











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






嵌入式深度学习:从云端到设备
2017年11月24日 由 yining 发表
78615
0
导语:苹果的人脸识别标志着嵌入式人工智能第二阶段的开始,在这一阶段,更多的智能发生在独立于云的设备上。但它们并不是唯一的选择。
大多数的智能都发生在云服务器上。苹果的新生物认证系统,使用由传感器数组和一个AI加速的iPhone SoC芯片组成的面部识别系统,标志着第二阶段的嵌入式人工智能会发生在更多的智能设备和独立的云端上。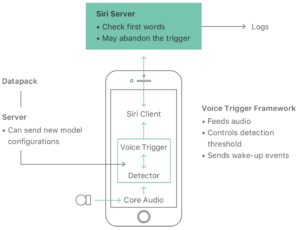
要实现这一目标,需要将深度学习软件和嵌入式硬件混合在一起,以高效、快速地执行重复并行算法。
正如之前所描述的,由于GPU硬件性能的大幅提升,深度学习算法正被应用于越来越多的商业应用中,包括网络安全、物流、数据保护和质量控制。
然而,
直到最近,这样的复杂性将大量的学习计算都交给了拥有大量GPU加速器的高能耗服务器领域。然而,半导体流程集成和算法开发方面的进步,现在甚至允许移动设备执行像图像标记、生物认证和机器人控制这样的非平凡任务。
和其他公司一样,苹果一直在使用基于云的系统来进行图像识别。为了增强用户隐私,苹果想要加密手机上的照片,这意味着只有那些来自用户的iCloud账户可以在云中进行解密处理,因此需要运行设备内置的图像识别算法。
上面提到的论文描述了苹果是如何在有限的内存和CPU资源的情况下工作的,而且不会干扰其他操作系统的任务,并使用额外的功能。此外,这篇论文还详细介绍了苹果如何为一个大型的GPU调整深度学习模式,并得出结论:
苹果的研究是为了应对其新面部识别身份验证技术所带来的计算挑战。该技术是一种生物识别安全系统,使用前置红外摄像头来拍摄3万个光点,以创建一个红外图像和一张用户脸部的3D地图。苹果对该实现的描述很少,但表明A11 SoC的新特性的使用了,
在另一篇最近发表的论文中,iPhone还使用了深度神经网络(DNN)来识别和解析语音指令的“Hey Siri”功能。
处理需要不断地侦听和检测所谓的“唤醒词”。因此,iPhone使用了一个低功耗的辅助装置Always On Processor (AOP)来触发Siri的激活。但是,正如论文所描述的,一旦触发,AOP就会唤醒主处理器,用更大的深度神经网络(DNN)来分析声音。
App开发者还可以通过其核心的API和开发工具的核心机器学习框架来使用iPhone硬件的神经网络加速功能。在一篇教程中,介绍了应用程序可以使用CoreML和iOS成像软件开发工具包来完成形状识别和对象识别等任务。
ARM,谷歌,微软等公司也将人工智能带到了设备上
ARM是由苹果授权和定制的处理器平台的开发者,并被其他所有移动设备使用。该公司将人工智能引入其通用的SoC设计,此举将显著扩大人工智能加速设备的扩散。
这款名为DynamicIQ的设计添加了处理器指令,用于加速机器/深度学习算法,ARM预计在未来的3-5年里,人工智能相对于当前的系统的性能将增加50倍。
一些公司已经在使用低功率的ARM-M处理器来进行嵌入式机器学习应用。例如, Amiko Respiro(一种为哮喘患者提供的吸入器),它使用来自几个传感器和机载ML软件的数据来计算药物的有效性,并开发针对每个病人的治疗方法。
微软还在开发可以安装在移动设备和物联网设备上的嵌入式机器学习软件。该研究目前专注于针对特定场景的利基应用(niche application)上,比如嵌入式医疗设备或智能工业传感器。
另一家公司,Reality AI提供了为嵌入式传感器和设备设计的机器学习软件库。虽然硬件适用于这样的小并恶劣的环境,但还不能支持ML加速器,随着时间的推移,这种技术将会缩小,并允许这样的设备支持更复杂、更准确的人工智能模型。
我的看法
人工智能发展的下一个阶段是将深度学习算法从云端引入到现实世界中,无论是移动电话、工业传感器还是医疗设备。
虽然最初的努力很自然地专注于将现有的机器学习/深度学习模型缩小到移动设备有限的处理器和内存占用,但未来的实现将使用移动SoC为人工智能加速器增加晶体管预算。
硬件和软件创新的结合将极大地提高嵌入式人工智能软件的能力,并促进跨行业的创新应用。如果你的企业使用或构建移动或物联网软件,那么是时候开始规划智能、自主学习和自主校正应用了。
“健谈”的智能助手已经成为消费设备的标配,比如手机和智能手表。这些都是人工智能在日常生活中加速渗透的预兆。虽然吸引人,但当前的实现是对未来的苍白模仿。
大多数的智能都发生在云服务器上。苹果的新生物认证系统,使用由传感器数组和一个AI加速的iPhone SoC芯片组成的面部识别系统,标志着第二阶段的嵌入式人工智能会发生在更多的智能设备和独立的云端上。
要实现这一目标,需要将深度学习软件和嵌入式硬件混合在一起,以高效、快速地执行重复并行算法。
正如之前所描述的,由于GPU硬件性能的大幅提升,深度学习算法正被应用于越来越多的商业应用中,包括网络安全、物流、数据保护和质量控制。
然而,
这种算法的问题在于,它们是贪婪的数据消费者,对复杂性有偏见——数据集越大,计算方法越密集,结果就越准确和有用。对于英伟达(Nvidia)来说,这是一个很好的问题,因为该公司专门开发用于解决并行复杂性的硬件。因此,GTC(图形处理器技术大会)每年的主题更多的都与业务有关。
