











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌发布机器翻译模型最新版本Universal Transformer,性能提高近50%
2018年08月16日 由 浅浅 发表
799686
0

去年谷歌发布了Transformer,这是一种新的机器学习模型,在现有的机器翻译算法和其他语言理解方面取得了显著成功。在Transformer之前,大多数基于神经网络的机器翻译方法依赖于循环运算的递归神经网络(RNN),它使用循环(即每一步的输出都进入下一步)按顺序运行(例如,一个接一个地翻译句子中的单词)。虽然RNN在建模序列方面非常强大,但它们的顺序性意味着它们训练起来很慢,因为较长的句子需要更多的处理步骤,并且它们的重复结构也使得它们难以正确训练。
与基于RNN的方法相比,Transformer不使用重复,而是并行处理序列中的所有单词或符号,同时利用自我注意机制来结合较远单词与上下文。通过并行处理所有单词并让每个单词在多个处理步骤中处理句子中的其他单词,Transformer比复制模型更快地训练。值得注意的是,它也比RNN产生了更好的翻译结果。然而,在更小和更结构化的语言理解任务,甚至简单的算法任务,如复制字符串(例如,将“abc”的输入转换为“abcabc”),Transformer的表现都不是很好。相比之下,在这些任务中表现良好的模型,如神经GPU和神经图灵机,无法完成翻译这种大规模语言理解任务。
在“Universal Transformers”中,谷歌使用新颖,高效的并行时间复发方式将标准变压器扩展为计算通用(图灵完备)模型,这可以在更广泛的任务中产生更强的结果。团队将其建立在Transformer的并行结构上以保持其快速的训练速度,但是用一个并行的并行循环变换函数的几个应用程序替换了Transformer的不同变换函数的固定堆栈(即相同的学习转换函数是在多个处理步骤中并行应用于所有符号,其中每个步骤的输出都进入到下一个)。至关重要的是,RNN处理符号逐个符号(从左到右),Universal Transformer同时处理所有符号(如Transformer那样),但随后在可变数量的情况下并行地对每个符号的解释进行细化。这种平行时间的递归机制比在RNN中使用的串行递归快得多,也使Universal Transformer比标准前馈Transformer更强大。
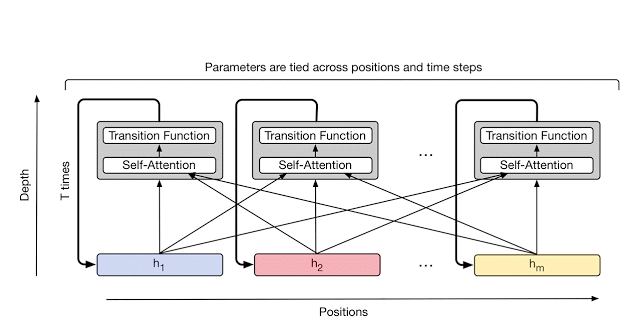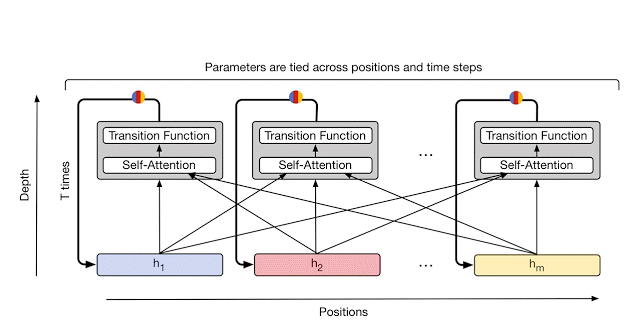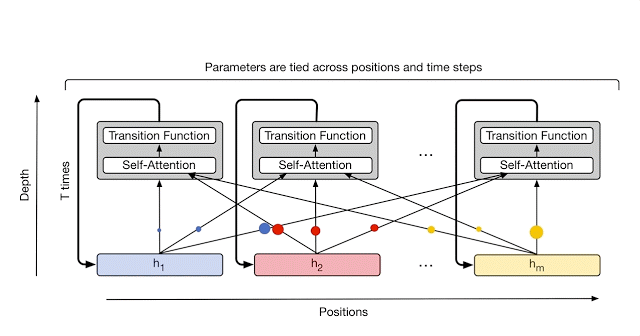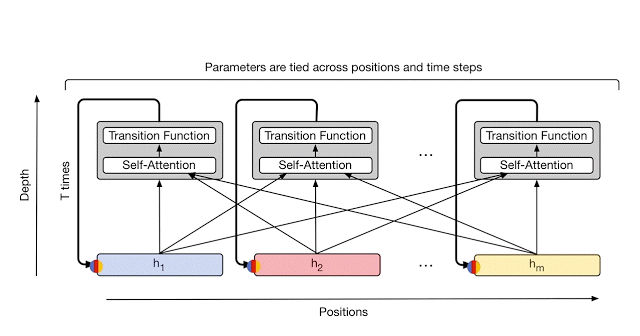
Universal Transformer通过使用自我关注和应用循环转换函数组合来自不同位置的信息,对序列的每个位置并行地重复细化一系列矢量表示(显示为h_1至h_m)。箭头表示操作之间的依赖关系。
在每个步骤中,信息从每个符号(例如句子中的单词)传递到使用自我注意的所有其他符号,就像在原始变换器中一样。但是,现在这个转换应用于每个符号的次数(即循环步骤的数量)可以提前手动设置(例如,到某个固定数字或输入长度),或者可以通过动态决定Universal Transformer本身。为了实现后者,团队为每个位置添加了自适应计算机制,可以为更加模糊或需要更多计算的符号分配更多处理步骤。
