











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






基于TensorFlow的比较研究:卷积神经网络(CNN)优化算法
2018年01月21日 由 xiaoshan.xiang 发表
798666
0
用于训练神经网络的最受欢迎的优化算法有哪些?如何比较它们?本文试图用一个卷积神经网络(CNN)来回答这些问题。

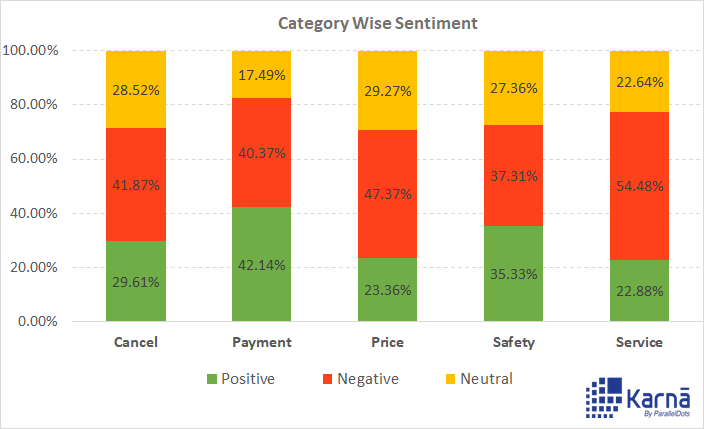
SGD通过选取大小(m)的子集或小批量数据,更新在梯度(g)的反方向上的模型参数(g):
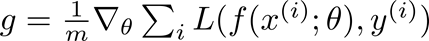
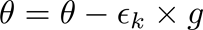
神经网络由 f(x(i); theta)表示;其中x(i)为训练数据,y(i)为训练标签,损失L的梯度是根据模型参数theta计算的。学习速率(eps_k)决定了算法沿着梯度的步长的大小(在最小化的情况下为反方向,在最大化的情况下为正方向)。
学习速率是迭代k的函数,是一个最重要的超参数。一个过高的学习速率(例如> 0.1)会导致参数更新失去最优值,学习速率太低(例如< 1e-5)会导致不必要的长时间的训练。一个好的策略是开始的学习速率为1e-3,并使用一个学习速率表,将学习速率降低为一个迭代函数(例如,一个每4个周期将学习速率减半的步长调度程序):
一般来说,我们需要学习速率(eps_k)要满足Robbins-Monroe条件:

Nesterov和标准动量之间的差异是梯度被评估的地方,Nesterov的动量是在应用了当前速度后对梯度进行评估,因此Nesterov的动量增加了梯度的校正系数。
AdaGrad是一种设置学习速率的自适应方法。考虑下图中的两个场景。
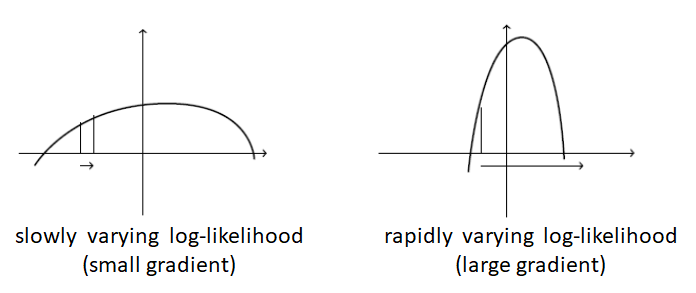
在缓慢变化的目标(左)的情况下,梯度通常(大多数点)小幅度变化。因此,我们需要一个大的学习速率来快速达到最优。在一个快速变化的目标(右)的情况下,梯度通常是非常大的。使用一个大的学习率会导致很大的步长,来回摆动,但不能达到最优。
这两种情况发生是因为学习速率与梯度无关。AdaGrad通过积累到目前为止的梯度的平方标准,并将学习速率除以这个和的平方根来解决这个问题:
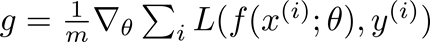