直到最近,这样的复杂性将大量的学习计算都交给了拥有大量GPU加速器的高能耗服务器领域。然而,半导体流程集成和算法开发方面的进步,现在甚至允许移动设备执行像图像标记、生物认证和机器人控制这样的非平凡任务。
为人工智能设计的iPhone
2010年,苹果首次在iPad和iPhone 4中使用A4处理器。自开始设计定制的SoC以来,苹果公司一直为移动设备性能设定了标准。今年的A11仿生芯片,保持了每年两位数的性能增长趋势,它是第一个设计用于加速神经网络算法在深度学习中的应用。尽管苹果在设计细节上是秘密的(也可以理解),但它确实揭示了,
新的A11仿生神经引擎是一种双核心设计,每秒钟可执行高达6000亿次的实时处理。A11仿生神经引擎是为特定的机器学习算法设计的,它可以使人脸识别、Animoji和其他功能有效。
这两种“其他功能”包括照片标签和苹果语音助手Siri,以及该公司最近在几篇研究论文中提供的细节。
苹果公司的研究人员在一篇有关“人脸检测的深度神经网络”的论文中指出,去年iOS 10首次开始使用深度学习技术,在iOS 10中,它必须解决甚至是高端手机在深度学习算法方面的局限。
和其他公司一样,苹果一直在使用基于云的系统来进行图像识别。为了增强用户隐私,苹果想要加密手机上的照片,这意味着只有那些来自用户的iCloud账户可以在云中进行解密处理,因此需要运行设备内置的图像识别算法。
上面提到的论文描述了苹果是如何在有限的内存和CPU资源的情况下工作的,而且不会干扰其他操作系统的任务,并使用额外的功能。此外,这篇论文还详细介绍了苹果如何为一个大型的GPU调整深度学习模式,并得出结论:
综合起来,所有这些策略都能确保我们的用户在不知道他们的手机每秒能运行几百千兆次的神经网络的情况下,能够享受到本地的、低延迟的、私密的深度学习推断。
苹果的研究是为了应对其新面部识别身份验证技术所带来的计算挑战。该技术是一种生物识别安全系统,使用前置红外摄像头来拍摄3万个光点,以创建一个红外图像和一张用户脸部的3D地图。苹果对该实现的描述很少,但表明A11 SoC的新特性的使用了,
A11仿生芯片的神经引擎的一部分——在安全的区域内受到保护——将深度地图和红外图像转换为数学表示,并将该表示与已登记的面部数据进行比较。注意:Secure Enclave是用于加密操作和存储的A系列芯片的嵌入式协处理器,该芯片只能用于操作系统。
在另一篇最近发表的论文中,iPhone还使用了深度神经网络(DNN)来识别和解析语音指令的“Hey Siri”功能。
处理需要不断地侦听和检测所谓的“唤醒词”。因此,iPhone使用了一个低功耗的辅助装置Always On Processor (AOP)来触发Siri的激活。但是,正如论文所描述的,一旦触发,AOP就会唤醒主处理器,用更大的深度神经网络(DNN)来分析声音。
App开发者还可以通过其核心的API和开发工具的核心机器学习框架来使用iPhone硬件的神经网络加速功能。在一篇教程中,介绍了应用程序可以使用CoreML和iOS成像软件开发工具包来完成形状识别和对象识别等任务。
ARM,谷歌,微软等公司也将人工智能带到了设备上
ARM是由苹果授权和定制的处理器平台的开发者,并被其他所有移动设备使用。该公司将人工智能引入其通用的SoC设计,此举将显著扩大人工智能加速设备的扩散。
这款名为DynamicIQ的设计添加了处理器指令,用于加速机器/深度学习算法,ARM预计在未来的3-5年里,人工智能相对于当前的系统的性能将增加50倍。
一些公司已经在使用低功率的ARM-M处理器来进行嵌入式机器学习应用。例如, Amiko Respiro(一种为哮喘患者提供的吸入器),它使用来自几个传感器和机载ML软件的数据来计算药物的有效性,并开发针对每个病人的治疗方法。
谷歌也不甘示弱,通过引入TensorFlow Lite铺平了深度学习算法在移动和嵌入式设备的道路,TensorFlow Lite是一个被设计用来快速启动TensorFlow模型的平台,它能够适应移动设备的小内存占用和利用任何加速硬件,像是嵌入式GPU。开发框架还具有可以在可用时自动使用设备硬件加速器的接口。
微软还在开发可以安装在移动设备和物联网设备上的嵌入式机器学习软件。该研究目前专注于针对特定场景的利基应用(niche application)上,比如嵌入式医疗设备或智能工业传感器。
另一家公司,Reality AI提供了为嵌入式传感器和设备设计的机器学习软件库。虽然硬件适用于这样的小并恶劣的环境,但还不能支持ML加速器,随着时间的推移,这种技术将会缩小,并允许这样的设备支持更复杂、更准确的人工智能模型。
我的看法
人工智能发展的下一个阶段是将深度学习算法从云端引入到现实世界中,无论是移动电话、工业传感器还是医疗设备。
虽然最初的努力很自然地专注于将现有的机器学习/深度学习模型缩小到移动设备有限的处理器和内存占用,但未来的实现将使用移动SoC为人工智能加速器增加晶体管预算。
硬件和软件创新的结合将极大地提高嵌入式人工智能软件的能力,并促进跨行业的创新应用。如果你的企业使用或构建移动或物联网软件,那么是时候开始规划智能、自主学习和自主校正应用了。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消