举一个直观的例子,如“I arrived at the bank after crossing the river”,在这种情况下,与“I”或“river”的含糊不清的含义相比,需要更多的背景来推断单词“bank”的最可能含义。当我们使用标准Transformer编码这个句子时,无条件地对每个单词应用相同的计算量。然而,Universal Transformer的自适应机制允许模型仅在更模糊的单词上花费增加的计算,例如使用更多步骤来集成消除歧义单词“bank”所需的附加上下文信息,同时在较不模糊的单词上花费更少的步骤。
首先,允许Universal Transformer仅应用单个变量似乎是限制性的,特别是与学习应用固定的不同功能序列的标准Transformer相比。但是学习如何重复应用单个函数意味着应用程序(处理步骤)的数量现在可以变化,这是至关重要的区别。除了允许Universal Transformer将更多计算应用于更模糊的符号之外,如上所述,它还允许模型使用输入的总体大小(更长的序列的更多步骤)来缩放功能应用的数量,或者动态地决定如何通常根据训练期间学到的其他特征将该功能应用于输入的任何给定部分。这使得Universal Transformer在理论意义上更强大,因为它可以有效地学习应用不同的变换到输入的不同部分。这是标准Transformer无法做到的事情,因为它包含仅应用一次的固定堆栈的学习转换块。
但是,虽然增加理论力量是可取的,但团队也关心经验表现。实验证实,Universal Transformers确实能够从示例中学习如何复制和反转字符串,以及如何比Transformer或RNN更好地执行整数加法(尽管不如神经GPU那么好)。此外,在一系列具有挑战性的语言理解任务中,Universal Transformer在bAbI语言推理任务和具有挑战性的LAMBADA 语言建模任务方面进行了更好的概括,并实现了最新技术水平。但也许最令人感兴趣的是,Universal Transformers在相同数量的参数下以相同的方式用相同的数据进行训练后,也可以将翻译质量提高0.9个BLEU值。去年Transformer性能比之前的模型提高了2.0 个BLEU值,而Universal Transformer的相对改进量是去年的近50%。
因此,Universal Transformer缩小了实际序列模型之间的差距,这些模型在大规模语言理解任务(例如机器翻译)和计算通用模型(例如神经图灵机或神经GPU)上具有竞争力,可以使用梯度下降来训练以执行任意算法任务。团队对并行时序模型的最新发展充满热情,除了增加计算能力和处理深度的重现之外,希望对此处介绍的基本Universal Transformer的进一步改进将有助于构建更多,更强大,更高效利用数据的学习算法功能,并且超越当前最先进的技术。
如果你想自己尝试一下,在开源的Tensor2Tensor存储库中可以找到用于训练和评估Universal Transformer的代码:github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/research/universal_transformer.py

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消