获得高梯度的参数将会降低有效的学习速率,而接收小梯度的参数将会提高有效的学习速率。净效应是在更平缓的参数空间方向上取得更大的进展,在存在较大的梯度时更加谨慎的更新。
RMSProp通过将梯度积累改变成指数加权移动平均,从而改变AdaGrad:
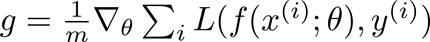
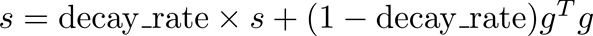
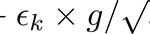
注意,AdaGrad意味着,即使梯度在训练开始时积累了梯度,其学习速率也会降低。通过引入指数加权移动平均,我们将最近的过去与遥远的过去进行比较。因此,RMSProp被证明是一种有效的、实用的深度神经网络优化算法。
Adam算法来源于“适应性时刻(adaptive moments)”,它可以被视为RMSProp和动量组合的一种变体,更新后看起来像RMSProp除了用梯度的平稳版本代替原始随机梯度,完整的Adam算法更新还包括一个偏差纠正机制:
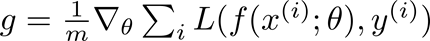
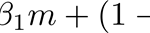
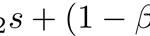
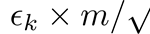
推荐值为beta_1 = 0.9,beta_2 = 0.999,eps = 1e-8。
使用TensorFlow以1e-3的学习速率和交叉熵损失对MNIST数据集上的简单CNN架构进行训练。使用了四种不同的优化器:SGD、Nesterov动量、RMSProp和Adam算法。下图显示了训练损失和迭代的值:
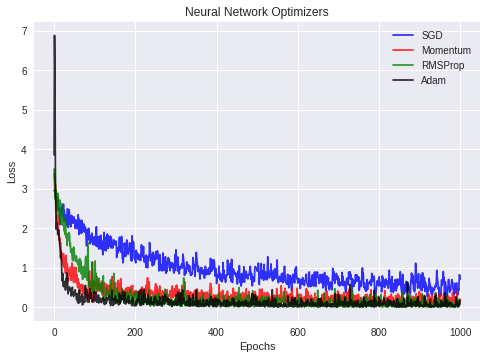
从图中可以看出,Adam算法和Nesterov动量优化器产生了最低的训练损失。
代码地址为:https://github.com/vsmolyakov/experiments_with_python/blob/master/chp03/tensorflow_optimizers.ipynb
我们比较了在训练神经网络中使用的不同的优化器,并对它们的工作原理有了直观的认识。我们发现,使用Nesterov Momentum和Adam算法的SGD在TensorFlow中的MNIST数据上训练一个简单的CNN时产生最好的结果。
随机梯度下降(SGD)
SGD通过选取大小(m)的子集或小批量数据,更新在梯度(g)的反方向上的模型参数(g):
神经网络由 f(x(i); theta)表示;其中x(i)为训练数据,y(i)为训练标签,损失L的梯度是根据模型参数theta计算的。学习速率(eps_k)决定了算法沿着梯度的步长的大小(在最小化的情况下为反方向,在最大化的情况下为正方向)。
学习速率是迭代k的函数,是一个最重要的超参数。一个过高的学习速率(例如> 0.1)会导致参数更新失去最优值,学习速率太低(例如< 1e-5)会导致不必要的长时间的训练。一个好的策略是开始的学习速率为1e-3,并使用一个学习速率表,将学习速率降低为一个迭代函数(例如,一个每4个周期将学习速率减半的步长调度程序):
def step_decay(epoch):
lr_init = 0.001
drop = 0.5
epochs_drop = 4.0
lr_new = lr_init * \
math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lr_new
一般来说,我们需要学习速率(eps_k)要满足Robbins-Monroe条件:
第一个条件确保算法能够找到一个局部最优解,不管起点和第二个控制振荡。
动量
动量积累了指数衰减的过去的渐变移动平均线,并继续朝着它们的方向移动:
![]()
![]()
Nesterov和标准动量之间的差异是梯度被评估的地方,Nesterov的动量是在应用了当前速度后对梯度进行评估,因此Nesterov的动量增加了梯度的校正系数。
AdaGrad
AdaGrad是一种设置学习速率的自适应方法。考虑下图中的两个场景。
在缓慢变化的目标(左)的情况下,梯度通常(大多数点)小幅度变化。因此,我们需要一个大的学习速率来快速达到最优。在一个快速变化的目标(右)的情况下,梯度通常是非常大的。使用一个大的学习率会导致很大的步长,来回摆动,但不能达到最优。
这两种情况发生是因为学习速率与梯度无关。AdaGrad通过积累到目前为止的梯度的平方标准,并将学习速率除以这个和的平方根来解决这个问题:
获得高梯度的参数将会降低有效的学习速率,而接收小梯度的参数将会提高有效的学习速率。净效应是在更平缓的参数空间方向上取得更大的进展,在存在较大的梯度时更加谨慎的更新。
RMSProp
RMSProp通过将梯度积累改变成指数加权移动平均,从而改变AdaGrad:
注意,AdaGrad意味着,即使梯度在训练开始时积累了梯度,其学习速率也会降低。通过引入指数加权移动平均,我们将最近的过去与遥远的过去进行比较。因此,RMSProp被证明是一种有效的、实用的深度神经网络优化算法。
Adam算法
Adam算法来源于“适应性时刻(adaptive moments)”,它可以被视为RMSProp和动量组合的一种变体,更新后看起来像RMSProp除了用梯度的平稳版本代替原始随机梯度,完整的Adam算法更新还包括一个偏差纠正机制:
推荐值为beta_1 = 0.9,beta_2 = 0.999,eps = 1e-8。
实验
使用TensorFlow以1e-3的学习速率和交叉熵损失对MNIST数据集上的简单CNN架构进行训练。使用了四种不同的优化器:SGD、Nesterov动量、RMSProp和Adam算法。下图显示了训练损失和迭代的值:
从图中可以看出,Adam算法和Nesterov动量优化器产生了最低的训练损失。
代码
代码地址为:https://github.com/vsmolyakov/experiments_with_python/blob/master/chp03/tensorflow_optimizers.ipynb
结论
我们比较了在训练神经网络中使用的不同的优化器,并对它们的工作原理有了直观的认识。我们发现,使用Nesterov Momentum和Adam算法的SGD在TensorFlow中的MNIST数据上训练一个简单的CNN时产生最好的结果。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消