理时间范围更广的配置。SigOpt为两个指标找到了良好的值,其评估次数比随机搜索少十倍。[/caption]用例2:烂番茄情绪分析
作为另一个例子,我们 从AWS AI博客扩展了以前的帖子。该示例比较了CNN的超参数优化策略,以最大化自然语言处理(NLP)任务上的模型分类准确性。鉴于来自烂番茄的10,000多个电影评论,目标是创建一个神经网络模型,准确地将电影评论分类为正面或负面。
度量标准和设置
在这个实验中,我们使用了[Yoon Kim等人描述的卷积神经网络的MXNet实现。2015]用于NLP数据的分类。代码和说明这个实验的复制是可以在github 这里。
暴露与AWS帖子相同的超参数,SigOpt和随机搜索都用于联合优化准确度和培训时间的指标。SigOpt对480个超参数配置进行了采样,随机搜索采样1800个超参数配置。使用以下AMI (ami-193e860f ),使用单个NVIDIA K80 GPU在AWS P2实例上执行所有培训和推理。
在这个例子中,我们利用SigOpt的能力来学习 超参数空间中的失效区域。我们报告的模型配置产生的准确度低于75%,训练时间超过250秒,回到SigOpt作为失败,迫使Pareto前沿在图6所示的重点区域得到解决。这种方法可能有用,例如,欺诈检测管道,您可能不希望考虑快速生成F分数低于业务应用程序确定的阈值的结果的配置。
表2显示了用于该模型的六个超参数。
[caption id="attachment_29282" align="aligncenter" width="1138"]
表2.此表总结了此自然语言处理示例的公开超参数配置。有关更详细的说明,请参阅AWS AI博客。[/caption]结果概述
和以前一样,我们模拟了随机搜索的Pareto前沿的置信区域,好像预算是相同的,我们看到随机搜索严格由SigOpt的边界控制(SigOpt点在两个指标中都是好的或更好的)。对于在不到250秒内训练的模型,SigOpt代表组合边界的100%。采用故障区域有助于提高SigOpt的性能,其中48%的SigOpt配置位于可行配置区域,只有26%的随机配置可行。
[caption id="attachment_29283" align="aligncenter" width="1231"]
图7:与SigOpt结果相比,随机搜索的Pareto效率置信区域。[/caption]使用SigOpt更快地优化ML模型
找到模型的有效前沿使您可以在给定这些有效可行点的情况下选择性能指标之间的最佳权衡。具有更高个体度量值的密集Pareto前沿意味着更多更好的模型配置可供选择。
此外,许多具有优化经验的建模人员都关注 解决方案的稳健性:当稍微改变超参数配置或底层数据时,最重要的是模型的性能不会超出一小部分误差。虽然建模者有责任确定配置的稳健性,但拥有密集的Pareto前沿和更高质量的模型可以提供更多选项,以便找到最佳性能的稳健配置以部署到生产中。
从今天开始!
SigOpt通过提供对超参数空间的有效搜索,使得组织能够从他们的机器学习管道和深度学习模型中获得最大收益,从而比传统方法(如随机搜索,网格搜索和手动调整)获得更好的结果。
要复制硅藻分类问题,请参阅github页面。
要复制Rotten Tomatoes示例,请参阅github页面。
访问SigOpt 了解更多信息。
参考
[康奈尔计算机科学] 电影评论数据
[加州大学河滨分校计算机科学] UCR时间序列分类档案
[Wang et al。2016年] 从深度神经网络划痕的时间序列分类: 具有相关代码的强基线,发布于2017年IJCNN,神经网络国际联合会议,2017年。
[Wang et al。2015] 成像时间序列改善分类和估算
[爱丁堡皇家植物园] 自动硅藻识别和分类
[Buf和Bayer,2002] 关于自动硅藻识别的书籍
[Jalba,2004] 硅藻图像的自动分割用于分类,显微镜研究和技术
[Jalba,2005] 通过形态曲率尺度空间的轮廓分析自动硅藻识别,机器视觉和应用
[Hu et al。2013年] 更现实的假设下的时间序列分类,SIAM 2013,数据挖掘
[Kingma et al。2015] 亚当:随机优化的方法,2015年学习代表国际会议

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消